

Claude Fable 5 dan GPT-5.5 adalah dua model AI terdepan yang dirancang untuk penalaran tingkat lanjut, pemrograman, penelitian, tugas dengan konteks panjang, dan alur kerja berbasis agen. Memilih antara Claude Fable 5 dan GPT-5.5 Ini bukan sekadar soal memilih model yang memiliki demo peluncuran paling mengesankan. Bagi sebagian besar pengguna, pertanyaannya sebenarnya lebih sederhana: model mana yang memberikan jawaban yang lebih baik, alur kerja yang lebih cepat, dukungan pemrograman yang lebih baik, dan nilai yang lebih baik untuk uang yang dikeluarkan?
Dalam perbandingan ini, kita akan membandingkan Claude Fable 5 dengan GPT-5.5 dalam tiga aspek yang paling menjadi perhatian orang: tolok ukur, biaya, dan kinerja pemrograman.
Claude Fable 5 vs GPT-5.5: Perbandingan Singkat
| Kategori | Claude Fable 5 | GPT-5.5 |
|---|---|---|
| Penyedia | Antropik | OpenAI |
| Waktu peluncuran | 9 Juni 2026, menurut dokumen Anthropic | 23 April 2026, menurut OpenAI |
| ID model API | claude-fable-5 | gpt-5.5 |
| Jendela konteks | 1 juta token | 1 juta token untuk API; 400 ribu di Codex |
| Output maksimal | Hingga 128K token | Tidak disebutkan secara langsung dalam artikel peluncuran tersebut |
| Harga masukan API | Token $10 / 1M | Token $5 / 1M |
| Harga keluaran API | Token $50 / 1M | $30 / 1M token |
| Fokus pemrograman | Agen yang berjalan dalam waktu lama, migrasi berskala besar, implementasi yang rumit | Pemrograman berbasis agen, debugging, penggunaan alat, alur kerja Codex |
| Langkah-langkah pengamanan yang penting | Dapat menolak atau mengalihkan permintaan berisiko tinggi tertentu ke Opus 4.8 | Langkah-langkah pengamanan tambahan yang tercantum dalam peluncuran kartu sistem dan API |
| Paling cocok | Proyek ambisius berjangka panjang, agen perusahaan, proyek pemrograman yang kompleks | Agen pemrograman, penelitian, alur kerja yang banyak menggunakan alat, produktivitas yang luas |
Apa Artinya Hal Ini bagi Pengguna
Claude Fable 5 diposisikan sebagai model Anthropic dengan kemampuan tertinggi yang telah dirilis secara luas, khususnya untuk tugas penalaran yang menuntut dan pekerjaan berbasis agen dengan cakupan jangka panjang. GPT-5.5 diposisikan oleh OpenAI sebagai langkah maju yang signifikan dalam bidang pemrograman, penelitian, alur kerja profesional, dan tugas-tugas berbasis komputer.
Bagi pengguna awam, perbedaannya mungkin tidak selalu terlihat jelas dalam percakapan sederhana dengan chatbot. Perbedaan tersebut menjadi lebih jelas ketika tugas yang dilakukan melibatkan konteks yang lebih luas, pemrograman bertahap, penggunaan alat, debugging, penelitian, atau pemrosesan dokumen yang panjang.
Pilih Claude Fable 5 jika Anda membutuhkan konteks yang mendalam, penalaran yang cermat, dan pelaksanaan tugas yang memakan waktu lama.
Pilih GPT-5.5 jika Anda membutuhkan performa pemrograman yang tinggi, harga token yang lebih murah, alur kerja yang memanfaatkan banyak alat, serta produktivitas profesional yang luas.
Jika Anda ingin menggunakan dan membandingkan dua model tersebut sendiri, GPT Global menawarkan ruang kerja AI serba guna tempat Anda dapat mengakses berbagai model AI dengan paket LLM dasar mulai dari hanya $5.8.

Perbandingan Kinerja Claude Fable 5 vs GPT-5.5

Mengapa Tolok Ukur Itu Penting
Tolok ukur membantu pengguna membandingkan kinerja model di berbagai pemrograman, penalaran, matematika, penggunaan alat, dan tugas-tugas dengan konteks yang luas. Model-model ini sangat berguna bagi para pengembang dan perusahaan yang sedang mempertimbangkan model mana yang akan digunakan dalam alur kerja produksi.
Namun, tolok ukur tidak sama dengan kinerja di dunia nyata. Sebuah model mungkin memperoleh skor yang baik pada uji standar pemrograman, namun tetap saja kinerjanya bisa berbeda saat diterapkan pada basis kode, kerangka kerja, atau gaya prompt Anda.
Data Uji Kinerja Resmi GPT-5.5
OpenAI telah menerbitkan beberapa hasil pengujian perbandingan untuk GPT-5.5. Di antaranya adalah evaluasi dalam bidang pemrograman, pekerjaan profesional, penggunaan alat, penjelajahan internet, matematika, dan keamanan siber.
| Patokan | Skor GPT-5.5 | Apa yang Diukur |
|---|---|---|
| Terminal-Bench 2.0 | 82.7% | Alur kerja terminal dan baris perintah yang kompleks |
| SWE-Bench Pro | 58.6% | Penyelesaian masalah GitHub di dunia nyata |
| Terverifikasi OSWorld | 78.7% | Lingkungan operasi komputer |
| BrowseComp | 84.4% | Menjelajah web dan pencarian informasi |
| FrontierMath Tingkat 1-3 | 51.7% | Penalaran matematika tingkat lanjut |
| FrontierMath Tingkat 4 | 35.4% | Soal-soal matematika tingkat lanjut yang lebih sulit |
| CyberGym | 81.8% | Kinerja tugas keamanan siber |
Catatan Uji Kinerja Claude Fable 5
Dalam tabel resmi Anthropic, Claude Mythos 5 / Fable 5 unggul atas GPT-5.5 dalam beberapa kategori benchmark yang disebutkan, termasuk SWE-Bench Pro, FrontierCode Diamond, OSWorld-Verified, AutomationBench, Blueprint-Bench 2, Legal Agent Benchmark, dan HLE dengan alat bantu.
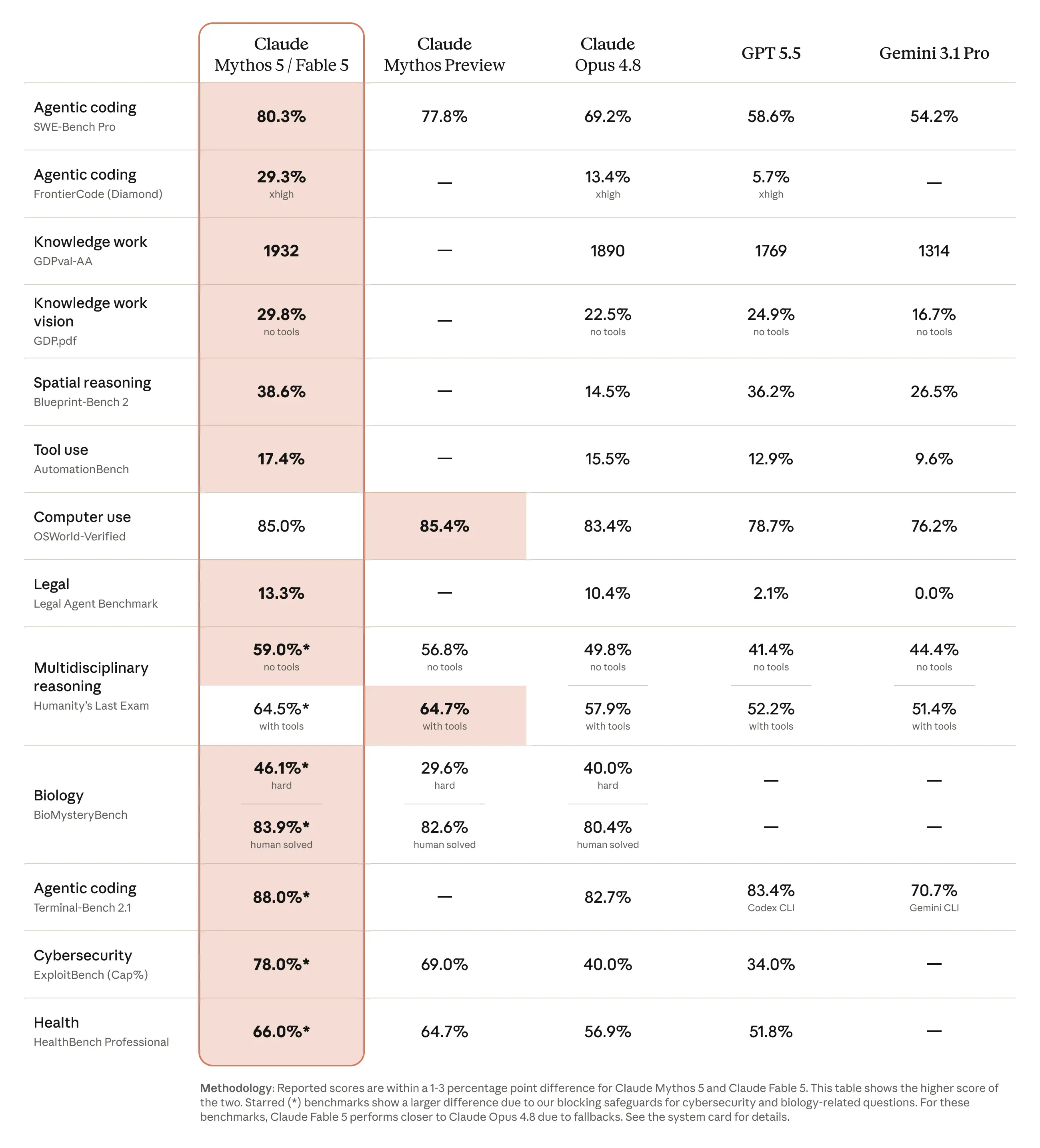
Bagi pembaca yang berfokus pada pemrograman, hasil yang paling relevan adalah SWE-Bench Pro, FrontierCode Diamond, dan Terminal-Bench 2.1, karena tolok ukur ini lebih mencerminkan rekayasa perangkat lunak jangka panjang, alur kerja terminal, dan tugas pemrograman berbasis agen.

Namun, data acuan tersebut sebaiknya ditafsirkan dengan hati-hati. Anthropic menyajikan Claude Mythos 5 dan Claude Fable 5 dalam satu kolom benchmark gabungan, dan beberapa hasil yang diberi tanda bintang antara lain Peringatan penting terkait keselamatan dan langkah cadangan. Karena itu, pernyataan yang paling akurat bukanlah “Claude Fable 5 mengungguli GPT-5.5 di setiap uji kinerja,” melainkan “Tabel uji kinerja resmi Claude Mythos 5 / Fable 5 dari Anthropic menunjukkan hasil yang lebih baik daripada GPT-5.5 di beberapa penilaian kemampuan pemrograman, penalaran, dan penggunaan alat.”

Claude Fable 5 vs GPT-5.5: Biaya
Harga Resmi API
| Model | Harga Masukan | Harga Keluaran | Masukan yang Disimpan dalam Cache |
|---|---|---|---|
| Claude Fable 5 | Token $10 / 1M | Token $50 / 1M | Lihat rincian harga Anthropic |
| GPT-5.5 | Token $5 / 1M | $30 / 1M token | $0.50 / 1 juta token |
Contoh Perbandingan Biaya
| Contoh Beban Kerja | Claude Fable 5 | GPT-5.5 |
|---|---|---|
| 1 juta token masukan | $10 | $5 |
| 1 juta token keluaran | $50 | $30 |
| 1M masukan + 1M keluaran | $60 | $35 |
Jika hanya dilihat dari harga per token, GPT-5.5 lebih murah. Claude Fable 5 harganya sekitar 2 kali lipat lebih lanjut untuk masukan dan mengenai 1,67x lebih lanjut untuk output.
Mengapa Biaya Sebenarnya Lebih Tinggi daripada Harga Token
Penetapan harga token hanyalah sebagian dari biaya. Biaya sebenarnya juga bergantung pada:
- Berapa kali percobaan ulang yang dibutuhkan model tersebut
- Seberapa panjang hasilnya
- Apakah model tersebut berhasil menyelesaikan tugas tersebut dengan benar pada percobaan pertama
- Baik Anda menggunakan alat, fitur pencarian, pemrosesan file, pembuatan gambar, maupun pembuatan video
- Apakah tim Anda membutuhkan beberapa lisensi atau akses API
Model yang lebih murah bisa jadi justru mahal jika menghasilkan jawaban yang tidak lengkap. Model yang lebih mahal bisa jadi sepadan jika mampu menyelesaikan tugas-tugas rumit dengan sedikit koreksi.
GPT-5.5 merupakan pilihan yang lebih tepat bagi pengguna yang mengutamakan harga berdasarkan harga resmi token API. Claude Fable 5 mungkin masih bermanfaat untuk tugas-tugas kompleks di mana kemampuan yang lebih tinggi dapat mengurangi pekerjaan manual, upaya ulang, atau waktu peninjauan.
Claude Fable 5 vs GPT-5.5 dalam Pemrograman
Gambaran Umum Kinerja Pemrograman
Pemrograman merupakan salah satu bidang terpenting dalam perbandingan ini. OpenAI menggambarkan GPT-5.5 sebagai model pemrograman agentik terkuatnya hingga saat ini, dengan hasil yang memuaskan pada Terminal-Bench 2.0 dan SWE-Bench Pro. Anthropic memposisikan Claude Fable 5 untuk tugas penalaran yang menuntut dan pekerjaan agenik jangka panjang, yang dapat menjadi faktor penting dalam basis kode yang besar dan tugas-tugas rekayasa yang kompleks.
Contoh Penggunaan Pemrograman Terbaik untuk GPT-5.5
GPT-5.5 sangat cocok untuk:
- Memperbaiki kesalahan
- Menulis fitur-fitur baru
- Refactoring kode
- Menggunakan alat-alat terminal
- Membuat tes
- Menyelesaikan tugas pengkodean bertahap
- Membuat prototipe dengan cepat
- Bekerja di dalam agen pemrograman atau alat pengembang
Contoh Penggunaan Pemrograman Terbaik untuk Claude Fable 5
Claude Fable 5 mungkin sangat cocok untuk:
- Pemahaman mendalam terhadap basis kode yang besar
- Perencanaan arsitektur yang kompleks
- Tinjauan kode dengan konteks yang luas
- Proyek-proyek migrasi
- Penalaran multi-file
- Alur kerja pengembangan perusahaan
- Tugas-tugas yang memerlukan penalaran cermat terhadap banyak dokumen atau berkas kode
Tabel Perbandingan Kode
| Tugas Pengkodean | Titik Awal yang Lebih Baik |
|---|---|
| Perbaikan bug secara cepat | GPT-5.5 |
| Agen pengkodean berbasis terminal | GPT-5.5 |
| Analisis basis kode yang besar | Claude Fable 5 |
| Tinjauan arsitektur dalam konteks yang luas | Claude Fable 5 |
| Pengkodean yang mempertimbangkan biaya | GPT-5.5 |
| Perencanaan migrasi yang kompleks | Claude Fable 5 |
| Pembuatan prototipe cepat | GPT-5.5 |
| Menguji kedua keluaran secara berdampingan | Platform multi-model |
Pelajaran Utama dalam Pemrograman
Bagi banyak pengembang, alur kerja terbaik bukanlah dengan hanya memilih satu model saja. Pendekatan yang praktis adalah menggunakan GPT-5.5 untuk implementasi dan debugging yang cepat, lalu menggunakan Claude Fable 5 untuk tinjauan yang lebih mendalam, penalaran arsitektur, atau analisis konteks panjang.
Alih-alih berlangganan beberapa layanan AI secara terpisah, pengguna dapat mengakses berbagai model obrolan dari platform serba guna. Hal itu memudahkan perbandingan Claude Fable 5 dan GPT-5.5 pada tugas-tugas pemrograman yang sesungguhnya.
Claude Fable 5 vs GPT-5.5 untuk Tugas dengan Konteks Panjang
Jendela Konteks
Kedua model tersebut mendukung jendela konteks sebesar 1 juta token, sesuai dengan dokumentasi resmi dan informasi rilis. Hal ini penting bagi pengguna yang bekerja dengan dokumen panjang, basis kode, berkas penelitian, kontrak, transkrip, atau proyek yang terdiri dari banyak berkas.
Ketika Konteks yang Panjang Memiliki Peran Penting
Konteks yang panjang berguna untuk:
- Meninjau dokumen-dokumen yang tebal
- Merangkum makalah penelitian
- Memahami repositori kode secara keseluruhan
- Membandingkan dokumen hukum atau bisnis
- Pemrosesan catatan layanan pelanggan
- Menganalisis transkrip rapat yang panjang
Kesimpulan dari Konteks yang Luas
Jika pekerjaan Anda sangat bergantung pada konteks yang luas, kedua model tersebut merupakan pilihan yang sangat layak. Pilihan yang lebih baik bergantung pada kualitas hasil, biaya, dan seberapa andal model tersebut mengikuti instruksi selama sesi yang panjang.
Claude Fable 5 vs GPT-5.5 untuk Para Kreator dan Pemasar
Penulisan Konten
Kedua model tersebut dapat membantu dalam penulisan konten, teks iklan, deskripsi produk, kampanye email, dan ringkasan penelitian. GPT-5.5 mungkin lebih hemat biaya untuk alur kerja konten bervolume tinggi, sedangkan Claude Fable 5 mungkin berguna untuk penulisan panjang yang lebih mendalam dan tugas-tugas yang melibatkan banyak dokumen.
Alur Kerja Gambar dan Video
Kedua perbandingan tersebut tidak boleh hanya terbatas pada teks. Banyak pengguna AI modern membutuhkan teks, gambar, dan video dalam alur kerja yang sama. Misalnya, seorang pemasar mungkin menggunakan model obrolan untuk menulis naskah iklan, model gambar untuk membuat visual kampanye, dan model video untuk menghasilkan konten berdurasi pendek.
Dengan GlobalGPT, pengguna dapat melakukan pengisian ulang sekali saja dan mengakses berbagai model percakapan, model pembuat gambar, serta model pembuat video tanpa perlu berpindah-pindah antar akun yang terpisah.

Keputusan Akhir
Perbandingan antara Claude Fable 5 dan GPT-5.5 bukanlah sekadar perbandingan di mana pemenangnya akan merebut semuanya.
GPT-5.5 menawarkan harga token API resmi yang lebih rendah serta data benchmark publik yang solid, terutama untuk pemrograman dan alur kerja berbasis alat. Claude Fable 5 diposisikan sebagai model Anthropic yang paling mumpuni dan telah dirilis secara luas untuk tugas penalaran yang menuntut serta pekerjaan agen dengan cakupan jangka panjang, dengan jendela konteks 1 juta token dan output maksimum 128 ribu.
Bagi para pengembang, kreator, pemasar, mahasiswa, dan tim kecil, pendekatan paling cerdas seringkali adalah menguji kedua model tersebut pada tugas-tugas nyata. Uji perbandingan memang berguna, tetapi prompt, dokumen, basis kode, dan anggaran Anda sendiri jauh lebih penting.
Platform multi-model seperti GlobalGPT Hal ini mempermudah alur kerja tersebut: cukup isi ulang sekali, beralih di antara model obrolan terkemuka, dan gunakan model pembuat gambar atau video saat proyek Anda membutuhkan lebih dari sekadar teks.
PERTANYAAN YANG SERING DIAJUKAN
Apakah Claude Fable 5 lebih baik daripada GPT-5.5?
Itu tergantung pada tugasnya. Claude Fable 5 mungkin lebih unggul dalam penalaran berbasis konteks panjang dan pekerjaan yang melibatkan agen yang kompleks, sedangkan GPT-5.5 memiliki data benchmark yang telah dipublikasikan dan terbukti kuat dalam hal pemrograman, penggunaan alat, dan alur kerja profesional.
Apakah GPT-5.5 lebih murah daripada Claude Fable 5?
Ya, berdasarkan harga resmi API. GPT-5.5 dihargai $5 per 1 juta token masukan dan $30 per 1 juta token keluaran. Claude Fable 5 dihargai $10 per 1 juta token masukan dan $50 per 1 juta token keluaran.
Model mana yang lebih baik untuk pemrograman?
GPT-5.5 merupakan titik awal yang solid untuk pemrograman karena OpenAI telah mempublikasikan hasil uji kinerja pemrograman dan mengklasifikasikannya sebagai model pemrograman yang bersifat agen. Claude Fable 5 mungkin lebih cocok untuk tinjauan kode dengan konteks panjang, migrasi skala besar, dan analisis arsitektur yang kompleks.
Mengapa menggunakan platform AI multi-model?
Platform multi-model ini memudahkan pengguna agar tidak perlu mengelola langganan yang terpisah-pisah. Dengan satu saldo isi ulang, pengguna dapat mengakses berbagai model obrolan, model pembuat gambar, dan model pembuat video di satu tempat.

