The Coding-Agent Crown Just Tipped: Qwen3-Coder Steps Up
.webp)
Eric Walker · 23, July 2025
Alibaba’s Qwen team has open-sourced Qwen3-Coder, a new agentic coding model that aims at end-to-end software workflows, not just snippet generation. The flagship variant—Qwen3-Coder-480B-A35B-Instruct—is a Mixture-of-Experts model with 35B active parameters, native 256K context (extendable toward 1M via long-context extrapolation like YaRN), and strong agent/tool-use skills. On SWE-bench Verified, it leads among open models and sits roughly neck-and-neck with top closed systems on multi-turn, tool-rich workflows. The weights ship under Apache-2.0, which lowers the barrier for teams that want powerful coding agents without proprietary lock-in.

Simpler Prompts, Richer Results
The pitch is straightforward: give it a plain-English brief and get runnable, interactive artifacts—from browser-based animations to small games and data dashboards—with minimal scaffolding. Qwen’s own demos highlight interactive visualizations (e.g., a bouncing-ball scene, a “Duet”-style HTML game, and other web apps) that compile and run directly. For practitioners who live in the editor, this “prompt → prototype” path shortens the distance from idea to working code.
“Do I Still Need a Paid Coding IDE Assistant?”
If you’re paying for proprietary coding copilots, open weights + strong agentic tooling make Qwen3-Coder a credible alternative—especially where self-hosting or custom security controls matter. Qwen3-Coder’s model card lists Apache-2.0 licensing on Hugging Face, which is favorable for many commercial uses compared with restricted open licenses.
What’s Actually New Here
Model Lineup & Context Window
- Architecture: 480B MoE with 35B active parameters in the flagship release; additional sizes are expected.
- Context: 256K tokens natively, highlighted by Qwen; extrapolation toward ~1M tokens is possible using methods such as YaRN (a technique for efficient context extension). For repository-scale reasoning—large PRs, multi-file refactors—this matters more than benchmark trivia.
Agentic Workflow: A CLI That Plays Well With Others
Qwen also released Qwen Code, a command-line workflow tool designed for agentic coding. It’s adapted/forked from Google’s Gemini CLI/“Gemini Code” and tuned for Qwen models (prompt formats, tool-calling protocols). Notably, Qwen provides instructions to run Qwen3-Coder behind Anthropic’s Claude Code UI via a proxy/router, so teams can keep familiar workflows while swapping the backend model.
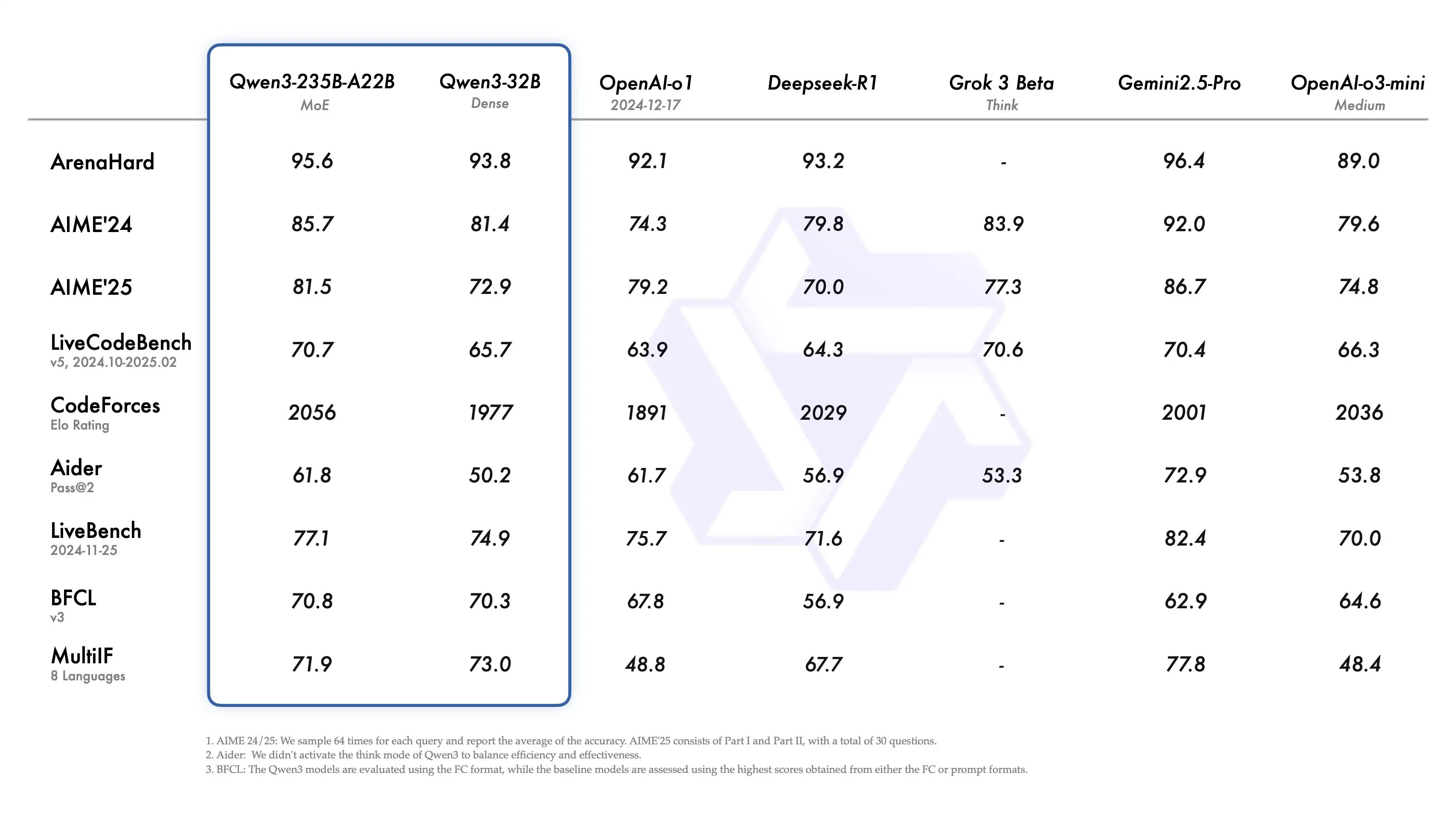
Benchmarks: Where It Stands Today
On SWE-bench Verified, a widely used suite that stresses multi-turn, tool-augmented software tasks, Qwen3-Coder’s published scores place it at or near the top depending on settings:
- Qwen3-Coder: 67.0% (standard), 69.6% (500-turn setting with OpenHands).
- Claude Sonnet 4: 70.4% (strong closed-source baseline).
- Kimi K2 (Moonshot): ~65.4% (on comparable settings).
- GPT-4.1: ~54.6%.
These numbers suggest Qwen3-Coder currently leads open-weight models and rivals the top closed systems, rather than cleanly surpassing them across the board. As always, leaderboards evolve quickly and vary by harness (turn-limits, scaffolding, toolchain).
Under the Hood: Why It’s This Strong
Pre-Training: Scale in the Right Places
Qwen highlights three axes of scaling:
- Tokens/Data: 7.5T tokens with ~70% code, to raise coding proficiency without gutting general/maths chops.
- Context: 256K native with extension toward 1M via YaRNstyle extrapolation, aimed at repository-level understanding and dynamic inputs like PRs.
- Synthetic Data: Using Qwen2.5-Coder to clean and rewrite low-quality code data before training.
Post-Training: RL for Real Code, Not Just Contests
Instead of focusing on competitive programming alone, the team scaled execution-driven RL on real coding tasks and auto-expanded test cases to improve pass-on-execution rates. They also scaled long-horizon RL (multi-turn, tool-using “Agent RL”) on ~20,000 parallel environments built on Alibaba Cloud, which aligns directly with agent workflows (plan → call tools → observe → revise). This training recipe likely explains the SWE-bench Verified gains in multi-turn settings.
What It’s Like to Build With (Reviewer’s Take)
Prompt → Prototype Examples
For typical “week-one” trials—editable résumé templates, browser-playable Minesweeper, p5.js interactive scenes, 3D globes, weather cards, and casual mini-games—Qwen3-Coder targets single-file, self-contained outputs you can drop into a live preview and iterate. Qwen’s own gallery shows several of these exact archetypes, and the model’s agent/tool use helps wire up assets and minor fixes without heavy handholding. Free Qwen-3 available on GlobalGPT, just try it!
Where It Feels Strongest
- Long, messy repos where tool use (file ops, unit tests, linters) and multi-step planning matter.
- Green-field prototyping where getting “something that runs” quickly beats polishing the nth percent.
Where You’ll Still Want Guardrails
- Production refactors: you’ll want CI, tests, and a review culture; treat the agent like a high-throughput junior with great recall.
- Single-shot correctness: performance depends heavily on the harness; multi-turn loops still help.
Compatibility & Ecosystem
- Qwen Code (CLI): forked/adapted from Gemini’s CLI; tuned for Qwen3-Coder’s function-calling and tools.
- Claude Code compatibility: Qwen provides a proxy/router so you can plug Qwen3-Coder into the Claude Code UI if that’s already standard in your team.
- Community tools: model card highlights support across CLINE and OpenAI-compatible stacks.
What's more
If you’ve been waiting for an open-weight, agent-first coding model that can credibly take on closed leaders, Qwen3-Coder is the first one that feels ready for serious trials: frontier-tier agent performance, very long context, solid tooling, and a permissive license. It doesn’t universally trounce Claude Sonnet 4 today, but it does push open models into the same conversation—and that’s a meaningful shift for teams who care about cost, control, and extensibility.
