
لا تنشر OpenAI رقمًا يوميًا ثابتًا لعدد الصور التي يُمكن إنتاجها باستخدام ChatGPT Go. ولا يزال الرقم المفيد للتخطيط يمثل نطاقًا: يُوصف Go رسميًا بأنه أعلى بحوالي 10 أضعاف من الإصدار المجاني (Free) فيما يتعلق بإنشاء الصور، لذا ينبغي للمستخدمين العاديين التخطيط لإنشاء بضع عشرات من الصور يوميًا، ما بين 20 إلى 30 صورة تقريبًا، مع توقع أن تتغير الحدود الفعلية وفقًا لحالة الحساب والطلب وظروف النظام.
وهذا يجعل باقة “Go” ترقية مفيدة للأعمال المتعلقة بالصور التي تتم من حين لآخر، ولكنها لا تُعد خطة إنتاجية مضمونة لكميات كبيرة. فالمواد التي تنشرها OpenAI توفر معلومات عن السعة النسبية وموقع الباقة، ولا تقدم عددًا يوميًا دقيقًا للصور لكل حساب “Go”. لذا، فإن السؤال الأفضل ليس فقط «ما هو الحد الأقصى؟» بل «هل ستناسب هذه الباقة الطريقة التي أقوم بها فعليًّا بإنشاء الصور؟»
يعد ChatGPT Go أقل تقييدًا بكثير من الإصدار المجاني عند استخدام المطالبات اليومية المتعلقة بالصور، لكنه قد يتباطأ أو يتوقف مؤقتًا إذا قمت بإنشاء العديد من الصور في فترة زمنية قصيرة. وبالنسبة للمستخدمين الذين يقارنون بين اشتراكات الذكاء الاصطناعي، فإن الخيار العملي هو تحديد ما إذا كان السعر المنخفض لـ Go كافيًا لأعمال الصور المعتدلة، أم أن مجموعة أدوات أوسع نطاقًا ستوفر المزيد من الوقت.
إذا كانت حدود عدد الصور أحد الأسباب التي تدفعك إلى مقارنة اشتراكات خدمات الذكاء الاصطناعي،, جلوبال جي بي تي تي يُعد خيارًا جديرًا بالاهتمام كمساحة عمل شاملة تعتمد على الذكاء الاصطناعي، خاصةً إذا كان عملك يتجاوز حصة الصور المسموح بها في ChatGPT. فمجموعة أدواته المرئية يمكنها صورة الغلاف تم إنشاؤها باستخدام GPT Image 2،, Nano Banana Pro و Nano Banana 2، بالإضافة إلى العمل على مقاطع الفيديو باستخدام Sora 2 و Kling 3.0 و Wan 2.7 و Seedance 2.0 و Grok Imagine و Veo 3.1. أما الجانب المتعلق بالدردشة والبحث فيمكن أن يظل أكثر بساطة: استخدم GPT أو Claude أو Gemini أو Perplexity لصياغة المطالبات ومقارنة المفاهيم وتنقيح النصوص دون الحاجة إلى تراكم الاشتراكات المنفصلة أو التبديل بين علامات التبويب في كل خطوة.
المحتويات
- ما تقوله OpenAI فعليًّا بشأن حدود الصور في ChatGPT Go
- كم عدد الصور التي يمكنك توقعها يوميًا؟
- ChatGPT Go مقابل الإصدار المجاني مقابل الإصدار Plus: حدود عدد الصور
- تحميل الصور مقابل إنشاء الصور: حدود مختلفة
- حجم ملف الصورة وحدود التحميل مع ChatGPT Go
- كيف تعمل حدود الصور المتحركة في الاستخدام الفعلي
- توافر ChatGPT Go وسعره
- هل يوفر ChatGPT Go توليد صور غير محدود؟
- من الذي ينبغي أن يستخدم ChatGPT Go لإنشاء الصور؟
- نظرة سريعة على حدود الصور في ChatGPT Go
- الأسئلة الشائعة
ما تقوله OpenAI فعليًّا بشأن حدود الصور في ChatGPT Go
تصف صفحة المساعدة الخاصة بخدمة «ChatGPT Go» من OpenAI هذه الخدمة بأنها اشتراك منخفض التكلفة يوفر وصولاً موسعاً إلى ميزات ChatGPT الشائعة. وفيما يتعلق بالعمل على الصور، فإن العبارة الأساسية هي أن خدمة «Go» تتضمن وصولاً موسعاً إلى ميزة إنشاء الصور. وفي نفس مقالة المساعدة، يشير قسم «حدود الاستخدام» إلى أن خطة Go تتمتع بحدود أعلى من خطة Free، وأن هذه الحدود قد تختلف بناءً على ظروف النظام.


يقدم منشور الإطلاق الصادر عن OpenAI مقارنة أكثر تحديدًا: يتضمن ChatGPT Go عددًا من الرسائل وعمليات تحميل الملفات وإنشاء الصور يزيد بنحو 10 أضعاف عن المستوى المجاني. ويُعد هذا الرقم أقوى مؤشر علني لتقدير سعة الصور في فئة Go. ولا يزال هذا الرقم بمثابة مضاعف نسبي، وليس وعدًا بأن يحصل كل حساب على نفس عدد الصور كل يوم تقويمي.
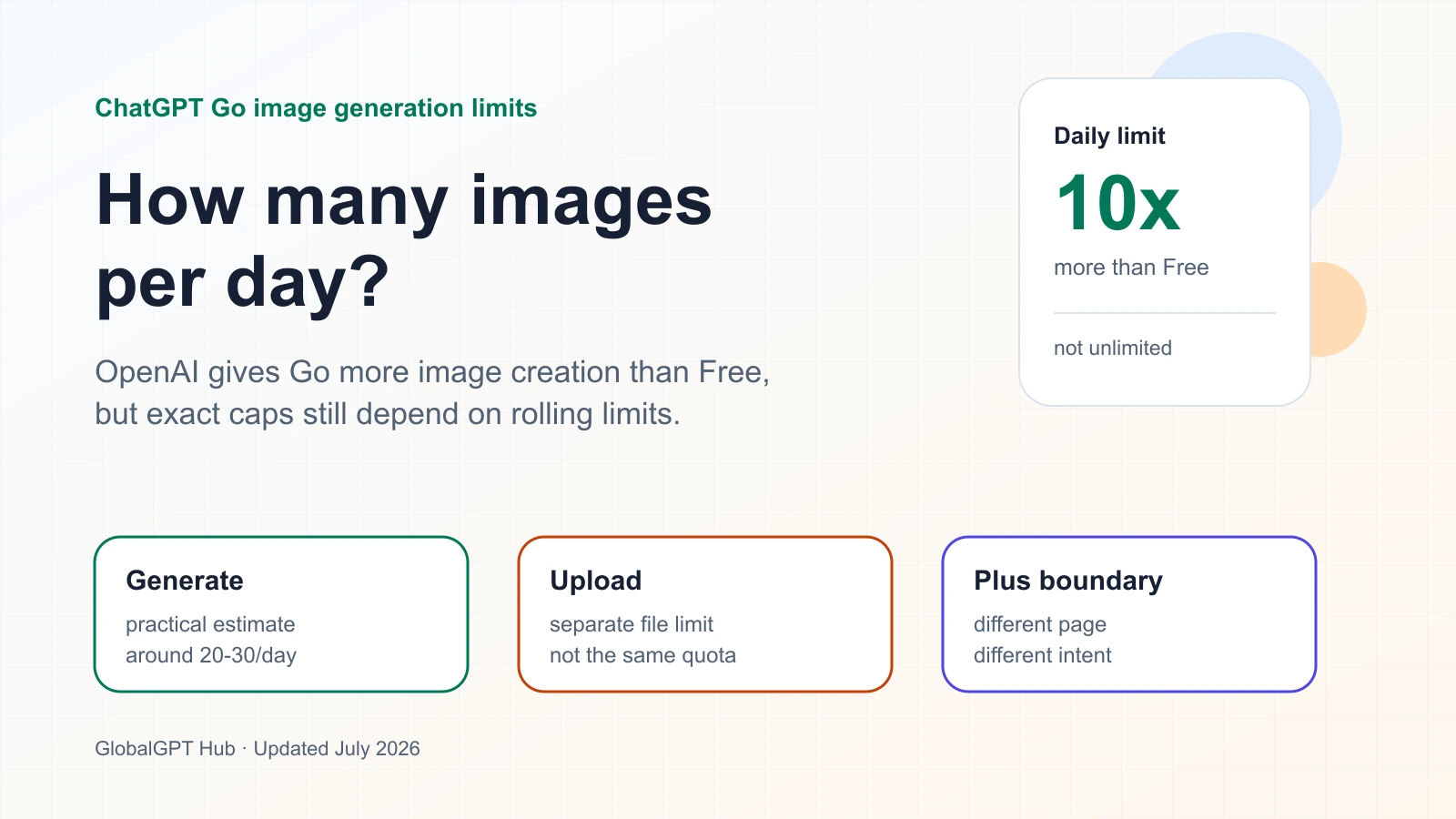
بيانات رسمية
يبلغ الحد المسموح به الذي نشرته OpenAI لإنشاء الصور 10 أضعاف الحد المسموح به في الفئة المجانية
هذا هو الرقم العام الأكثر دقة لتقدير قيمة Go. وهو يدعم نطاق عمل يومي أكبر من الإصدار المجاني، لكنه لا ينشئ عدادًا يوميًا ثابتًا.
المصدر: OpenAI، “تقديم ChatGPT Go”، تم الاطلاع عليه في 13 يوليو 2026. ويشمل الرقم «10x» الرسائل وتحميل الملفات وإنشاء الصور مقارنة بالإصدار المجاني.
الاستنتاج العملي بسيط: تؤكد OpenAI أن باقة “Go” تتيح إنشاء عدد أكبر من الصور مقارنة بباقة «Free»، وأن الحدود المسموح بها في كل باقة قد تختلف. وهي لا تؤكد رقمًا عامًا ثابتًا مثل «30 صورة يوميًا لكل حساب Go».”
كم عدد الصور التي يمكنك توقعها يوميًا؟
لأغراض التخطيط، توقع أن يكون ChatGPT Go قادرًا على إنتاج بضع عشرات من الصور يوميًا دون مشكلة. وأنا أعتبر أن 20 إلى 30 صورة هي النطاق العملي ليوم عادي، خاصةً إذا قمت بتوزيع الطلبات بدلاً من إرسال دفعة واحدة كبيرة.
يُعد هذا النطاق مفيدًا لأنه يتوافق مع الطريقة التي يخطط بها الناس فعليًّا لعملهم المتعلق بالصور: المفهوم، والتنوع، والاختيار، وبعض التعديلات. قد تلاحظ سعة أكبر خلال الفترات الهادئة، وأقل خلال فترات الطلب المرتفع، وتجربة مختلفة إذا قامت OpenAI بتغيير حدود الخطط. ويستند هذا التقدير علنًا إلى تصنيف OpenAI لـ «المستوى المجاني 10x»، وليس إلى الحد الأقصى اليومي المنشور لـ «Go-only».
| سؤال | أفضل إجابة | الثقة |
|---|---|---|
| هل تتضمن لغة Go إمكانية إنشاء الصور؟ | نعم. تدرج OpenAI الوصول الموسع إلى ميزة إنشاء الصور ضمن لغة Go. | تم التحقق منه رسميًا |
| هل هناك حد أقصى يومي محدد للجمهور؟ | لم يتم نشر أي رقم مخصص حصريًّا للعبة «Go» في صفحة المساعدة العامة الخاصة بـ OpenAI. | تم التحقق منها رسميًا من خلال صياغة «الغياب» و«القيود» |
| ما هو الرقم اليومي الذي يجب أن تضع خططك بناءً عليه؟ | ما يقارب 20 إلى 30 صورة يوميًا في حالة الاستخدام المعتدل. | تقدير عملي |
فيما يتعلق بأعمال العملاء أو الحملات التسويقية، أقوم بتقسيم الدفعة إلى مراحل: مرحلة أولية لوضع المفهوم، ومرحلة صقل التفاصيل، ومرحلة نهائية لتنويع التصاميم. وهذا يحافظ على فائدة برنامج Go دون الاعتماد على عملية طويلة ومتواصلة لتوليد الصور.
ChatGPT Go مقابل الإصدار المجاني مقابل الإصدار Plus: حدود عدد الصور
أهم مقارنة هي بين الإصدار «Free» والإصدار «Go». يُعد الإصدار «Free» مناسبًا لاختبارات الصور العرضية، لكن OpenAI تصف إنشاء الصور في الإصدار «Free» بأنه محدود وأبطأ. أما الإصدار «Go» فهو الخيار الاقتصادي لمن يرغبون في الحصول على مساحة كافية للمطالبات المنتظمة دون الانتقال مباشرةً إلى الإصدار «Plus».
تأتي فئتا «Plus» و«Pro» في مرتبة أعلى من فئة «Go». في صفحة الأسعار التي اطلعت عليها، تركز فئة «Plus» على إنشاء صور أكثر تعقيدًا ودقة، بينما تركز فئة «Pro» على إنشاء أكبر عدد ممكن من الصور بأسرع وقت ممكن. وهذا يوضح لك كيفية فهم هذه الفئات: فئة «Go» مخصصة للاستخدام العادي بسعر أقل، بينما تركز فئتا «Plus» و«Pro» على سير العمل الأكثر تعقيدًا في مجال إنشاء الصور الذي تقدمه OpenAI.
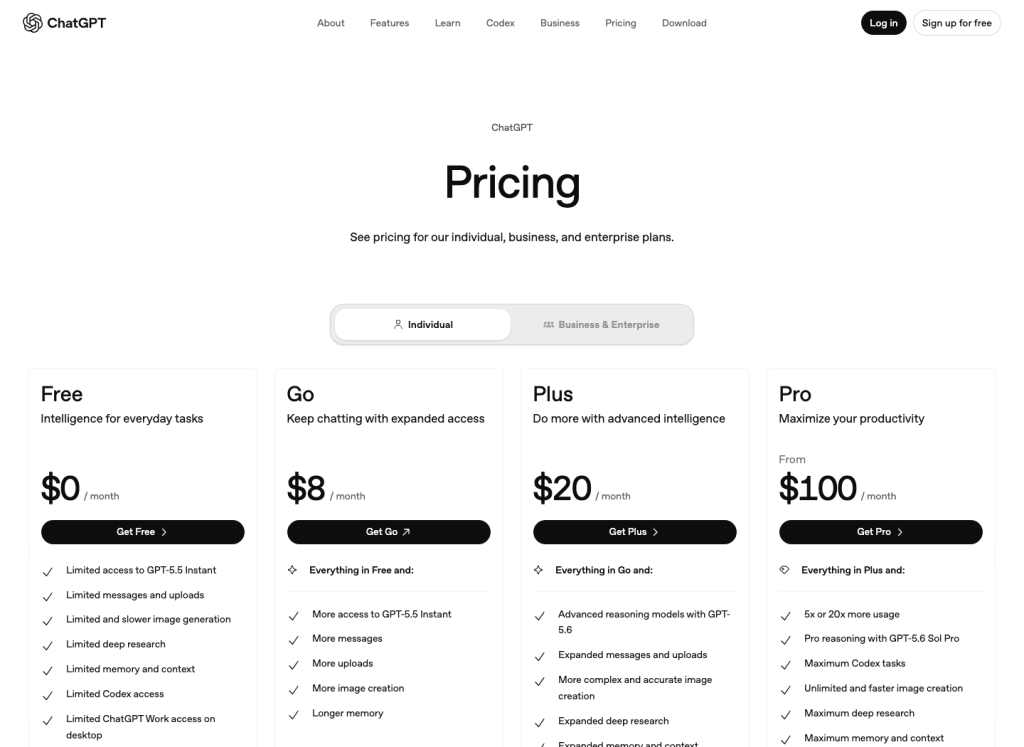
نظرة عامة على الأسعار في الولايات المتحدة
الفرق في السعر بين إصدار «Go» وإصدار «Plus» ضئيل؛ أما الفرق في سير العمل فهو السؤال الحقيقي
في صفحة الأسعار الأمريكية التي تم الرجوع إليها لإجراء هذا التحديث، تبلغ تكلفة باقة «Go» $8 شهريًّا، وباقة «Plus» $20 شهريًّا، بينما تبدأ باقة «Pro» بسعر أعلى بكثير. إذا كنت تحتاج فقط إلى بضع عشرات من عمليات إنشاء الصور، فإن باقة Go هي الخيار الأقل تكلفة للتجربة. أما إذا كان العمل على الصور جزءًا من مهامك اليومية، فقارن بين القيود المفروضة على الاستخدام وفارق السعر.
المصدر: صفحة أسعار ChatGPT، لقطة شاشة للنسخة الأمريكية بتاريخ 13 يوليو 2026. قد تختلف الأسعار المحلية حسب السوق والحساب.
| الخطة | ملاءمة توليد الصورة | كيفية استخدام هذا في اتخاذ القرارات في لعبة «Go» |
|---|---|---|
| مجاناً | اختبارات إضاءة وصور متفرقة. | قم بالترقية إذا كنت تواجه الحدود القصوى بعد بضع محاولات فقط. |
| ChatGPT Go | إنشاء الصور يوميًا بسعر أقل. | استخدم التقدير الذي يتراوح بين 20 و30 يوميًا كنطاق تخطيطي للاستخدام المعتدل. |
| بالإضافة إلى | أعمال معالجة الصور الأكثر تعقيدًا وتطورًا. | قارن مع «Plus» إذا كانت الحدود المتغيرة في «Go» تعيق سير عملك. |
| محترف | إنشاء الصور للمستخدمين المتقدمين وسير العمل الأوسع نطاقًا ذات الاستخدام المكثف. | لا تستخدم الإصدار «Pro» كمعيار مقارنة مع اشتراك «Go» الاقتصادي. |
إذا كان سؤالك يتعلق بـ «Plus» تحديدًا، فاستخدم دليل حدود الصور في ChatGPT Plus. إذا كان سؤالك هو ما إذا كان بإمكان «Go» إنشاء صور أصلاً، فابدأ بـ دليل قدرات ChatGPT Go في إنشاء الصور. تتناول هذه الصفحة موضوع الكمية والحدود في لعبة «غو».
تحميل الصور مقابل إنشاء الصور: حدود مختلفة
يخلط الكثير من الناس بين ثلاثة أفعال مختلفة:
- إنشاء صورة يعني أن تطلب من ChatGPT إنشاء صورة جديدة بناءً على موجه.
- تحميل صورة يعني إرفاق صورة موجودة حتى يتمكن ChatGPT من فحصها أو وصفها أو تعديلها.
- تحميل ملف ويمكن أن تشمل المستندات وجداول البيانات والعروض التقديمية وملفات PDF والصور.
تؤكد صفحة المساعدة الخاصة بـ «ChatGPT Images» التابعة لـ OpenAI أن ChatGPT قادر على إنشاء الصور وتحريرها. أما الأسئلة الشائعة المتعلقة بتحميل الملفات فهي مصدر مختلف، لأن حدود التحميل تختلف عن حدود الإنشاء.
هذا التمييز مهم عندما تخطط لتنفيذ مجموعة حقيقية من المهام. فإذا قمت بتحميل 15 صورة منتج للتحليل، فأنت تستخدم سعة التحميل. أما إذا طلبت من ChatGPT إنشاء 15 فكرة إعلانية جديدة، فأنت تستخدم سعة إنشاء الصور. قد يفرض نفس اشتراك ChatGPT قيودًا على كليهما، لكنهما ليسا نفس الإجراء.
حجم ملف الصورة وحدود التحميل مع ChatGPT Go
بالنسبة للملفات التي يتم تحميلها، تنشر OpenAI حدودًا أكثر وضوحًا مقارنةً بالصور التي يتم إنشاؤها باستخدام Go فقط. تحدد الأسئلة الشائعة حول تحميل الملفات حدًا أقصى ثابتًا يبلغ 512 ميجابايت للعديد من الملفات المُحمَّلة، وحدًا أقصى يبلغ 20 ميجابايت لملفات الصور، وما يصل إلى 80 عملية تحميل للملفات كل 3 ساعات، وحدًا يوميًا أقل للتحميل للمستخدمين المجانيين. وتشير OpenAI أيضًا إلى أن حدود التحميل قد يتم تخفيضها خلال ساعات الذروة.

حدود التحميل منفصلة
تكشف OpenAI عن أرقام تحميل الملفات، وليس عن عداد الصور المولدة بواسطة Go حصريًّا
تساعد هذه الحدود في عملية تحميل الصور وتحليل الملفات. لكنها لا تحدد عدد الصور الجديدة التي سيقوم ChatGPT Go بإنشائها في اليوم الواحد.
المصدر: الأسئلة الشائعة حول تحميل الملفات على OpenAI، تم التحقق منها في 13 يوليو 2026.
بالنسبة لمستخدمي ChatGPT Go، فإن المقصود عمليًّا هو ما يلي: توفر نسخة Go مساحة تحميل أكبر مقارنةً بالإصدار المجاني، لكن عمليات التحميل تظل محدودة، وينبغي أن تظل حدود الصور التي يتم تحميلها منفصلة عن الحصة اليومية المخصصة للصور التي يتم إنشاؤها.
كيف تعمل حدود الصور المتحركة في الاستخدام الفعلي
من الأسهل فهم حدود الصور في ChatGPT على أنها «فترات استخدام متجددة» بدلاً من «إعادة ضبط عند منتصف الليل». فقد يمر يوم المستخدم الذي يُنشئ ثماني صور في الصباح، وثماني صور في فترة ما بعد الظهر، وست صور في المساء، بشكل أكثر سلاسة مقارنة بالمستخدم الذي يحاول إنشاء 40 صورة متتالية.
قد يبدو سير العمل الواقعي في لعبة «غو» كما يلي:
- الصباح: 6-10 صور لاستكشاف الفكرة.
- بعد الظهر: 6-10 صور لتنقيح الأسلوب أو التصميم أو توجيهات النص.
- في المساء: 4-8 صور للتنويعات النهائية.
وهذا يقع ضمن نطاق التخطيط الذي يتراوح بين 20 و30 صورة، دون افتراض أن الخطة غير محدودة. وإذا تعثرت إحدى الدفعات، فإن الخطوة الأكثر فائدة هي التوقف مؤقتًا، وحفظ الموجه الأقوى، والعودة لاحقًا بطلب تنويع أكثر تحديدًا.
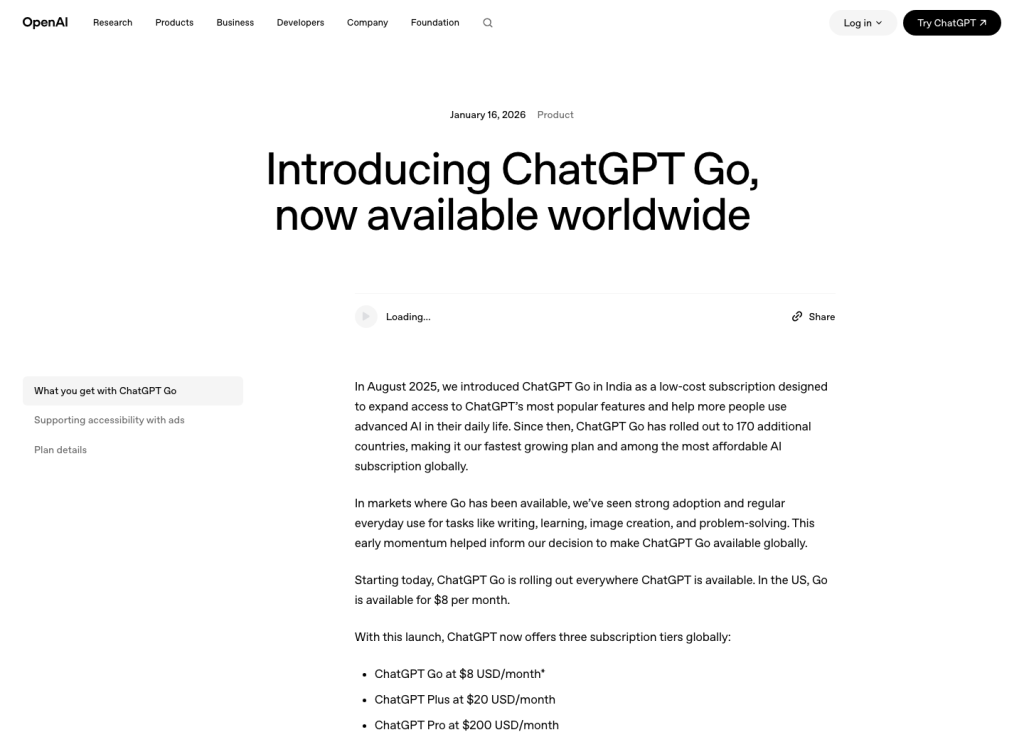
توافر ChatGPT Go وسعره
اعتبارًا من 13 يوليو 2026، تشير صفحة المساعدة الخاصة بـ ChatGPT Go التابعة لـ OpenAI إلى أن خدمة Go متاحة في جميع البلدان التي يدعمها ChatGPT. وتوجه صفحة المساعدة نفسها المستخدمين إلى صفحة أسعار ChatGPT للاطلاع على أسعار الاشتراكات الحالية. ويذكر منشور الإطلاق الصادر عن OpenAI أن السعر في الولايات المتحدة يبلغ $8 شهريًا، ويشير إلى أن أسعار Go يتم تكييفها وفقًا للأسواق المحلية في بعض المناطق.
فيما يتعلق بالأسعار، هناك قاعدتان عمليتان:
- استخدم $8/شهر عندما تشير تحديدًا إلى الأسعار في الولايات المتحدة.
- بالنسبة للقراء من خارج الولايات المتحدة، يرجى استخدام السعر الوارد في صفحة التسعير الرسمية لـ ChatGPT أو في إجراءات ترقية الحساب الخاصة بهم.
لإجراء مقارنة أسعار أكثر تفصيلاً، استخدم دليل أسعار ChatGPT Go الكامل. بالنسبة للأسئلة المتعلقة بالوصول على المستوى الإقليمي، فإن دليل التوافر في الولايات المتحدة تعد هذه القراءة التالية مفيدة.
هل يوفر ChatGPT Go توليد صور غير محدود؟
لا. لا يوفر ChatGPT Go إمكانية إنشاء صور غير محدودة. فهو خطة ذات تكلفة أعلى من الخطة المجانية، لكن إنشاء الصور لا يزال يمثل عبئًا أكبر من الدردشة النصية العادية، وتقوم OpenAI بإدارته من خلال حدود الخطة، والنوافذ الدورية، والتغييرات المؤقتة خلال فترات ارتفاع الطلب.
ولهذا السبب، فإن عبارة “10 أضعاف الإصدار المجاني” يمكن أن تمثل ترقية ذات قيمة، ومع ذلك قد لا تكون كافية لمنشئي المحتوى ذوي الحجم الكبير. إذا كنت تحتاج فقط إلى صور لمشاريع دراسية، أو عناصر بصرية للمدونة، أو مفاهيم تسويقية بسيطة، أو أفكار تصميم شخصية، فقد تبدو خطة «Go» سخية. أما إذا كنت تحتاج إلى العديد من الموارد النهائية يوميًا، فإن العوائق المتعلقة بالحد الأقصى تكتسب أهمية أكبر من السعر المعلن.
إذا كنت ترغب في فهم المفاضلات الأوسع نطاقًا التي تتجاوز حدود الصورة، فاقرأ مزايا وقيود ChatGPT Go تعطل أو ChatGPT Go مقابل مجاناً المقارنة.
من الذي ينبغي أن يستخدم ChatGPT Go لإنشاء الصور؟
يُعد ChatGPT Go الخيار الأمثل للمستخدمين الذين يقومون بإنشاء الصور بانتظام، ولكن ليس على نطاق إنتاجي. وهو مناسب للطلاب، والمبدعين الهواة، والمسوقين الصغار، والمدونين، والأشخاص الذين يرغبون في الحصول على مساحة أكبر من تلك المتوفرة في الإصدار المجاني دون الحاجة إلى دفع تكاليف الاشتراك في فئة أعلى من ChatGPT.
وهو أقل ملاءمة للمستخدمين الذين يحتاجون إلى إنتاج ضخم يمكن التنبؤ به، أو العديد من الاختلافات في نفس اليوم، أو مزيج من نماذج الصور والفيديو. وهنا يبدأ سير العمل متعدد النماذج في أن يُنظر إليه باعتباره وسيلة لتوفير الوقت أكثر منه رفاهية. على سبيل المثال، GlobalGPT’s مساحة عمل GPT Image 2 يمكن أن تُستخدم جنبًا إلى جنب مع أدوات أخرى للصور والفيديو والدردشة، في حين أن صفحة أسعار GlobalGPT هو المكان المناسب لمقارنة باقاتها.
يعتمد الاختيار الصحيح على حجم العمل الفعلي لديك. اختر باقة «Go» إذا كنت تريد ترقية أرخص لـ ChatGPT لاستخدام معتدل للصور. اختر باقة أعلى أو أوسع نطاقًا إذا كان عملك يعتمد على عدد كبير من الصور، أو نماذج متعددة، أو تقليل الانقطاعات خلال يوم العمل.
نظرة سريعة على حدود الصور في ChatGPT Go
| سؤال | أفضل إجابة |
|---|---|
| كم عدد الصور التي يمكن لـ ChatGPT Go إنشاؤها يوميًا؟ | خطط لاستخدام ما بين 20 و30 صورة يوميًا في حالة الاستخدام المعتدل، لكن اعتبر هذا الرقم تقديريًّا. |
| هل تنشر OpenAI حدًا أقصى ثابتًا لحجم صور Go؟ | لا يوجد رقم علني للصورة اليومية الخاصة بلعبة «Go» فقط مدرج في صفحة المساعدة. |
| هل لعبة «Go» غير محدودة؟ | لا. تبلغ الحدود القصوى في إصدار «Go» مستويات أعلى من تلك الموجودة في إصدار «Free»، لكن هذه الحدود قد تختلف. |
| هل ينطبق الحد نفسه على عمليات التحميل والصور التي يتم إنشاؤها؟ | لا. إن تحميل صورة وإنشاء صورة جديدة هما عمليتان مختلفتان. |
| هل برنامج «Go» كافٍ للقيام بالأعمال الإبداعية اليومية؟ | عادةً ما يكون الجواب «نعم» في حالة الاستخدام المعتدل، ولكن ليس في حالة الإنتاج بكميات كبيرة. |
الأسئلة الشائعة
هل تنشر OpenAI الحد اليومي الدقيق لعدد الصور التي يمكن لـ ChatGPT Go إنشاؤها؟
لا. تعلن شركة OpenAI علنًا أن إصدار «ChatGPT Go» يتيح إنشاء عدد أكبر من الصور مقارنة بالإصدار «Free»، بالإضافة إلى حدود استخدام أعلى، لكنها لا تنشر رقمًا يوميًا ثابتًا لعدد الصور المسموح به حصريًّا في إصدار «Go». وقد تختلف هذه الحدود بناءً على ظروف النظام.
كم عدد الصور التي ينبغي أن أخطط لإنشائها باستخدام ChatGPT Go يوميًا؟
يُقدَّر العدد العملي للتخطيط بحوالي 20-30 صورة يوميًا في حالة الاستخدام المعتدل. استخدم هذا الرقم كنطاق تقريبي استنادًا إلى الحد الأقصى المسموح به في Go، وليس كضمان رسمي.
هل خدمة ChatGPT Go توفر إمكانية غير محدودة لإنشاء الصور؟
لا. خدمة ChatGPT Go ليست غير محدودة. إنها خطة مدفوعة بتكلفة معقولة وتتمتع بسعة أكبر من الخطة المجانية، لكن إنشاء الصور لا يزال يخضع لحدود الخطة وفترات الاستخدام المتجددة.
كم عدد الصور التي يمكنني تحميلها على ChatGPT Go؟
يختلف تحميل الصور عن إنشاء الصور. تذكر الأسئلة الشائعة حول تحميل الملفات الخاصة بـ OpenAI حدًا أقصى يبلغ 20 ميغابايت لكل ملف صورة، بالإضافة إلى حدود أخرى للتحميل، في حين أن Go نفسها توفر سعة تحميل أكبر من الإصدار المجاني. يجب الفصل بين حدود التحميل والتخطيط المتعلق بالصور التي يتم إنشاؤها.
هل تطبق خدمة ChatGPT Go نفس قيود الصور المطبقة على ChatGPT Plus؟
لا. «Go» و«Plus» هما فئتان منفصلتان. ففئة «Plus» مخصصة للأعمال الأكثر كثافة وتطوراً، بينما تُعد فئة «Go» ترقية أقل تكلفة من الإصدار المجاني.
هل تطبيق ChatGPT Go متوفر في بلدي؟
تشير صفحة المساعدة الخاصة بـ ChatGPT Go التابعة لـ OpenAI إلى أن لغة Go متاحة في جميع البلدان التي يدعمها ChatGPT اعتبارًا من 13 يوليو 2026. ومع ذلك، قد يظل توفر الخدمة والأسعار المحلية رهنًا بما يظهر في حسابك على ChatGPT وصفحة الأسعار الرسمية.
هل يجب أن أختار ChatGPT Go أم منصة متعددة النماذج للصور؟
اختر ChatGPT Go إذا كنت تبحث بشكل أساسي عن ترقية أرخص لـ ChatGPT من أجل إنشاء صور بكميات معتدلة. أما إذا كان سير عملك يتطلب أيضًا نماذج دردشة أخرى، أو أدوات بحث، أو نماذج صور، أو إنشاء مقاطع فيديو في مكان واحد، ففكر في استخدام منصة متعددة النماذج.

