Claude Opus 4.1 review: a targeted upgrade for coding and agentic work
.webp)
Eric Walker · 6, August 2025
Anthropic slipped Opus 4.1 out on August 5 with a clear message: fewer “ta-da” launches, more incremental upgrades customers can use today. As CPO Mike Krieger put it in a Bloomberg interview, the team had been “too focused on only shipping the really big upgrades.” The timing also lands the same day OpenAI unveiled its first open-weight reasoning models since 2019, underscoring a fast-moving month in AI.

What’s new in Opus 4.1
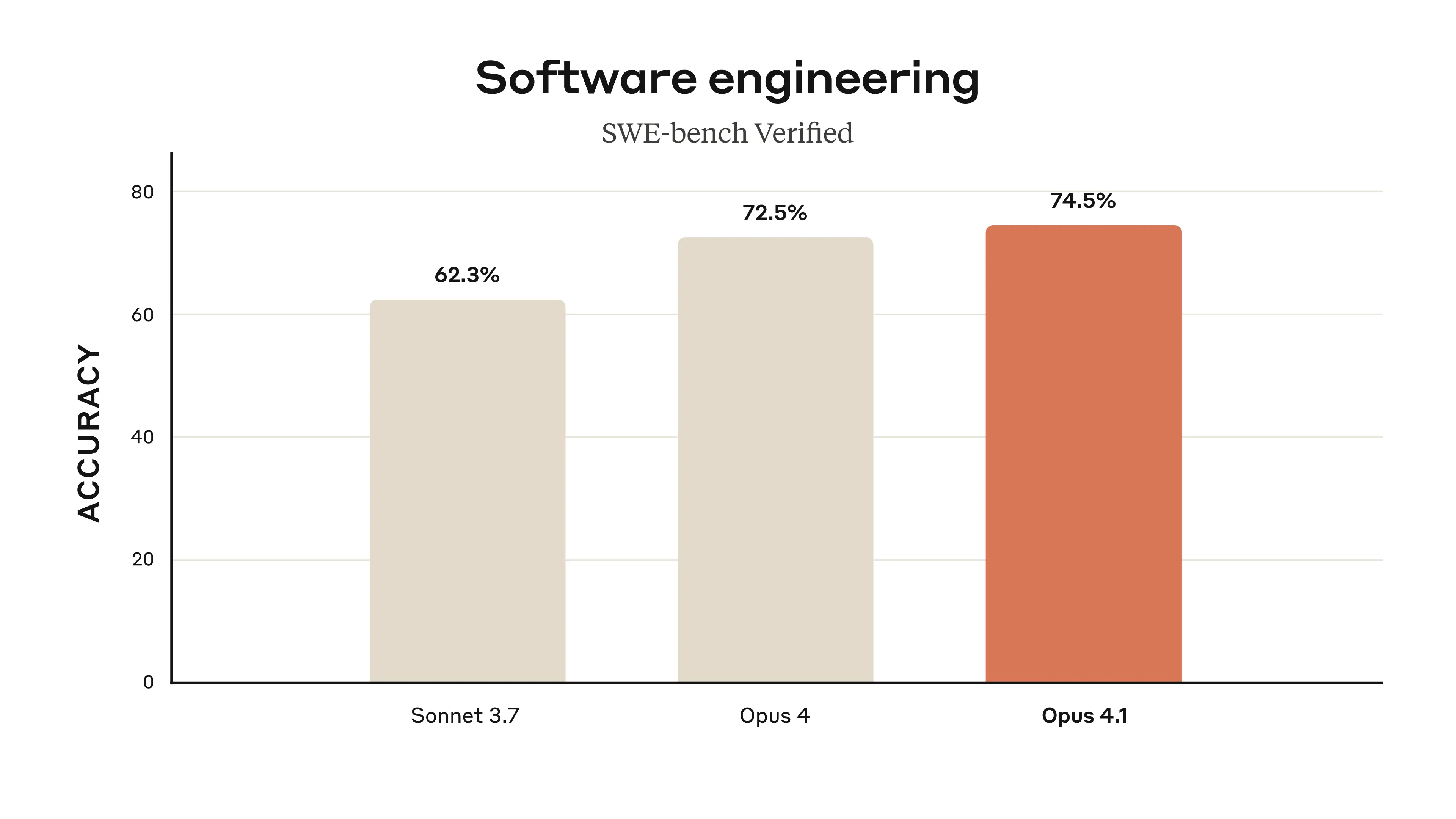
- Stronger real-world coding. Anthropic says Opus 4.1 advances coding performance to 74.5% on SWE-bench Verified (their standard scaffold). Early customer quotes call out better multi-file refactors and fewer unnecessary edits.
- Agentic & terminal work. Multiple trackers report Terminal-Bench at ~43.3% (up from 39.2%), reflecting improved command-line autonomy.
- Pricing & availability unchanged. Same as Opus 4: $15/MTok in, $75/MTok out; available in Claude (Pro/Team/Max/Enterprise), the Anthropic API, Amazon Bedrock, Google Vertex AI, and Claude Code.
- Safety hardening, ASL-3. 4.1 ships under Anthropic’s AI Safety Level 3 standard, with a higher “harmless response rate” on violative prompts (98.76% vs 97.27% on Opus 4).
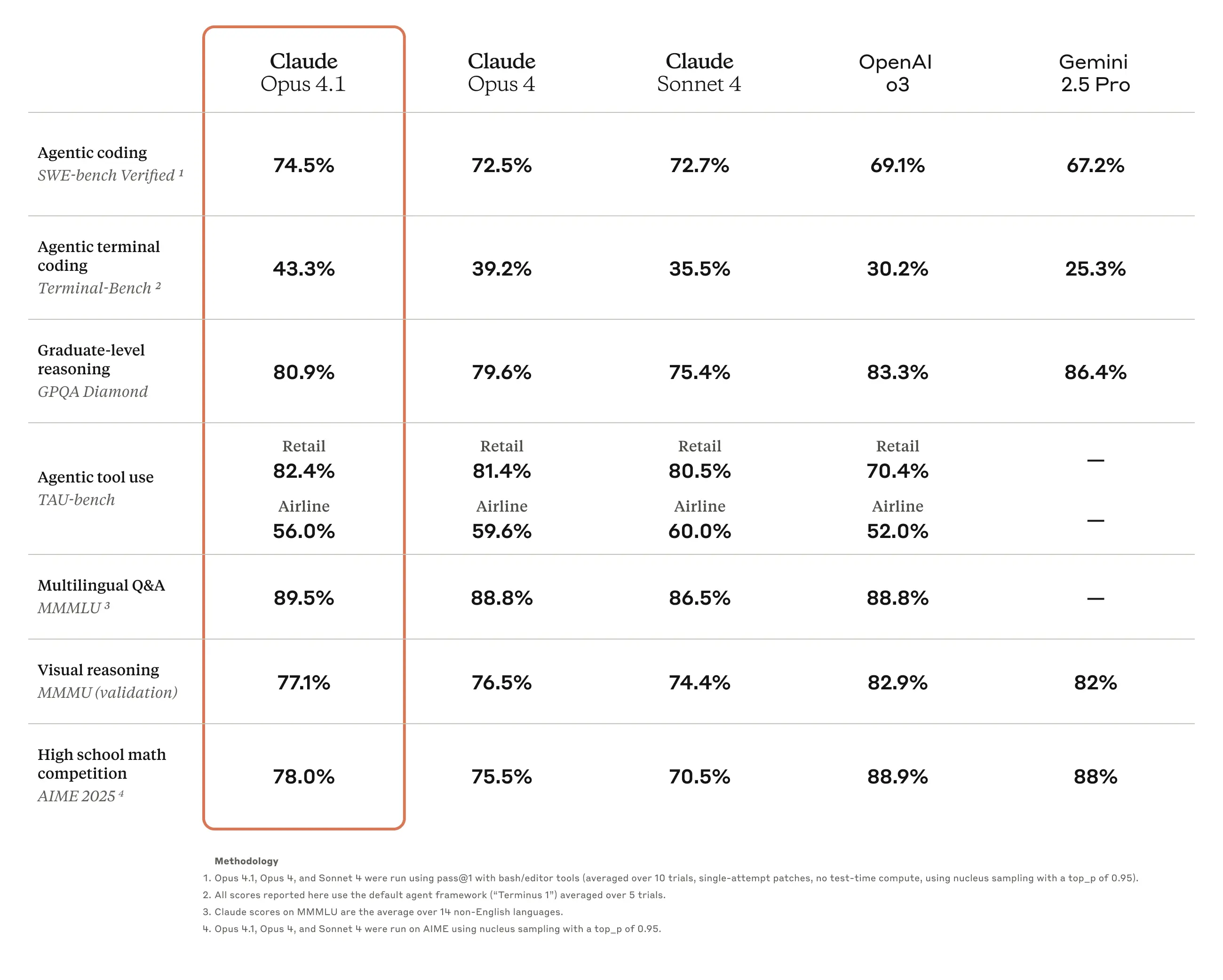
Benchmarks: where 4.1 gains ground (and where it doesn’t)
Coding & agents.
On SWE-bench Verified, Opus 4.1’s 74.5% edges Opus 4 and extends Anthropic’s focus on long-horizon software tasks. Independent summaries and product teams (GitHub, Rakuten, Windsurf) describe exactly the kinds of improvements developers feel: better multi-file changes, fewer side effects, and faster iteration loops.
Terminal-Bench.
Several watchers report 43.3% for Opus 4.1 (vs 39.2% for Opus 4), and note that it leads OpenAI o3 and Gemini 2.5 Pro on this specific agentic terminal test (often quoted as 30.2% and 25.3% respectively). Treat cross-vendor comparisons with care—tooling and scaffolds matter—but the direction of travel is clear.
Reasoning (GPQA, MMMU, AIME).
Opus 4.1’s GPQA Diamond score is frequently cited around 80.9%, solid but behind Google’s Gemini 2.5 Pro (Google’s own report lists 86.4%). Sources disagree on OpenAI o3’s exact GPQA number; public write-ups commonly cite ~83%, while other summaries quote higher. Net-net: Claude’s 4.1 release is optimized for coding/agentic tasks rather than setting a new SOTA on grad-level quiz benchmarks.
Safety and governance: small but meaningful steps
Opus 4.1 keeps Anthropic’s ASL-3 deployment posture and shows an uptick in refusal of harmful requests (overall harmless rate 98.76% vs 97.27% in single-turn tests). Importantly, the company characterizes 4.1 as incremental (not “notably more capable” under its RSP threshold), but still ran voluntary checks—useful color for risk owners who care how fast models are moving.
Pricing, access, and context window
Pricing remains $15/MTok (input) and $75/MTok (output), with big savings available via prompt caching and batch processing. Opus 4.1 is available to paid Claude users, via API, and across Bedrock and Vertex AI; Anthropic positions it as a drop-in upgrade from Opus 4 with a 200K context window and improved support for extended thinking and long outputs (e.g., 32K token generations for code).
Hands-on impressions: who should upgrade
- Upgrade now if your workload is:
(a) day-to-day coding on sizeable repos, (b) multi-file refactors, (c) long-running agents that need to plan, search, and edit reliably, or (d) terminal automation. The 4.1 cycle feels aimed squarely at software teams and agent builders.
- Hold expectations if your priority is only squeezing out leaderboard points on math/vision reasoning; 4.1 is competitive but not dominant on those tests.
Practical tips:
- Turn on prompt caching and consider batch processing for heavy evals or codegen loops to tame costs.
- For agentic pipelines, budget for extended thinking where accuracy matters most, and keep a shorter “fast path” for low-stakes turns.
- If you’re on Opus 4, swap your model ID to
claude-opus-4-1-20250805and monitor diffs in unit tests and CI—most teams report fewer accidental edits.
Free Claude available on GlobalGPT, an all-in-one AI platform.
Market backdrop: the quiet arms race
The release lands as OpenAI ships open-weight “gpt-oss” models and Anthropic reportedly closes in on a $170B valuation in a mega-round led by Iconiq, after ARR accelerated sharply in recent months. In short: everyone’s moving, fast—and Anthropic’s 4.1 drop is about locking in a durable lead in profitable coding and agentic niches while bigger leaps brew.
What’s more
Claude Opus 4.1 isn’t a grand re-architecture; it’s a purposeful tune-up that shows up where many teams actually live—inside terminals, editors, and long-horizon agent loops. If that’s your world, the upgrade feels like a free speed-and-precision bump at the same list price. If your benchmark crown matters more than your build velocity, you may want to wait for the “substantially larger improvements” Anthropic hints are just weeks away.
Relevant Resources
