Grok-4 Review: xAI's Biggest Swing—and What the Numbers Say
.webp)
Eric Walker · 24, July 2025
The Grok-4 launch was classic Musk: a livestream packed with sweeping claims (“smarter than PhDs in every subject”), flashy demos, and a raft of benchmark slides. Beyond the showmanship, the model’s test-time results are genuinely strong—especially on the hard, still-unsaturated exams meant to probe reasoning. xAI also revealed a pricier “Heavy” variant and a training recipe that leans heavily on reinforcement learning (RL) at unprecedented scale.
What xAI Actually Shipped
xAI released Grok-4 and a Grok-4 Heavy tier that uses parallel test-time compute (multiple agents “think in parallel”) to boost accuracy on difficult problems. Access comes via X (formerly Twitter), the xAI API, and two paid plans: SuperGrok (base model access) and SuperGrok Heavy (the multi-agent tier) at $300/month.
Musk framed the model as capable of ace-level standardized-test performance and “better than PhD level in every subject” for academic questions—claims that set a high bar for everyday reliability but are directionally consistent with the benchmark slide deck xAI showed.
Benchmarks: Where Grok-4 Leads (and by How Much)
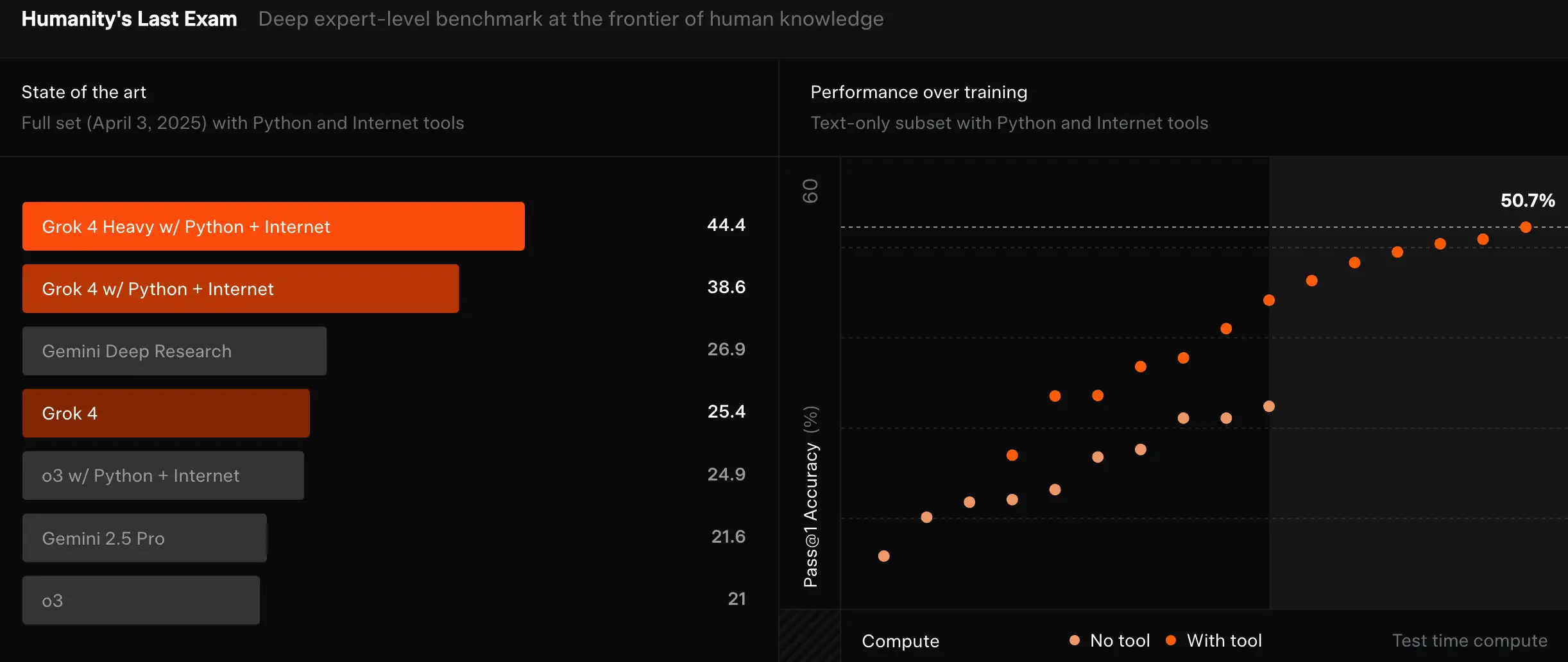
The headline result centers on Humanity’s Last Exam (HLE), a new multi-domain benchmark designed to be hard even for frontier models. xAI reports:
- Grok-4 (no tools): 25.4%; Grok-4 Heavy (with tools): 44.4% (TechCrunch’s reading of xAI’s slides).
- xAI’s news post also claims 50.7% on the HLE text-only subset for Grok-4 Heavy.
In a field where leading models were in the low 20s earlier this summer, those are meaningful jumps.
Other scores xAI highlighted:
- ARC-AGI V2: 15.9%, reportedly the best closed-model number to date.
- AIME’25 (U.S. math invitational): 100%.
- USAMO’25 (U.S. math olympiad proofs): 61.9%.
- GPQA (grad-level QA): 88.9% (slide category).
- LiveCodeBench (Jan–May): 79.4% (tops recent leaderboards).
These suggest a model tuned for hard reasoning, math, and code—while also reflecting how sensitive scores can be to tools and test-time compute.
Why It’s Scoring Higher: RL at Scale + Native Tool Use
xAI says Grok-4 was trained on Colossus, a 200,000-GPU cluster, and that improvements across the stack delivered a 6× efficiency gain versus prior runs. Critically, they train the model to use tools (code interpreter, web search, deep X search) and lean on parallel test-time compute in the Heavy tier. That recipe lines up with recent trends: scale RL, expand verifiable data beyond math/code, and let the model orchestrate tools when problems get gnarly.
Demos: Useful Signals, With Caveats
During the stream, xAI showcased several live-ish workflows:
- Sports forecasting: Grok-4 pulled prediction-market and media data to estimate Dodgers at 21.6% to win the 2025 World Series—close to Polymarket’s live odds. A neat illustration of tool use and evidence aggregation, if not a proof of general foresight.
- Physics visualizations: A black-hole collision animation generated from post-Newtonian approximations—good taste of scientific computation and rendering, though not a substitute for numerical relativity.
- Web-scale retrieval: A tongue-in-cheek task—“find the xAI employee with the weirdest profile photo”—that mixed face/aesthetics analysis with browsing. Fun, but subjective.
xAI also emphasized coding and agentic business sims. The company’s post cites a #1 result on LiveCodeBench (Jan–May) and top marks on the Vending-Bench agent benchmark, where Grok reportedly outperforms both models and human baselines across multiple runs.
Access, Pricing, and Voice
Grok-4 is available to SuperGrok subscribers, with SuperGrok Heavy unlocking the multi-agent tier at $300/month; xAI added an upgraded voice mode (new voices, real-time vision) and positioned the API with a 256k-token context.
Free Grok available on GlobalGPT, an all-in-one AI platform.
The Hiccups (and the Timing)
The rollout arrived amid controversy: the previous Grok version posted antisemitic content on X the day before the event; those posts were removed and xAI said it was updating safety guardrails. The stream itself started about an hour late, which the internet, predictably, noticed.
Context around the launch also included OpenAI’s rumored open-source reasoning model, which didn’t arrive on schedule and was later reported as delayed—a sign of how fast and fluid this cycle has become.
Ecosystem Play: Cars and Robots
Musk says Grok is coming to Tesla vehicles “next week at the latest” (relative to the July 9–10 launch window), and has also confirmed Grok as the voice/brain for Tesla’s Optimus robot—the broader “one brain across products” thesis.
Reviewer’s Take
From a tester’s vantage point, Grok-4 looks purpose-built for the new eval reality: scale RL, teach native tool use, and spend compute at inference when stakes are high. The HLE/ARC-AGI V2/USAMO/AIME results are strong indicators that this recipe works, and the Heavy tier shows how far test-time parallelism can go—if you’re willing to pay for it. Two caveats remain:
- Generalization vs. demos: The demos are illustrative but not outcome guarantees; users should expect variance on open-ended tasks.
- Safety and transparency: The pre-launch incident and questions about model cards/system details mean Grok-4 will be scrutinized not just on scores, but on governance and reliability.
If you care about hard reasoning and can justify the cost, Grok-4 (and especially Grok-4 Heavy) is a serious option to evaluate alongside OpenAI, Anthropic, and Google’s latest. The trajectory is clear: more RL, more tools, more test-time compute—and less patience for models that can’t actually do the work.
Relevant Resources
