Gemma 3n: Google’s Multimodal AI in Your Pocket
.webp)
Eric Walker · 11, July 2025
On June 26, Google open-sourced Gemma 3n, a multimodal large language model designed from first principles for phones, tablets, and ultraportable laptops. While the last 18 months have been dominated by cloud titans racing to 70-billion-parameter behemoths, Gemma 3n heads in the opposite direction: shrink the network, keep the quality, and make it run entirely on the device you already own.
The idea is more than an engineering flex. Edge-resident AI avoids the latency of network hops, preserves privacy, and, crucially, scales without a matching surge in data-center power draw. If Google can deliver cloud-class reasoning on a handset, it changes the cost curve for both developers and users.
Specs at a Glance
| Item | E2B Variant | E4B Variant |
| Effective parameters loaded to accelerator | ~2 B | ~4 B |
| Total parameters (with PLE off-device) | 5 B | 8 B |
| RAM required | 2 GB | 3 GB |
| Modalities | Image, Audio, Video, Text → Text | |
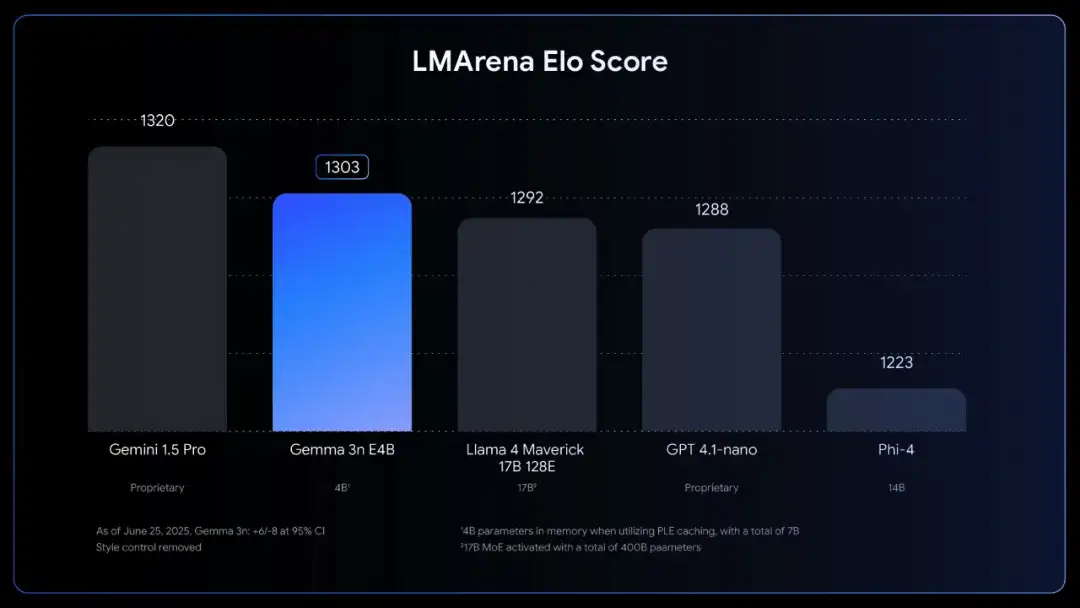
| Benchmark highlight | 1 240 LMArena | 1 302 LMArena (first <10 B model to cross 1 300) |
Google claims both variants fit comfortably inside the neural cores of recent Pixel phones and Apple M-series Macs, with the larger model still leaving headroom for apps and graphics.
MatFormer: The Transformer That Nests Inside Itself
Gemma 3n’s beating heart is MatFormer (Matryoshka Transformer), a nested architecture reminiscent of Russian dolls. Training the 4-billion-effective-parameter model inherently optimizes a 2-billion-parameter sibling tucked inside the same weight file. That design brings two immediate advantages:
- Pre-extraction – Developers can peel out the lighter sub-model to double inference speed on fixed hardware, much as image editors down-sample a photo when bandwidth is tight.
- Mix-n-Match – By surgically slicing feed-forward widths or omitting layers, you can craft bespoke checkpoints that hit almost any VRAM target between E2B and E4B. Google’s forthcoming MatFormer Lab will publish “sweet-spot” recipes validated on MMLU, GSM8K, and Vision-language tasks.
MatFormer also hints at a future elastic execution mode. Imagine a single mobile app that fires up the full E4B path while your phone is plugged in, then throttles down to the lighter E2B path when you drop below 20 % battery. That kind of dynamic quality scaling could become as invisible—and as welcome—as modern CPU Turbo Boost.
PLE: Per-Layer Embeddings That Liberate VRAM
Transformer embeddings are memory hogs, yet they rarely need GPU-class flops. Gemma 3n moves them to the CPU through Per-Layer Embedding (PLE), streaming only the attention and MLP cores to the device NPU or mobile GPU. The trick frees roughly 60% of parameters from costly accelerator memory while keeping tensor bandwidth low enough not to swamp system buses. The upshot: a 5- or 8-billion-parameter model behaves like a 2- or 4-billion-parameter one from the hardware’s point of view, but still thinks like the larger network it really is.
Shared KV Cache: Cut Latency on Long Prompts
Multimodal prompts, whether a two-minute voice note or a stack of video frames, can run thousands of tokens long. Gemma 3n’s Shared Key-Value Cache reuse intermediate attention states across higher layers during the “prefill” pass, slashing time-to-first-token by up to 2× compared with last year’s Gemma-3 4B. For conversational agents or live captioning, that difference is the line between a snappy assistant and an awkward pause.
Audio, First-Class and On-Device
Gemma 3n ships with an encoder distilled from Google’s Universal Speech Model. It emits one latent token every 160 ms, feeding them straight into the language model for reasoning or translation. Out of the box the checkpoint handles 30-second clips, but because the encoder is streamable, longer recordings are simply a matter of fine-tuning.
What This Enables
- ASR anywhere – Turn spoken lectures into searchable text without sending private audio off-device.
- Real-time translation – Gemma 3n already excels at English↔Spanish, French, Italian, and Portuguese. Chain-of-thought prompting—“Think step by step, being faithful to the original idiom”—bumps BLEU and COMET scores another notch.
- Voice agents on airplanes – With no dependency on the cloud, a voice assistant can run offline during a six-hour flight yet still answer the usual requests.
Vision Powered by MobileNet-V5
The visual front-end is brand-new MobileNet-V5-300M, a 300 M-parameter leviathan compared with older MobileNet-V4 variants but still one-tenth the size of desktop vision transformers. Key traits:
- Flexible resolution – Native support for 256 × 256, 512 × 512, and 768 × 768 inputs lets developers trade photorealistic detail for speed.
- 60 fps on Pixel Edge TPU – Enough throughput for real-time video captioning or AR object recognition.
- 4× lower VRAM vs. SoViT – Thanks to distilled token mixers and multi-scale adapters, it actually reduces memory even while adding capacity.
Training was joint on image-text pairs across public and internal datasets, so the encoder is immediately useful for VQA, scene description, or directing the language model to “write alt-text for this Instagram photo.”
Real-World Scenarios
- Private Meetings, Public Transcripts
Corporate compliance teams can hand employees a secure mobile app that runs Gemma 3n locally to transcribe and summarize sensitive board-room audio. No raw recordings ever touch the internet.
- Tourist-Friendly AR Glasses
Pair the vision and audio encoders with bone-conduction speakers and you have smart glasses that read street-signs aloud in your native language or whisper a menu translation in a noisy Madrid café.
- On-Device Movie Summaries
Because the model understands both video and dialogue tracks, a streaming client could download a film, generate a three-paragraph synopsis, and present it offline—handy for travelers juggling spotty Wi-Fi.
Competition Heats Up
The timing is no accident. Apple Intelligence, unveiled just weeks ago, promises comparable on-device reasoning for iOS 18 and macOS Sequoia. Qualcomm is touting 20 tokens per second on a 7 B Llama 2 running wholly on Snapdragon X Elite laptops. Google’s answer is architectural ingenuity: get below 4 B effective parameters without giving up modern multimodal chops.
If anything, the race is nudging chipmakers to expose ever more neural silicon. Samsung’s next Exynos reportedly doubles NPU TOPS over the S24, and MediaTek is shipping notebook-class Dimensity boards with discrete AI accelerators. The hardware-software handshake is tighter than ever.
Limitations and What’s Next
Gemma 3n is not a silver bullet. Conversation length tops out around 32 K tokens, and the model’s world knowledge freezes at early-2025 cut-off unless developers supplement it with an on-device retrieval stack. Fine-tuning, while supported, still needs a desktop-class GPU. And energy draw—though lower than cloud inference—can, can dent phone batteries if used continuously.
Future plans of the team:
- Enable elastic execution in a future point release.
- Open-source smaller MobileNet-V5 variants for ultra-wearables.
- Publish a full technical report on MatFormer, inviting the research community to adapt it for robotics and edge-ML.
Given Gemma’s 160 million-plus cumulative downloads, expect forks, distilled versions, and LoRA overlays to land on GitHub within days.
Visit
GlobalGPT to access Google's advanced models.
Edge AI Comes of Age
Gemma 3n doesn’t win by brute force. It wins by rethinking the stack—shrinking weights with PLE, stacking Russian-doll transformers, caching attention cleverly, and bolting on encoders purpose-built for tight power envelopes. In doing so, Google has thrown down a gauntlet: if you want your AI to feel instantaneous, private, and ubiquitous, it had better run right where the user is.
Edge AI just graduated from curiosity to necessity, and Gemma 3n is the first graduate up on stage.
