

كلود فابل 5 و GPT-5.5.5 هما نموذجان رائدان في مجال الذكاء الاصطناعي صُمما من أجل الاستدلال المتقدم والبرمجة والبحث والمهام ذات السياق الطويل وسير العمل التفاعلي. الاختيار بين كلود فابل 5 و GPT-5.5 لا يقتصر الأمر على اختيار الطراز الذي يقدم عرضًا توضيحيًا أكثر إثارة للإعجاب عند الإطلاق. بالنسبة لمعظم المستخدمين، فإن السؤال الحقيقي أبسط من ذلك: أي طراز يوفر لك إجابات أفضل، وسير عمل أسرع، ودعمًا أقوى للبرمجة، وقيمة أفضل مقابل المال؟
في هذه المقارنة، سنلقي نظرة على كلود فابل 5 مقابل GPT-5.5 في ثلاثة مجالات تهم المستخدمين بشكل خاص: المعايير المرجعية والتكلفة وأداء البرمجة.
كلود فابل 5 مقابل GPT-5.5: مقارنة سريعة
| الفئة | كلود فابل 5 | GPT-5.5.5 |
|---|---|---|
| المزود | أنثروبي | OpenAI |
| توقيت الإصدار | 9 يونيو 2026، وفقًا لوثائق شركة أنثروبيك | 23 أبريل 2026، وفقًا لـ OpenAI |
| معرف نموذج واجهة برمجة التطبيقات | كلود-فابل-5 | gpt-5.5 |
| نافذة السياق | 1 مليون توكن | 1 مليون توكن لـ API؛ 400 ألف في Codex |
| الحد الأقصى للإخراج | ما يصل إلى 128 ألف توكن | لم يرد ذلك صراحةً في المقال الذي أُعلن فيه عن الإطلاق |
| سعر الشراء وفقًا لواجهة برمجة التطبيقات | $10 / 1M توكنز $10 / 1M توكنز | $5 / 1M توكنز $5 / 1M توكنز |
| سعر البيع وفقًا لواجهة برمجة التطبيقات | $50 / 1 مليون توكنز | $30 / 1 مليون توكن |
| التركيز على البرمجة | العملاء الذين يعملون لفترات طويلة، وعمليات الترحيل الضخمة، وعمليات التنفيذ المعقدة | البرمجة التفاعلية، تصحيح الأخطاء، استخدام الأدوات، سير عمل Codex |
| الضمانات البارزة | يمكن رفض بعض الطلبات عالية المخاطر أو توجيهها إلى Opus 4.8 | الضمانات الإضافية المذكورة في بطاقة النظام وعملية طرح واجهة برمجة التطبيقات |
| أفضل ملاءمة | الأعمال الطموحة طويلة الأجل، ووكلاء المؤسسات، ومشاريع البرمجة المعقدة | أدوات البرمجة، والأبحاث، وسير العمل الذي يعتمد بشكل كبير على الأدوات، والإنتاجية الواسعة النطاق |
ماذا يعني ذلك للمستخدمين
يُعتبر «كلود فابل 5» النموذج الأكثر قدرةً الذي أطلقته شركة «أنثروبيك» على نطاق واسع، لا سيما في مجال الاستدلال المعقد والأعمال التي تتطلب وكلاءً ذوي آفاق طويلة المدى. أما «جي بي تي-5.5» فتصفه «أوبن إيه آي» بأنه خطوة كبيرة إلى الأمام في مجالات البرمجة والبحث وسير العمل المهني والمهام الحاسوبية.
بالنسبة للمستخدمين العاديين، قد لا يكون الفرق واضحًا دائمًا في محادثة بسيطة مع روبوت الدردشة. لكن الفارق يصبح أكثر وضوحًا عندما تتطلب المهمة سياقًا أوسع، أو برمجة متعددة الخطوات، أو استخدام أدوات، أو تصحيح الأخطاء، أو إجراء أبحاث، أو معالجة مستندات طويلة.
اختر كلود فابل 5 إذا كنت بحاجة إلى فهم عميق للسياق، وتفكير مدروس، وتنفيذ مهام تستغرق وقتًا طويلاً.
اختر GPT-5.5.5 إذا كنت بحاجة إلى أداء برمجي قوي، وأسعار أقل للرموز الرقمية، وسير عمل يعتمد على العديد من الأدوات، وإنتاجية مهنية واسعة النطاق.
إذا كنت ترغب في استخدام نموذجين ومقارنتهما بنفسك،, Global GPT توفر مساحة عمل شاملة للذكاء الاصطناعي تتيح لك الوصول إلى نماذج متعددة للذكاء الاصطناعي، مع باقات أساسية لنماذج اللغة الكبيرة (LLM) تبدأ من $5.8.

اختبارات أداء كلود فابل 5 مقابل GPT-5.5

لماذا تعتبر المعايير المرجعية مهمة
تساعد المعايير القياسية المستخدمين على مقارنة أداء الطرز عبر البرمجة، والتفكير المنطقي، والرياضيات، واستخدام الأدوات، والمهام ذات السياق الطويل. وهي مفيدة بشكل خاص للمطورين والشركات التي تسعى إلى تحديد النموذج الذي ستستخدمه في سير عمل الإنتاج.
ومع ذلك، فإن المعايير المرجعية تختلف عن الأداء الفعلي. قد يحقق النموذج نتائج جيدة في اختبار أداء البرمجة، لكنه قد يقدم أداءً مختلفًا عند استخدامه مع قاعدة الكود الخاصة بك أو إطار العمل أو أسلوب المطالبة.
بيانات الاختبار القياسي الرسمية لنظام GPT-5.5
نشرت OpenAI عدة نتائج الاختبارات القياسية لنظام GPT-5.5. وتشمل هذه التقييمات البرمجة، والأعمال المهنية، واستخدام الأدوات، والتصفح، والرياضيات، والأمن السيبراني.
| معيار | نتيجة GPT-5.5 | ما الذي يقيسه |
|---|---|---|
| المنضدة الطرفية 2.0 | 82.7% | عمليات سير العمل المعقدة في واجهة المستخدم وخط الأوامر |
| سوي-بينش برو | 58.6% | حل مشكلات GitHub في الواقع العملي |
| تم التحقق من عالم الأو إس دبليو إس وورلد | 78.7% | بيئات تشغيل الحواسيب |
| BrowseComp | 84.4% | تصفح الويب والبحث عن المعلومات |
| FrontierMath المستوى 1-3 | 51.7% | التفكير الرياضي المتقدم |
| FrontierMath المستوى 4 | 35.4% | مسائل رياضيات الحدود الأكثر صعوبة |
| سايبر جيم | 81.8% | أداء مهام الأمن السيبراني |
ملاحظات حول اختبار أداء Claude Fable 5
في الجدول الرسمي لشركة Anthropic، يتفوق Claude Mythos 5 / Fable 5 على GPT-5.5 في العديد من فئات الاختبارات القياسية المذكورة، بما في ذلك SWE-Bench Pro وFrontierCode Diamond وOSWorld-Verified وAutomationBench وBlueprint-Bench 2 وLegal Agent Benchmark وHLE مع الأدوات.
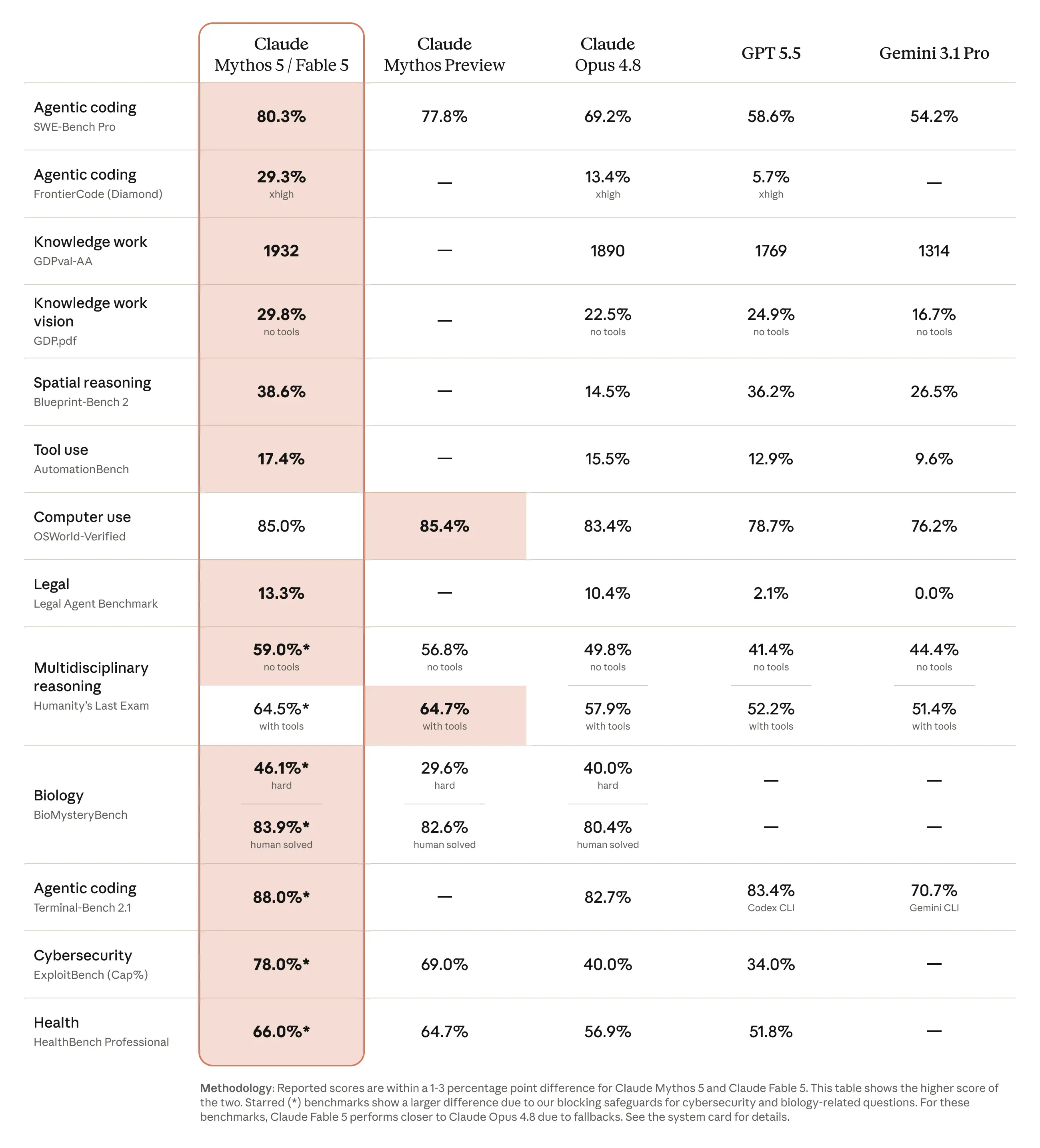
بالنسبة للقراء المهتمين بالبرمجة، فإن النتائج الأكثر صلة هي SWE-Bench Pro و FrontierCode Diamond و Terminal-Bench 2.1،, لأن هذه المعايير تعكس بشكل أفضل هندسة البرمجيات طويلة المدى، وسير العمل النهائي، ومهام البرمجة التفاعلية.

ومع ذلك، ينبغي تفسير البيانات المعيارية بعناية. تدرج شركة Anthropic كل من "Claude Mythos 5" و"Claude Fable 5" في عمود واحد ضمن اختبارات الأداء، وتشمل بعض النتائج المميزة ما يلي: تحذيرات مهمة تتعلق بالسلامة والخطط البديلة. ولهذا السبب، فإن الصيغة الأكثر دقة ليست “يتفوق كلود فابل 5 على GPT-5.5 في كل اختبار أداء”، بل “يُظهر جدول اختبارات الأداء الرسمي لـ«كلود ميثوس 5» و«كلود فابل 5» من شركة أنثروبيك نتائج أقوى من GPT-5.5 في العديد من تقييمات القدرات في مجالات البرمجة والتفكير المنطقي واستخدام الأدوات.”

كلود فابل 5 مقابل GPT-5.5: التكلفة
الأسعار الرسمية لواجهة برمجة التطبيقات
| نموذج | سعر المدخلات | سعر المخرجات | المدخلات المخزنة مؤقتًا |
|---|---|---|---|
| كلود فابل 5 | $10 / 1M توكنز $10 / 1M توكنز | $50 / 1 مليون توكنز | اطلع على تفاصيل أسعار Anthropic |
| GPT-5.5.5 | $5 / 1M توكنز $5 / 1M توكنز | $30 / 1 مليون توكن | $0.50 / 1M توكنات |
مثال على مقارنة التكاليف
| مثال على حجم العمل | كلود فابل 5 | GPT-5.5.5 |
|---|---|---|
| 1 مليون رمز إدخال | $10 | $5 |
| 1 مليون توكن ناتج | $50 | $30 |
| مدخلات 1 م + مخرجات 1 م | $60 | $35 |
بناءً على سعر الوحدة فقط، يُعد GPT-5.5 أرخص. كلود فابل 5 تكلف حوالي ضعف السعر المزيد للتعليقات والمزيد من المعلومات 1.67 ضعف المزيد للإخراج.
لماذا تتجاوز التكلفة الفعلية سعر العملة الرقمية
لا يمثل سعر التوكن سوى جزء من التكلفة. فالتكلفة الفعلية تعتمد أيضًا على:
- كم عدد محاولات إعادة التشغيل التي يحتاجها النموذج
- ما هي مدة المخرجات
- ما إذا كان النموذج يحل المهمة بشكل صحيح من المرة الأولى
- سواء كنت تستخدم الأدوات أو البحث أو معالجة الملفات أو إنشاء الصور أو إنشاء مقاطع الفيديو
- سواء كان فريقك بحاجة إلى عدة تراخيص أو وصول إلى واجهة برمجة التطبيقات
قد يصبح النموذج الأرخص ثمناً مكلفاً إذا كان ينتج إجابات غير كاملة. وقد يكون النموذج الأغلى ثمناً يستحق التكلفة إذا كان ينجز المهام المعقدة مع عدد أقل من التصحيحات.
يُعد GPT-5.5 الخيار الأفضل للمستخدمين الذين يهتمون بالسعر استنادًا إلى الأسعار الرسمية لرموز API. قد تظل Claude Fable 5 مفيدة في المهام المعقدة التي تقلل فيها القدرات العالية من العمل اليدوي أو عمليات إعادة المحاولة أو وقت المراجعة.
كلود فابل 5 مقابل GPT-5.5 في البرمجة
نظرة عامة على أداء البرمجة
يُعد البرمجة أحد أهم المجالات في هذه المقارنة. تصف OpenAI نموذج GPT-5.5 بأنه أقوى نموذج برمجة عملي لديها حتى الآن، حيث حقق نتائج قوية في اختباري Terminal-Bench 2.0 و SWE-Bench Pro. تضع Anthropic نموذج Claude Fable 5 في موضع يتيح له القيام بأعمال الاستدلال الصعبة والأعمال الوكيلة طويلة المدى، وهو ما قد يكون مهمًا في قواعد البيانات البرمجية الكبيرة والمهام الهندسية المعقدة.
أفضل حالات استخدام البرمجة مع GPT-5.5
يُعد GPT-5.5 خيارًا مثاليًا لـ:
- تصحيح الأخطاء
- كتابة ميزات جديدة
- إعادة هيكلة الكود
- استخدام أدوات المحطة الطرفية
- إنشاء الاختبارات
- التعامل مع مهام الترميز متعددة الخطوات
- بناء النماذج الأولية بسرعة
- العمل داخل برامج البرمجة أو أدوات المطورين
أفضل حالات استخدام البرمجة في لعبة Claude Fable 5
قد يكون «كلود فابل 5» خيارًا مناسبًا تمامًا لـ:
- فهم قاعدة الكود الكبيرة
- تخطيط الهندسة المعمارية المعقدة
- مراجعة الكود في سياق واسع
- مشاريع الهجرة
- التفكير متعدد الملفات
- سير عمل تطوير المشاريع
- المهام التي تتطلب تفكيرًا دقيقًا في العديد من المستندات أو ملفات البرمجة
جدول مقارنة الترميز
| مهمة الترميز | نقطة انطلاق أفضل |
|---|---|
| إصلاح سريع للأخطاء | GPT-5.5.5 |
| عوامل الترميز القائمة على المحطات الطرفية | GPT-5.5.5 |
| تحليل قاعدة بيانات كبيرة | كلود فابل 5 |
| مراجعة بنية السياق الطويل | كلود فابل 5 |
| الترميز المراعي للتكلفة | GPT-5.5.5 |
| التخطيط الشامل للهجرة | كلود فابل 5 |
| إنشاء النماذج الأولية بسرعة | GPT-5.5.5 |
| اختبار كلا المخرجين جنبًا إلى جنب | منصة متعددة النماذج |
أهم النقاط في البرمجة
بالنسبة للعديد من المطورين، لا يتمثل أفضل مسار عمل في الاكتفاء باختيار نموذج واحد فقط. ومن الأساليب العملية في هذا الصدد استخدام GPT-5.5 للتنفيذ السريع وتصحيح الأخطاء، ثم استخدام Claude Fable 5 لإجراء مراجعة أعمق، أو الاستدلال على البنية، أو تحليل السياقات الطويلة.
بدلاً من الاشتراك في خدمات الذكاء الاصطناعي المتعددة بشكل منفصل، يمكن للمستخدمين الوصول إلى نماذج دردشة متعددة من منصة شاملة. وهذا يسهل عملية المقارنة كلود فابل 5 و GPT-5.5.5 في مهام البرمجة الفعلية.
مقارنة بين Claude Fable 5 و GPT-5.5 في معالجة السياقات الطويلة
نافذة السياق
يدعم كلا النموذجين نافذة سياق بسعة مليون رمز، وفقًا للوثائق الرسمية ومعلومات الإصدار. ويعد هذا الأمر مهمًا للمستخدمين الذين يعملون مع مستندات طويلة، أو قواعد برمجية، أو ملفات بحثية، أو عقود، أو نصوص محاضرات، أو مشاريع متعددة الملفات.
عندما يكون السياق الطويل مهمًا
يُعد السياق الطويل مفيدًا في:
- مراجعة المستندات الكبيرة
- تلخيص الأوراق البحثية
- فهم مستودعات الكود بالكامل
- مقارنة الوثائق القانونية أو التجارية
- معالجة سجلات دعم العملاء
- تحليل محاضر الاجتماعات الطويلة
النقطة الأساسية في السياق الأوسع
إذا كان عملك يعتمد على سياق واسع النطاق، فإن كلا النموذجين يعتبران خيارين قويين. ويعتمد الاختيار الأفضل على جودة النتائج والتكلفة ومدى موثوقية اتباع النموذج للتعليمات خلال الجلسات الطويلة.
كلود فابل 5 مقابل GPT-5.5 للمبدعين والمسوقين
كتابة المحتوى
يمكن أن يساعد كلا النموذجين في كتابة المحتوى، ونصوص الإعلانات، ووصف المنتجات، وحملات البريد الإلكتروني، وملخصات الأبحاث. وقد يكون GPT-5.5 أكثر فعالية من حيث التكلفة في عمليات إنتاج المحتوى ذات الحجم الكبير، في حين قد يكون Claude Fable 5 مفيدًا في الكتابة الطويلة التي تتطلب دقة أكبر والمهام التي تتضمن عددًا كبيرًا من المستندات.
مسارات عمل الصور والفيديو
ولا ينبغي أن تقتصر أي من هاتين المقارنتين على النص فقط. فالعديد من مستخدمي الذكاء الاصطناعي المعاصرين يحتاجون إلى النصوص والصور والفيديو في نفس مسار العمل. على سبيل المثال، قد يستخدم أحد المسوقين نموذجًا للدردشة لكتابة نصوص إعلانية، ونموذجًا للصور لإنشاء العناصر المرئية للحملة، ونموذجًا للفيديو لإنتاج محتوى قصير.
مع جلوبال جي بي تي تي, ، يمكن للمستخدمين إجراء عملية شحن واحدة والوصول إلى العديد من نماذج المحادثة ونماذج إنشاء الصور ونماذج إنشاء الفيديو دون الحاجة إلى التبديل بين حسابات منفصلة.

الحكم النهائي
المقارنة بين «كلود فابل 5» و«GPT-5.5» ليست مجرد مقارنة من النوع الذي «الفائز يحصل على كل شيء».
يتميز GPT-5.5 بأسعار أقل للرموز في واجهة برمجة التطبيقات (API) الرسمية، بالإضافة إلى بيانات قياسية عامة قوية، لا سيما في مجالات البرمجة وسير العمل المعتمد على الأدوات. يُعتبر Claude Fable 5 النموذج الأكثر قدرةً الذي أطلقته Anthropic على نطاق واسع للمنطق الصعب والأعمال الوكيلة طويلة المدى، مع نافذة سياق تبلغ 1 مليون رمز وخرج أقصى يبلغ 128 ألف.
بالنسبة للمطورين والمبدعين والمسوقين والطلاب والفرق الصغيرة، غالبًا ما يكون النهج الأذكى هو اختبار كلا النموذجين في مهام حقيقية. فاختبارات الأداء مفيدة، لكن المطالبات الخاصة بك والوثائق وقاعدة الكود والميزانية هي العوامل الأكثر أهمية.
منصة متعددة النماذج مثل جلوبال جي بي تي تي يجعل هذا المسار أكثر سهولة: قم بإعادة الشحن مرة واحدة، وانتقل بين نماذج الدردشة الرائدة، واستخدم نماذج إنشاء الصور أو مقاطع الفيديو عندما يحتاج مشروعك إلى أكثر من مجرد نص.
الأسئلة الشائعة
هل يعد «كلود فابل 5» أفضل من «جي بي تي-5.5»؟
يعتمد ذلك على المهمة. قد يكون Claude Fable 5 أكثر ملاءمةً للاستدلال في السياقات الطويلة والأعمال المعقدة التي تتطلب قدرة على التصرف بشكل مستقل، في حين أن GPT-5.5 يتمتع ببيانات قياسية منشورة قوية في مجالات البرمجة واستخدام الأدوات وسير العمل المهني.
هل GPT-5.5 أرخص من Claude Fable 5؟
نعم، استنادًا إلى الأسعار الرسمية لواجهة برمجة التطبيقات (API). يبلغ سعر GPT-5.5 $5 لكل مليون رمز إدخال و$30 لكل مليون رمز إخراج. يبلغ سعر Claude Fable 5 $10 لكل مليون رمز إدخال و$50 لكل مليون رمز إخراج.
أي طراز أفضل للبرمجة؟
يُعد GPT-5.5 نقطة انطلاق قوية في مجال البرمجة، حيث نشرت OpenAI نتائج اختبارات الأداء الخاصة بالبرمجة ووصفته بأنه نموذج برمجة ذو قدرة على التصرف. وقد يكون Claude Fable 5 أكثر ملاءمة لمراجعة الأكواد ذات السياقات الطويلة، وعمليات الترحيل الكبيرة، والاستدلال المتعلق بالبنى المعقدة.
لماذا نستخدم منصة ذكاء اصطناعي متعددة النماذج؟
تساعد المنصة متعددة النماذج المستخدمين على تجنب إدارة اشتراكات منفصلة. فمن خلال رصيد إعادة شحن واحد، يمكن للمستخدمين الوصول إلى العديد من نماذج الدردشة ونماذج إنشاء الصور ونماذج إنشاء الفيديو في مكان واحد.

