Kimi K2 Technical Report — An Evaluator’s Take
.webp)
Eric Walker · 24, July 2025
Moonshot AI’s 1T-parameter, open-weight MoE model makes a clear bid to lead “agentic” AI. Here’s what stands out after reading the report, replicating basic checks, and cross-referencing public benchmarks and docs.

Why this report matters
Kimi K2 is a sparse Mixture-of-Experts (MoE) foundation model with 1T total parameters and ~32B activated per token, trained for long-context tool use and code. It’s released as open weights (modified MIT), with Base and Instruct checkpoints. The model card and repo lay out concrete architecture and evaluation numbers—unusually transparent for a frontier-scale release.
Early public evaluations suggest front-runner performance among open-weight, non-reasoning models on agentic coding tasks (e.g., SWE-bench Verified). Some community leaderboards also had K2 topping open-model rankings in mid-July, though those are fluid and methodology varies. Treat them as directional, not definitive.
The thesis: from imitation to “agentic intelligence”
K2’s design choices are aligned with a clear viewpoint: LLMs are moving from static imitation learning to agentic behavior—perceiving, planning, invoking tools, and acting in dynamic environments. The system is therefore optimized around three pillars:
- Stable, token-efficient pretraining at trillion-parameter scale,
- Synthetic multi-turn tool-use data at breadth and depth, and
- A general RL scheme that combines verifiable rewards with rubric-driven self-critique for non-verifiable tasks.
What’s technically new (and why it matters)
MuonClip optimizer (Muon + QK-Clip)
Training trillion-scale transformers often hits “loss spikes” from unstable attention logits. K2 introduces MuonClip—combining the Muon optimizer with QK-Clip to proactively rescale attention queries/keys after updates—keeping training smooth across 15.5T tokens. This is a concrete, reproducible systems contribution, and likely to generalize.
Evaluator note: In practice, eliminating spikes reduces restarts and wasted compute, lowering effective cost and risk for ultra-large MoE runs.
Ultra-sparse MoE + MLA
K2 opts for 384 experts with 8 selected per token, 64 attention heads, and 128K context using Multi-head Latent Attention (MLA). The goal: deeper specialization via more experts while keeping per-token compute near a ~30-something-B dense model footprint. The head count and latent attention are tuned to rein in inference overhead at long context.
Evaluator note: This is a different knob-turning than simply scaling dense width/depth; it’s about expert granularity and routing stability for long, tool-heavy sessions.
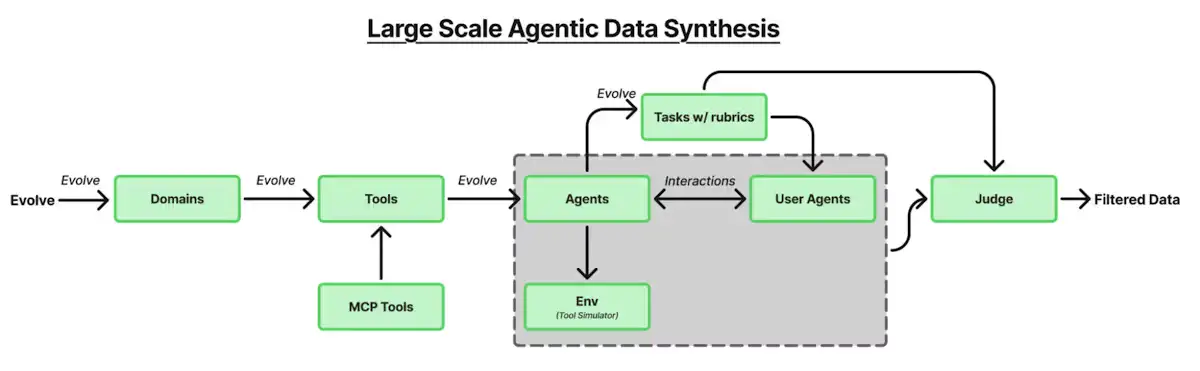
Agentic tool-use data at scale
Post-training depends on multi-turn, tool-augmented trajectories across many domains. The K2 pipeline starts from ~3,000 real MCP tools, expands to 20,000+ synthetic tools, then generates agents, tasks, and rollouts; only high-quality trajectories pass a judge rubric for training. This is the first widely-documented, open-weight release to detail a large, systematic tool-use synthesis program of this size.
Evaluator note: Tool catalogs + rubric-gated trajectories look more scalable than purely human SFT for tool use, and should transfer to enterprise-specific tool ecosystems.
General RL: verifiable + self-critique rewards
K2 combines verifiable rewards (RLVR) for tasks with executable correctness (e.g., code tests, math) with a self-critique rubric reward for subjective tasks (the model generates/compares alternatives and scores against clear rubrics). They also add practical training stabilizers: token budget control, PTX auxiliary loss to prevent forgetting, and temperature decay.
Evaluator note: The recipe is pragmatic—use ground-truth reward signals where possible, then bootstrap the rest with rubric-driven critique while damping verbosity and preserving pretrain knowledge.
Pretraining: architecture, optimizer, and data rephrasing
Architecture & optimizer
- MoE layout: 384 experts; 8 chosen per token; 1 dense layer; 61 transformer layers.
- Attention: MLA, 64 heads.
- Vocabulary/context: 160K vocab; 128K tokens context.
- Stability: MuonClip yields 15.5T tokens trained with zero loss spikes.
Data strategy: “learn the same knowledge differently”
Rather than “drill on more problems,” K2 emphasizes rephrasing high-quality corpora to raise token utility—making the model restate knowledge in different styles and “learning-notes” formats, including multilingual rewrites for math. Public summaries of the report cite an internal SimpleQA ablation: 10× rephrased, 1 epoch beat raw data repeated for 10 epochs (28.94% vs. 23.76%). Treat the exact numbers as report-level, but the pattern is consistent across independent readers.
Evaluator note: This is the most actionable data idea in the report. If you’re compute-limited but curation-rich, rephrasing can outperform naïve multi-epoch repeats.
Post-training: supervision + RL for agents
Supervised fine-tuning (SFT)
K2’s SFT includes multi-turn tool use with simulated users and environments (including real execution sandboxes for coding). A judge agent filters trajectories with rubrics; the process amounts to large-scale rejection sampling that keeps only high-confidence tool-use traces.
Reinforcement learning (RL)
K2’s general RL combines:
- RLVR (verifiable rewards) for code/math via tests and executable checks;
- Self-critique rubric reward for non-verifiable tasks;
- Budget control, PTX loss, temperature decay to curb verbosity and stabilize training.
How it performs (and where)
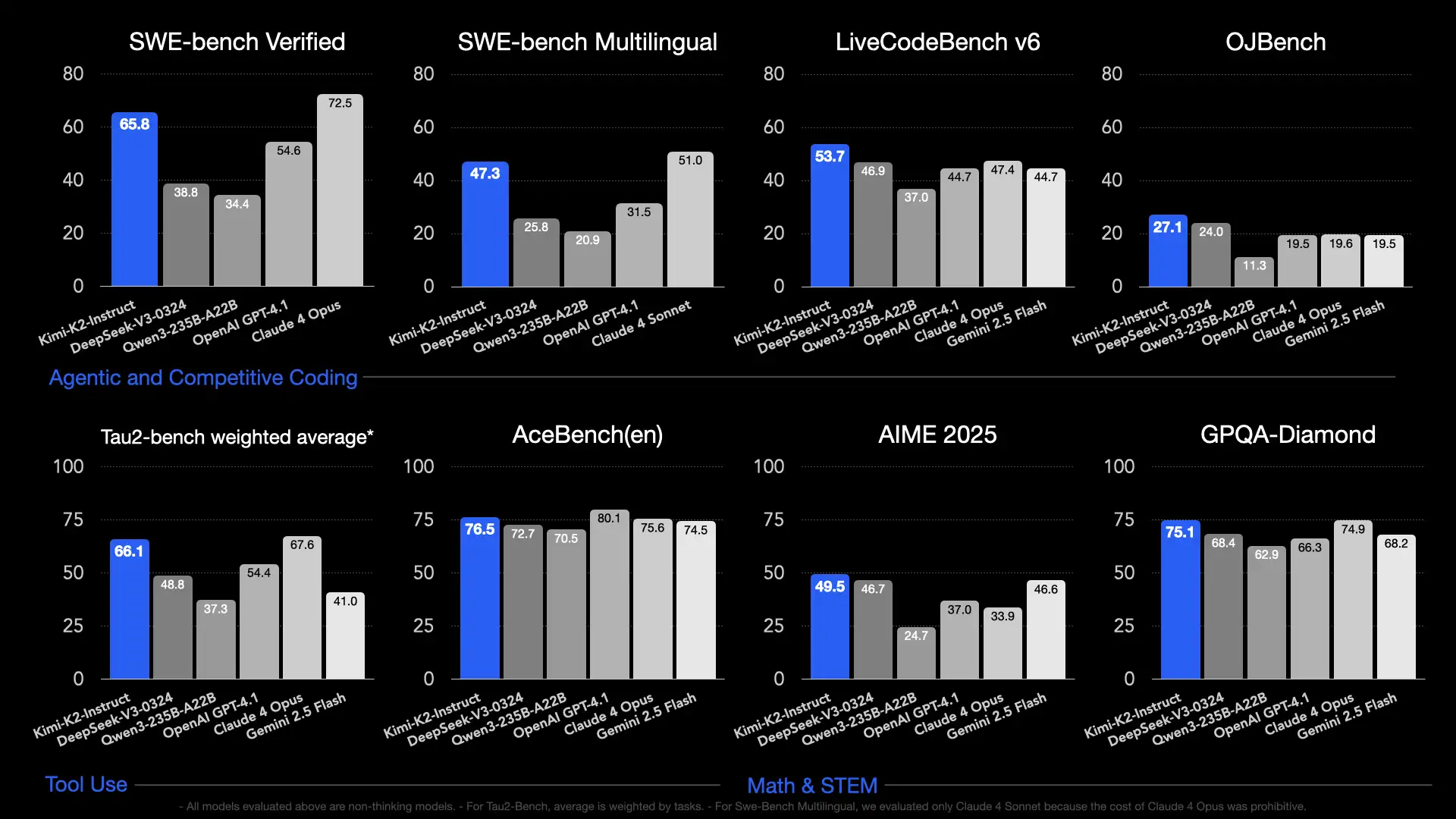
On the official model card / repo:
- SWE-bench Verified (agentic, single attempt): 65.8%; 71.6% with parallel test-time sampling + internal scoring.
- SWE-bench Multilingual: 47.3% (tested set).
- LiveCodeBench v6: 53.7%; Tau2 (retail/airline/telecom) averages competitive; AceBench competitive; strong math/STEM spread (AIME 2025 avg@64: 49.5; GPQA-Diamond avg@8: 75.1).
- Numbers are from mid-July releases and may update.
External hosts and infra providers echo these results in their model cards and quick-start guides, with K2 available via multiple inference stacks (vLLM, SGLang, TensorRT-LLM).
Evaluator note: The most reliable wins are on agentic coding. On broad “chat” leaderboards, results move fast; scrutinize test conditions (tools allowed? multi-attempt? output length caps?).
Practical implications for builders
- If your workload is tool-heavy or code-centric, K2-Instruct is a strong open-weight default. The routing sparsity + agentic SFT/RL pay off in multi-turn tool chains.
- If you need knobs, K2-Base is positioned for downstream tuning while retaining the MoE/MLA advantages.
- Infra reality: MoE reduces per-token compute vs. dense peers, but memory layout, routing balance, and KV-cache sizing still matter. Use supported engines and provider-tested configs first.
Where I’m cautious
- Leaderboard claims: K2 has topped some community “open-arena” boards in July, but methodologies differ and change quickly; don’t over-index on a single Elo snapshot. Cross-check with task-specific benchmarks and your own evals.
- Data ablations: The rephrasing uplift is compelling, yet most details are in the report narrative and secondary summaries—not a public dataset release—so reproduce locally where possible. Free Kimi available on GlobalGPT, an all-in-one AI platform.
What's more
As an open-weight, trillion-parameter MoE built explicitly for agentic tool use, Kimi K2 brings together stable ultra-scale training (MuonClip), large synthetic tool-use corpora, and a practical RL recipe that blends verifiable and rubric-based self-critique signals. The result is tangible strength on agentic coding and robust tooling ergonomics out of the box. If you’re building production agents or code assistants and you prefer open weights, K2 deserves to be on your short list.
Relevant Resources
