

快速回答: if you are searching for a ChatGPT Plus free trial, stop chasing random coupon codes. The real play is simpler: use the official Free plan first, check official student routes if you qualify, claim Codex student credits only if they fit your coding work, and compare GlobalGPT before you pay for another subscription.
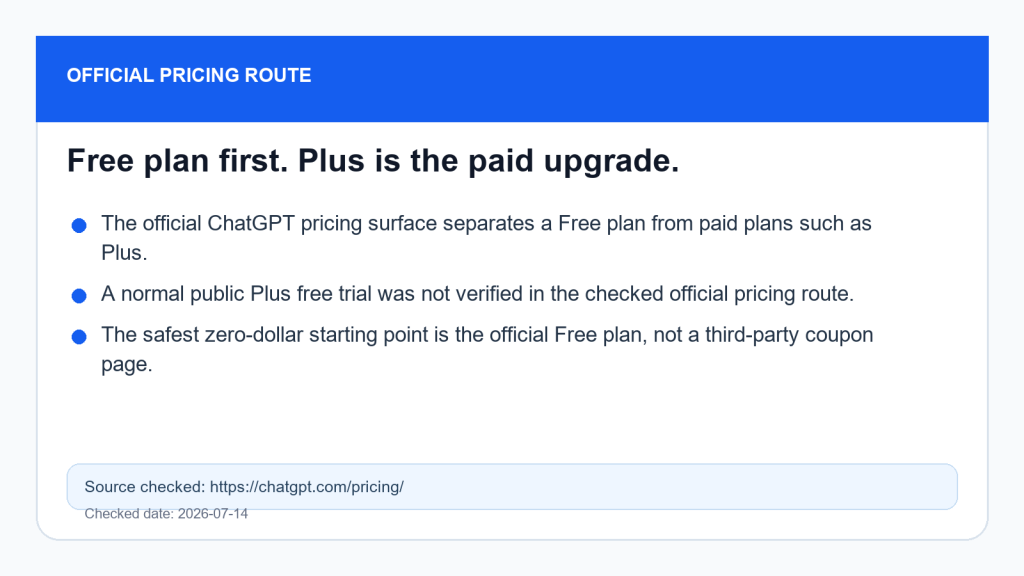
That is the honest version. A normal public ChatGPT Plus free trial is not something you should assume is always available. The official ChatGPT pricing page separates Free and paid plans. If a website promises “free Plus forever” but cannot point you to an official OpenAI route, treat it like a trap with nicer typography.
The good news is that you still have practical $0 ways to start. And if those limits get annoying, you do not have to jump straight into the subscription maze. You can compare the official route with GlobalGPT, a multi-model workspace built for users who want more AI value without paying for every tool separately.
目录

The Real Answer on ChatGPT Plus Free Trials
The phrase “ChatGPT Plus free trial” sounds perfect because it promises the paid experience without the bill. That is exactly why the search results are messy. Some pages talk about expired promos. Some package the Free plan as if it were Plus. Some push shared accounts, coupon codes, or strange “activation” steps that have nothing to do with OpenAI.
The cleaner answer is this: do not build your plan around a guaranteed public Plus trial unless you can verify it on an official OpenAI page. Start with the official Free plan. If you are a student, check the official student route. If you are doing coding work and qualify, check Codex credits. If you still need more, compare the cost of Plus against tools that give you a wider model mix.
If you want the full buying context before paying, read the ChatGPT subscription plan breakdown and the dedicated guide on 如何购买 ChatGPT Plus. If price is your main pain point, the cheaper-route guide on 如何购买更便宜的 ChatGPT Plus 是接下来更值得阅读的一本书。.
The Legitimate Free Routes That Actually Make Sense
There are three real zero-dollar routes worth checking before you pay. They are not all ChatGPT Plus. That distinction matters because it keeps you from expecting the wrong benefits from the right offer.
| 路线 | What it gives you | 最适合 | Risk level |
|---|---|---|---|
| Official ChatGPT Free plan | A real $0 way to start from the official ChatGPT product path | Basic chatting, light writing, first-time testing | 低 |
| Official student free-chat route | A student-specific offer checked through ChatGPT Students | College students who can verify eligibility | Low, if verified on the official page |
| Codex student credits | Developer credits described in the OpenAI Help Center terms | Eligible student developers and coding workflows | Low, but not a Plus subscription |
| Random Plus trial coupon page | Usually unclear, unverifiable, or expired | No one who values account safety | 高 |
| GlobalGPT | A practical multi-model alternative when official free routes are too limited | Users who want more AI capability without juggling subscriptions | Low when used as a value comparison, not as an official Plus claim |
Step-by-Step: How to Start Without Paying First
Step 1: Open the official pricing route and choose Free first
Go to the official ChatGPT pricing page. Look for the Free plan and start there if your goal is to test ChatGPT without paying. This is the boring route, which is exactly why it is safer than a coupon page promising premium access with no official support.
Use the Free plan to test your actual work: writing emails, summarizing notes, building outlines, answering study questions, or planning small projects. If your tasks are light, you may not need Plus today. If you hit limits quickly, then you have evidence that an upgrade may be worth it.
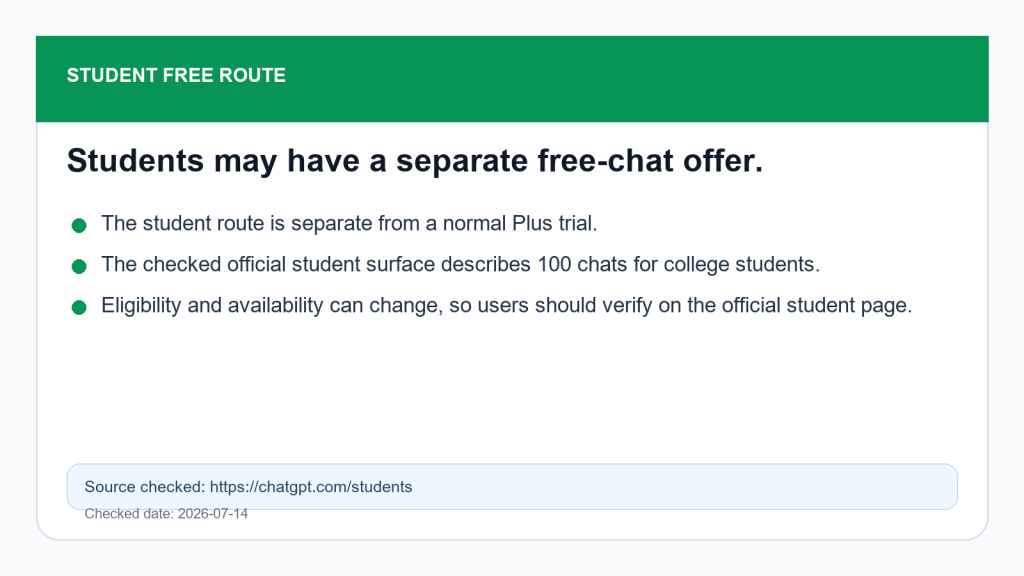
Step 2: If you are a student, check the official student page
If you are a college student, open chatgpt.com/students and verify the student offer directly. The student route is the closest match for people searching “ChatGPT Plus free trial for students,” but it should not be described as the same thing as a normal Plus subscription unless the official page says that for your account.
For more student-focused context, compare this article with GLBGPT’s guide on how to get free ChatGPT Plus for college students and the broader guide on whether ChatGPT is free for students.
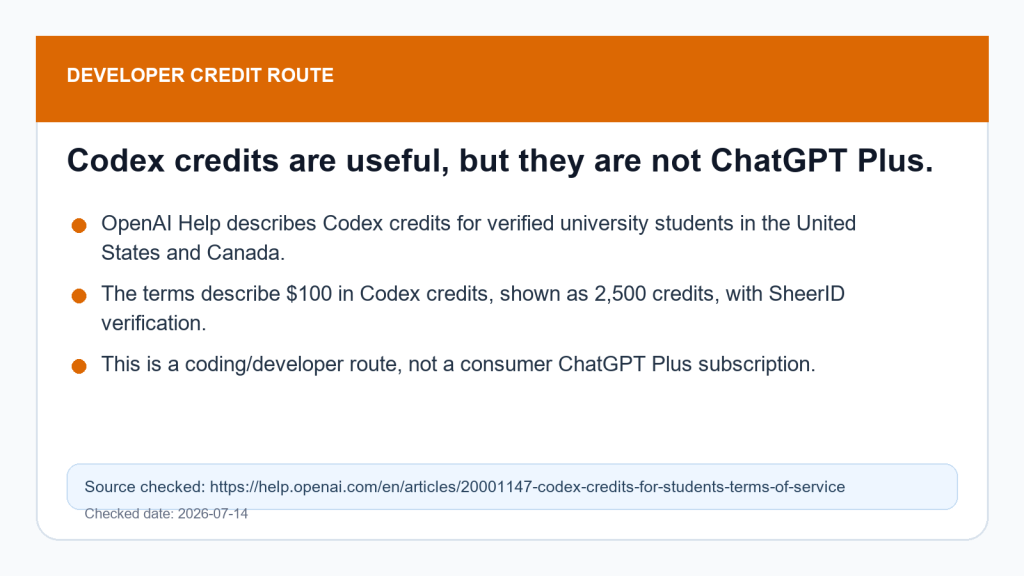
Step 3: If you code, check Codex student credits
OpenAI’s Help Center has a separate student route for Codex credits. The checked terms describe credits for verified university students in the United States and Canada, with SheerID verification. This is useful if you are building, debugging, or learning with code. It is 不 the same as ChatGPT Plus.
This is the route many people miss because they search only for “Plus trial.” If your real work is coding, a student credit route can be more relevant than a consumer Plus trial anyway. Just keep the category straight: Codex credits support developer work; Plus is a ChatGPT subscription.
Step 4: Decide whether you need Plus, Pro, or a broader workspace
After you test the free routes, ask a sharper question: do you need ChatGPT Plus specifically, or do you need stronger AI output for less friction? If the answer is “I need a better AI workflow,” compare Plus with GlobalGPT before you subscribe.
Official Plus can make sense if you want the official ChatGPT account experience. But if your work includes writing, research, coding, summarizing, comparing answers, and switching between model styles, a multi-model workspace can be more practical. That is why many users compare Plus with alternatives after reading guides like ChatGPT Plus 与 Pro 和 ChatGPT Plus vs ChatGPT Business.
Compare Every Route Before You Spend
Most bad subscription decisions happen because users compare the wrong things. They compare “free” against “paid” instead of comparing actual workflow value. A free route that blocks your work every day is not really free. A paid route that only solves one part of your workflow may be weaker than a cheaper all-in-one setup.
| 选择 | Choose it if… | Skip it if… |
|---|---|---|
| Official Free plan | You are testing ChatGPT for light tasks and want the safest $0 start. | You already know you need heavier usage, faster access, or premium workflow features. |
| Student route | You can verify eligibility and the official page shows an active offer for your account. | You are not a student, cannot verify, or need a business workflow. |
| Codex student credits | You are an eligible student developer and your main workload is coding. | You want a consumer ChatGPT Plus subscription rather than developer credits. |
| 聊天 GPT Plus | You specifically want the official ChatGPT paid account experience. | You mainly want broad model access, comparison, and lower subscription complexity. |
| GlobalGPT | You want one workspace for premium AI work without stacking separate subscriptions. | You need an official OpenAI account feature that only ChatGPT Plus provides. |
If you are price-sensitive, also check whether a ChatGPT Plus 年费套餐优惠 exists before you pay monthly. If your concern is usage caps, read the breakdown of ChatGPT Plus 限制 first. If your question is simply “what do I actually get,” the practical guide on ChatGPT Plus 能做什么 will help you decide faster.
How to Avoid Fake Plus Trial Pages
The fake-trial pattern is easy to spot once you know what to look for. The page uses urgent language, promises a trial that official pages do not mention, asks for account details too early, and hides the exact company behind the offer. A real free route should survive one simple test: can you verify it on an official OpenAI page before sharing sensitive information?
- Avoid shared account sellers. They may be cheap, but they put your privacy and access at risk.
- Avoid “activation code” pages. If the offer is real, the official route should explain how to redeem it.
- Avoid trial pages that ask for your OpenAI password. You should not hand credentials to a site that is not OpenAI.
- Avoid pages that blur Free, Plus, Pro, and Codex together. Those are different routes with different benefits.
If you still want the official paid plan after testing, use a clean purchase guide such as 如何订阅 ChatGPT Plus 或 how to upgrade to ChatGPT Plus. If payment is your problem, the guide on 如何支付 ChatGPT Plus 的费用 is more useful than another trial-code search.
When GlobalGPT Is the Smarter Paid Move
Here is the commercial truth: many people searching for a ChatGPT Plus free trial do not actually need a “trial.” They need proof that paying for AI will not become another subscription regret. That is where GlobalGPT has the better value story.
Instead of paying for one official subscription, then another model subscription, then another research tool, GlobalGPT gives you a single place to work across leading AI models. That matters when your workflow changes by the hour: one model for drafting, another for coding, another for research, another for rewriting messy notes into something usable.
Use official free routes to test your baseline. Then, if you need more, make your paid move based on output value. If Plus is the exact official account experience you need, buy Plus. If your real goal is broader access, less switching, and better value, 尝试 GlobalGPT before you lock yourself into another single-product subscription.
Start with GlobalGPT and compare the value yourself
Bottom Line
The smartest ChatGPT Plus free trial strategy is not to hunt for magic codes. Start with the official Free plan. Check student routes if you qualify. Use Codex credits only when they match your coding work. Avoid fake trial pages. Then choose the paid route that gives you the most AI value for the way you actually work.
If you only need the official ChatGPT paid account, Plus may be the right move. If you want a broader AI workspace without stacking subscriptions, GlobalGPT is the smarter comparison to make before you spend.
常见问题
Is there an official ChatGPT Plus free trial in 2026?
A normal public ChatGPT Plus free trial was not verified in the official pricing route checked for this update. The safer path is to use the official Free plan, student offers if eligible, or a lower-cost multi-model alternative when you need more power.
What is the safest free way to start using ChatGPT?
Start with the official Free plan from ChatGPT. It is the cleanest zero-dollar route because you are not trusting a coupon page, a shared account seller, or a random trial-code site with your login or payment details.
Are the student offers the same as ChatGPT Plus?
No. Student offers are separate from a normal Plus subscription. If you are a college student, check the official student page and verify the exact offer, eligibility rules, and region before assuming it gives you Plus.
Do Codex student credits give me ChatGPT Plus?
No. Codex student credits are for Codex usage, not for a consumer ChatGPT Plus subscription. They can still be valuable if you are a verified university student doing coding or agent-style developer work.
Should I trust ChatGPT Plus free trial coupon websites?
Be careful. If a page asks for your OpenAI login, payment card, or personal documents before you can verify the offer on an official OpenAI page, treat it as high risk. Real savings should not require giving sensitive data to an unknown site.
What should I do if the free routes are too limited?
If the official free routes are not enough, compare the cost of Plus with a multi-model workspace like GlobalGPT. The practical question is not just whether you can start for free, but whether your next paid step gives enough value.
Can I use GlobalGPT instead of buying ChatGPT Plus?
You can use GlobalGPT as a practical alternative for everyday writing, research, planning, summarizing, and multi-model comparison. It is not the same as an official ChatGPT Plus account, but it can be a smarter value path for many users.
How do I avoid wasting money while testing AI tools?
Use the official Free plan first, claim student routes only when you qualify, avoid risky coupon pages, and upgrade only when you know which work you need to do. If you need several models, compare multi-model pricing before stacking subscriptions.
