

Claude Fable 5 e GPT-5.5 são dois modelos de IA de ponta desenvolvidos para raciocínio avançado, programação, pesquisa, tarefas com contexto extenso e fluxos de trabalho baseados em agentes. Escolher entre Claude Fable 5 e GPT-5.5 não se resume apenas a escolher o modelo com a demonstração de lançamento mais impressionante. Para a maioria dos usuários, a verdadeira questão é mais simples: qual modelo oferece respostas melhores, fluxos de trabalho mais rápidos, suporte à programação mais robusto e melhor custo-benefício?
Nesta comparação, analisaremos o Claude Fable 5 e o GPT-5.5 em três áreas que mais interessam às pessoas: testes de desempenho, custo e desempenho de codificação.
Claude Fable 5 vs GPT-5.5: Comparação rápida
| Categoria | Claude Fable 5 | GPT-5.5 |
|---|---|---|
| Provedor | Antrópico | OpenAI |
| Data de lançamento | 9 de junho de 2026, de acordo com a documentação da Anthropic | 23 de abril de 2026, segundo a OpenAI |
| ID do modelo da API | claude-fable-5 | gpt-5.5 |
| Janela de contexto | 1 milhão de tokens | 1 milhão de tokens para a API; 400 mil no Codex |
| Saída máxima | Até 128 mil tokens | Não está explicitamente mencionado no artigo de lançamento |
| Preço de entrada da API | $10 / 1 milhão de tokens | $5 / 1 milhão de tokens |
| Preço de saída da API | $50 / 1 milhão de tokens | $30 / 1 milhão de tokens |
| Foco na programação | Agentes de longa duração, grandes migrações, implementações complexas | Programação de agentes, depuração, uso de ferramentas, fluxos de trabalho do Codex |
| Medidas de segurança importantes | É possível recusar ou encaminhar determinadas solicitações de alto risco para o Opus 4.8 | Medidas de segurança adicionais observadas na implementação do cartão do sistema e da API |
| Melhor ajuste | Trabalhos ambiciosos de longo prazo, agentes empresariais, projetos complexos de programação | Agentes de codificação, pesquisa, fluxos de trabalho com uso intensivo de ferramentas, produtividade ampla |
O que isso significa para os usuários
O Claude Fable 5 é considerado o modelo de maior capacidade da Anthropic amplamente disponível, especialmente para tarefas de raciocínio complexas e trabalhos com agentes de longo prazo. O GPT-5.5 é apresentado pela OpenAI como um grande avanço para programação, pesquisa, fluxos de trabalho profissionais e tarefas computacionais.
Para usuários comuns, a diferença nem sempre é óbvia em uma simples conversa com um chatbot. A diferença fica mais clara quando a tarefa envolve um contexto mais amplo, programação em várias etapas, uso de ferramentas, depuração, pesquisa ou processamento de documentos extensos.
Escolha Claude Fable 5 se você precisar de um contexto aprofundado, um raciocínio meticuloso e a execução de tarefas de longa duração.
Escolha GPT-5.5 se você precisa de um desempenho de codificação robusto, preços mais baixos por token, fluxos de trabalho com uso intensivo de ferramentas e ampla produtividade profissional.
Se você quiser usar e comparar dois modelos por conta própria, GPT global oferece um espaço de trabalho de IA completo, onde você pode acessar vários modelos de IA com planos básicos de LLM a partir de apenas $5.8.

Comparativo de desempenho entre Claude Fable 5 e GPT-5.5

Por que os benchmarks são importantes
Os benchmarks ajudam os usuários a comparar o desempenho dos modelos entre programação, raciocínio, matemática, uso de ferramentas e tarefas de longo prazo. São especialmente úteis para desenvolvedores e empresas que estão decidindo qual modelo usar nos fluxos de trabalho de produção.
No entanto, os benchmarks não são o mesmo que desempenho na prática. Um modelo pode obter uma boa pontuação em um teste de referência de programação, mas ainda assim apresentar um desempenho diferente na sua base de código, framework ou estilo de prompt.
Dados oficiais de benchmark do GPT-5.5
A OpenAI publicou vários Resultados de benchmark do GPT-5.5. Isso inclui avaliações de programação, trabalho profissional, uso de ferramentas, navegação na internet, matemática e segurança cibernética.
| Referência | Pontuação do GPT-5.5 | O que ele mede |
|---|---|---|
| Banco de terminais 2.0 | 82.7% | Fluxos de trabalho complexos no terminal e na linha de comando |
| SWE-Bench Pro | 58.6% | Resolução de issues no GitHub na prática |
| OSWorld-Verified | 78.7% | Ambientes de computação |
| NavegarComp | 84.4% | Navegação na web e busca de informações |
| FrontierMath Nível 1-3 | 51.7% | Raciocínio matemático avançado |
| FrontierMath Nível 4 | 35.4% | Problemas matemáticos mais difíceis |
| CyberGym | 81.8% | Desempenho das tarefas de segurança cibernética |
Notas sobre o teste de desempenho do Claude Fable 5
Na tabela oficial da Anthropic, o Claude Mythos 5 / Fable 5 supera o GPT-5.5 em várias categorias de benchmark citadas, incluindo SWE-Bench Pro, FrontierCode Diamond, OSWorld-Verified, AutomationBench, Blueprint-Bench 2, Legal Agent Benchmark e HLE com ferramentas.
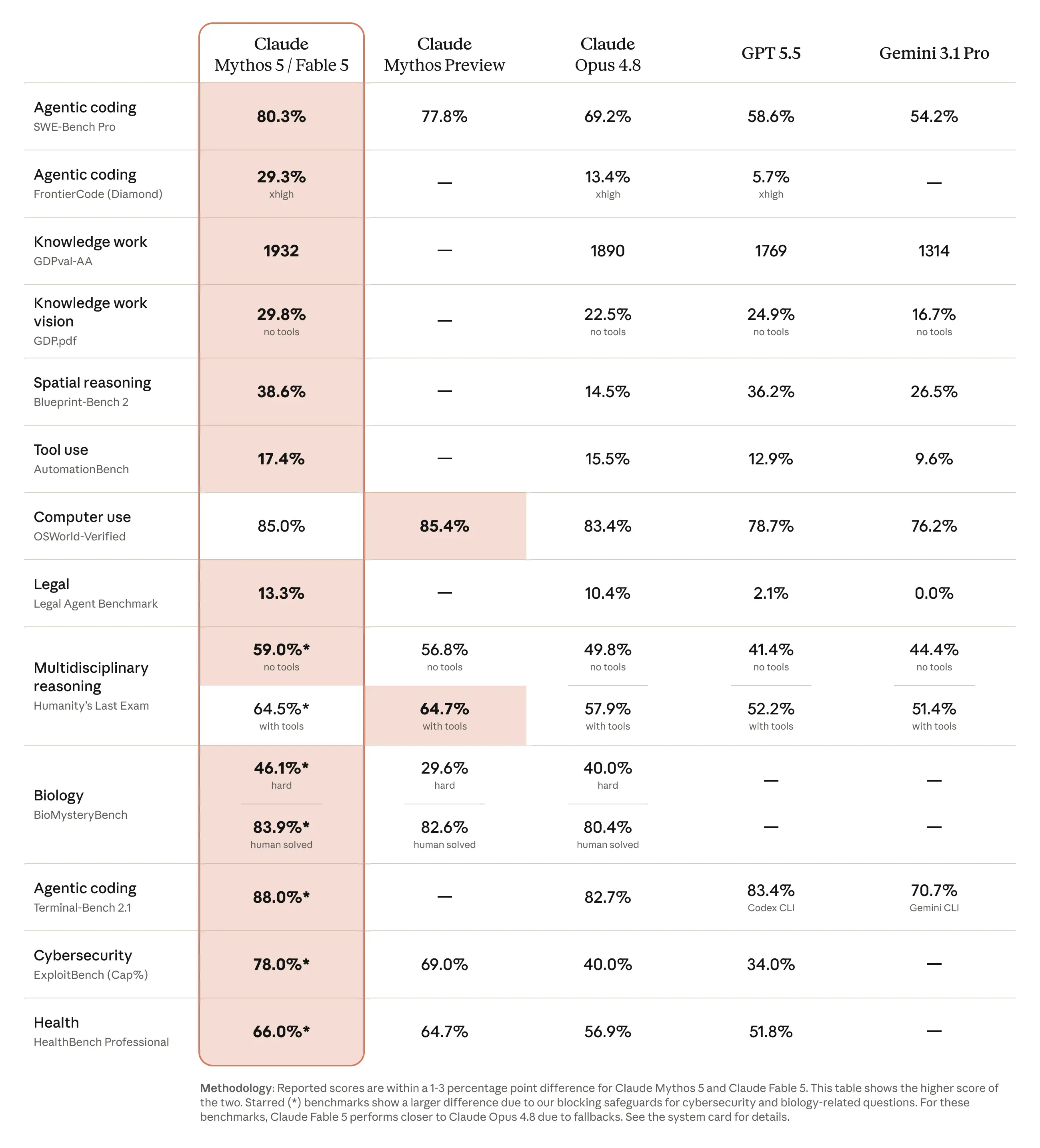
Para os leitores interessados em programação, os resultados mais relevantes são SWE-Bench Pro, FrontierCode Diamond e Terminal-Bench 2.1, porque esses parâmetros de referência refletem melhor engenharia de software de longo prazo, fluxos de trabalho em terminais e tarefas de programação autônoma.

No entanto, os dados de referência devem ser interpretados cuidadosamente. A Anthropic apresenta o Claude Mythos 5 e o Claude Fable 5 em uma coluna de benchmark combinada, e alguns dos resultados destacados incluem advertências importantes sobre segurança e planos alternativos. Por esse motivo, a formulação mais precisa não é “O Claude Fable 5 supera o GPT-5.5 em todos os benchmarks”, mas sim “A tabela oficial de benchmarks do Claude Mythos 5 / Fable 5 da Anthropic apresenta resultados melhores do que os do GPT-5.5 em vários avaliações de codificação, raciocínio e uso de ferramentas.”

Claude Fable 5 vs GPT-5.5: Custo
Preços oficiais da API
| Modelo | Preço de entrada | Preço de saída | Entrada em cache |
|---|---|---|---|
| Claude Fable 5 | $10 / 1 milhão de tokens | $50 / 1 milhão de tokens | Confira os detalhes dos preços da Anthropic |
| GPT-5.5 | $5 / 1 milhão de tokens | $30 / 1 milhão de tokens | $0,50 / 1M tokens |
Exemplo de comparação de custos
| Exemplo de carga de trabalho | Claude Fable 5 | GPT-5.5 |
|---|---|---|
| 1 milhão de tokens de entrada | $10 | $5 |
| 1 milhão de tokens emitidos | $50 | $30 |
| 1 M de entrada + 1 M de saída | $60 | $35 |
Se considerarmos apenas o preço por token, o GPT-5.5 é mais barato. Claude Fable 5 custa cerca do dobro mais para comentários e informações sobre 1,67x mais para saída.
Por que o custo real é maior do que o preço nominal
O preço do token é apenas uma parte do custo. O custo real também depende de:
- Quantas tentativas o modelo precisa
- Qual é a duração das apresentações?
- Se o modelo resolve a tarefa corretamente na primeira tentativa
- Quer você utilize ferramentas, pesquisa, processamento de arquivos, geração de imagens ou geração de vídeos
- Quer sua equipe precise de várias licenças ou de acesso à API
Um modelo mais barato pode acabar saindo caro se fornecer respostas incompletas. Um modelo mais caro pode valer a pena se realizar tarefas complexas com menos correções.
O GPT-5.5 é a melhor opção para usuários que se preocupam com o preço com base nos preços oficiais dos tokens da API. O Claude Fable 5 ainda pode ser útil para tarefas complexas, nas quais uma maior capacidade reduz o trabalho manual, as tentativas repetidas ou o tempo de revisão.
Claude Fable 5 x GPT-5.5 para programação
Visão geral do desempenho da codificação
A programação é uma das áreas mais importantes nesta comparação. A OpenAI descreve o GPT-5.5 como seu modelo de programação com capacidade de ação mais avançado até o momento, com resultados sólidos no Terminal-Bench 2.0 e no SWE-Bench Pro. A Anthropic posiciona o Claude Fable 5 para tarefas de raciocínio complexas e trabalho de agência de longo prazo, o que pode ser relevante em grandes bases de código e tarefas de engenharia complexas.
Os melhores casos de uso de programação para o GPT-5.5
O GPT-5.5 é ideal para:
- Erros de depuração
- Criação de novos recursos
- Reestruturação de código
- Utilização de ferramentas do terminal
- Geração de testes
- Como lidar com tarefas de codificação em várias etapas
- Criação rápida de protótipos
- Trabalhando com agentes de codificação ou ferramentas de desenvolvimento
Os melhores casos de uso de programação para o Claude Fable 5
O Claude Fable 5 pode ser uma excelente opção para:
- Compreensão de bases de código extensas
- Planejamento de arquitetura complexa
- Revisão de código com contexto extenso
- Projetos de migração
- Raciocínio com vários arquivos
- Fluxos de trabalho de desenvolvimento empresarial
- Tarefas que exigem um raciocínio cuidadoso sobre vários documentos ou arquivos de código
Tabela comparativa de codificação
| Tarefa de codificação | Um ponto de partida melhor |
|---|---|
| Correção rápida de bugs | GPT-5.5 |
| Agentes de codificação baseados em terminal | GPT-5.5 |
| Análise de grandes bases de código | Claude Fable 5 |
| Revisão da arquitetura de contexto longo | Claude Fable 5 |
| Codificação com foco no custo | GPT-5.5 |
| Planejamento complexo de migração | Claude Fable 5 |
| Criação rápida de protótipos | GPT-5.5 |
| Comparando as duas saídas lado a lado | Plataforma multimodelo |
Conclusões sobre programação
Para muitos desenvolvedores, o melhor fluxo de trabalho não consiste em escolher apenas um modelo. Uma abordagem prática é utilizar o GPT-5.5 para implementação e depuração rápidas e, em seguida, recorrer ao Claude Fable 5 para revisões mais aprofundadas, raciocínio sobre arquitetura ou análise de contextos extensos.
Em vez de assinar vários serviços de IA separadamente, os usuários podem acessar vários modelos de chat a partir de uma plataforma completa. Isso facilita a comparação Claude Fable 5 e GPT-5.5 em tarefas reais de programação.
Claude Fable 5 vs GPT-5.5 para tarefas com contextos longos
Janela de contexto
De acordo com a documentação oficial e as informações de lançamento, ambos os modelos suportam uma janela de contexto de 1 milhão de tokens. Isso é importante para usuários que trabalham com documentos longos, bases de código, arquivos de pesquisa, contratos, transcrições ou projetos com vários arquivos.
Quando o contexto mais amplo é importante
O contexto mais extenso é útil para:
- Revisão de documentos extensos
- Resumo de artigos científicos
- Compreender repositórios de código na íntegra
- Comparação de documentos jurídicos ou comerciais
- Processamento de registros de suporte ao cliente
- Análise de transcrições de reuniões longas
Conclusão geral
Se o seu trabalho depende de um contexto extenso, ambos os modelos são ótimas opções. A melhor escolha depende da qualidade do resultado, do custo e da confiabilidade com que o modelo segue as instruções ao longo de sessões prolongadas.
Claude Fable 5 x GPT-5.5 para criadores de conteúdo e profissionais de marketing
Redação de conteúdo
Ambos os modelos podem ajudar na redação de conteúdo, textos publicitários, descrições de produtos, campanhas por e-mail e resumos de pesquisas. O GPT-5.5 pode ser mais econômico para fluxos de trabalho com grande volume de conteúdo, enquanto o Claude Fable 5 pode ser útil para redações mais elaboradas e tarefas que envolvam muitos documentos.
Fluxos de trabalho de imagem e vídeo
Nenhuma dessas comparações deve se limitar ao texto. Muitos usuários modernos de IA precisam de texto, imagens e vídeo no mesmo fluxo de trabalho. Por exemplo, um profissional de marketing pode usar um modelo de chat para redigir textos publicitários, um modelo de imagem para criar recursos visuais para campanhas e um modelo de vídeo para gerar conteúdo de formato curto.
Com GlobalGPT, os usuários podem fazer um único pagamento e acessar vários modelos de conversação, modelos de geração de imagens e modelos de geração de vídeos sem precisar alternar entre contas diferentes.

Veredicto final
A comparação entre o Claude Fable 5 e o GPT-5.5 não é uma simples disputa em que o vencedor leva tudo.
O GPT-5.5 apresenta preços oficiais mais baixos por token de API e dados de benchmark públicos sólidos, especialmente para programação e fluxos de trabalho baseados em ferramentas. O Claude Fable 5 está posicionado como o modelo mais capaz da Anthropic amplamente lançado para tarefas de raciocínio complexas e trabalho de agentes de longo prazo, com uma janela de contexto de 1 milhão de tokens e saída máxima de 128 mil.
Para desenvolvedores, criadores, profissionais de marketing, estudantes e pequenas equipes, a abordagem mais inteligente costuma ser testar os dois modelos em tarefas reais. Os benchmarks são úteis, mas suas próprias instruções, documentos, código-fonte e orçamento são mais importantes.
Uma plataforma multimodelo como GlobalGPT facilita esse fluxo de trabalho: basta recarregar uma vez, alternar entre os principais modelos de chat e usar modelos de geração de imagens ou vídeos quando seu projeto precisar de mais do que apenas texto.
PERGUNTAS FREQUENTES
O Claude Fable 5 é melhor que o GPT-5.5?
Isso depende da tarefa. O Claude Fable 5 pode ser mais adequado para raciocínio em contextos extensos e tarefas complexas que exigem autonomia, enquanto o GPT-5.5 apresenta dados de benchmark publicados que demonstram seu desempenho em programação, uso de ferramentas e fluxos de trabalho profissionais.
O GPT-5.5 é mais barato que o Claude Fable 5?
Sim, com base nos preços oficiais da API. O GPT-5.5 está cotado em $5 por 1 milhão de tokens de entrada e $30 por 1 milhão de tokens de saída. O Claude Fable 5 está cotado em $10 por 1 milhão de tokens de entrada e $50 por 1 milhão de tokens de saída.
Qual modelo é melhor para programação?
O GPT-5.5 é um excelente ponto de partida para programação, pois a OpenAI publicou resultados de testes de desempenho nessa área e o posiciona como um modelo de programação autônomo. O Claude Fable 5 pode ser mais adequado para revisão de código em contextos extensos, grandes migrações e raciocínio sobre arquiteturas complexas.
Por que usar uma plataforma de IA multimodelo?
Uma plataforma multimodelo ajuda os usuários a evitar a gestão de assinaturas separadas. Com um único saldo de recarga, os usuários podem acessar diversos modelos de chat, geração de imagens e geração de vídeos em um só lugar.

