
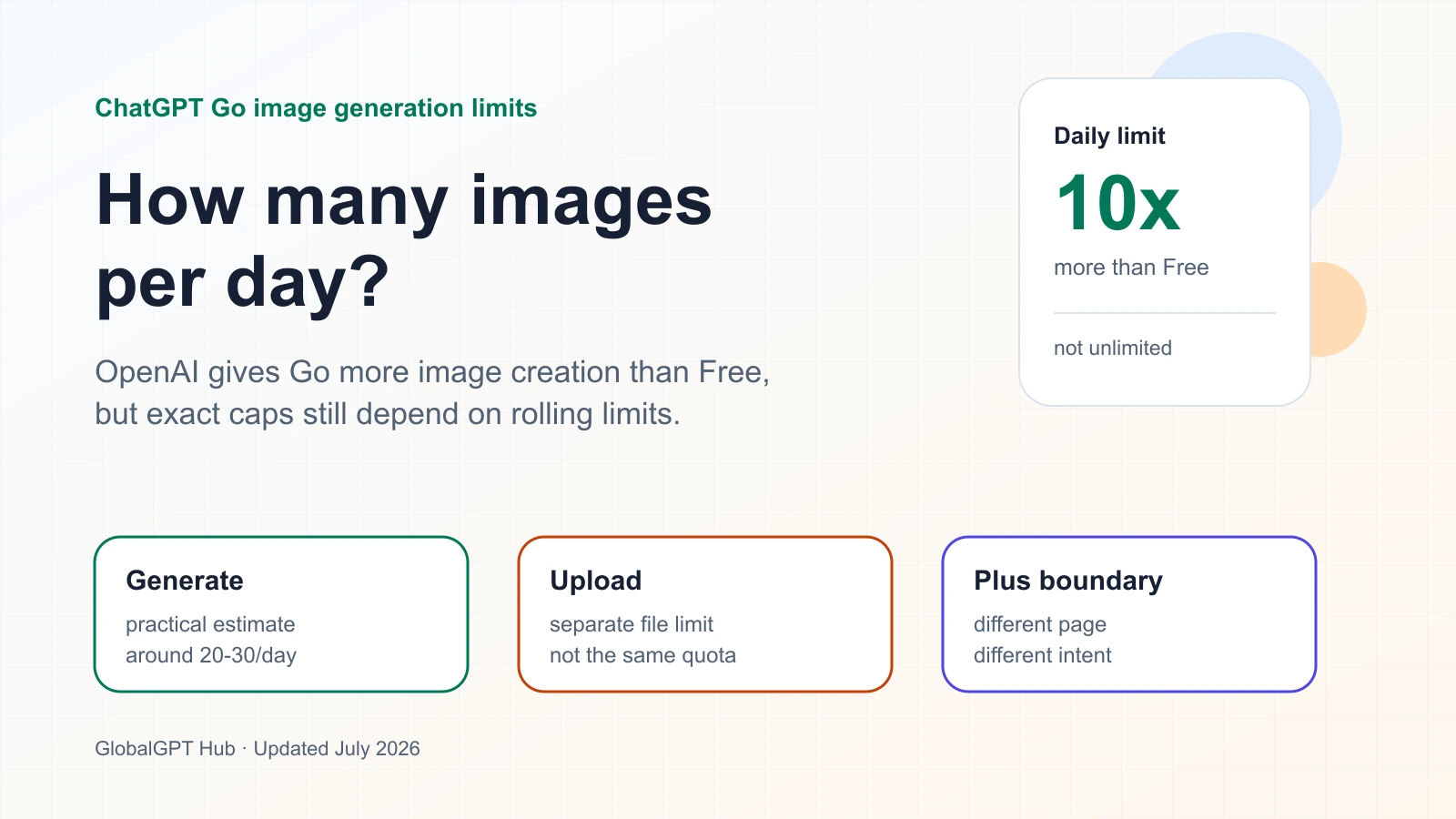
OpenAI does not publish one fixed daily image-generation number for ChatGPT Go. The useful planning number is still a range: Go is officially described as about 10x higher than Free for image creation, so moderate users should plan around a few dozen images per day, roughly 20-30, while expecting real limits to move with account status, demand, and system conditions.
That makes Go a meaningful upgrade for occasional image work, but not a predictable high-volume production plan. OpenAI’s public materials give relative capacity and plan positioning, not a neat daily image counter for every Go account. So the better question is not only “what is the cap?” but “will this plan fit the way I actually create images?”
ChatGPT Go is much less restrictive than Free for everyday image prompts, but it can still slow down or stop temporarily if you generate many images in a short burst. For users comparing AI subscriptions, the practical choice is whether Go’s lower price is enough for moderate image work or whether a broader toolset would save more time.
If image limits are one reason you are comparing AI subscriptions, GlobalGPT is worth considering as an all-in-one AI workspace, especially if your work goes beyond one ChatGPT image quota. Its visual-tool lineup can cover image work with GPT Image 2, Nano Banana Pro, and Nano Banana 2, plus video work with Sora 2, Kling 3.0, Wan 2.7, Seedance 2.0, Grok Imagine, and Veo 3.1. The chat and research side can stay simpler: use GPT, Claude, Gemini, or Perplexity to draft prompts, compare concepts, and clean up copy without stacking separate subscriptions or switching tabs for every step.
目录
- What OpenAI Actually Says About ChatGPT Go Image Limits
- How Many Images per Day Should You Expect?
- ChatGPT Go vs Free vs Plus Image Limits
- Uploading Images vs Generating Images: Different Limits
- Image File Size and Upload Limits with ChatGPT Go
- How Rolling Image Limits Work in Real Use
- ChatGPT Go Availability and Price
- ChatGPT Go 是否提供无限图像生成?
- Who Should Use ChatGPT Go for Image Generation?
- ChatGPT Go Image Limits at a Glance
- 常见问题
What OpenAI Actually Says About ChatGPT Go Image Limits
OpenAI’s ChatGPT Go help page describes Go as a low-cost subscription with expanded access to popular ChatGPT features. For image work, the key wording is that Go includes extended access to image generation. In the same help article, the usage-limits section says Go has higher limits than Free, and that those limits can vary based on system conditions.


OpenAI’s launch post gives a more concrete comparison: ChatGPT Go includes about 10x more messages, file uploads, and image creation than the Free tier. That number is the strongest public signal for estimating Go’s image capacity. It is still a relative multiplier, not a promise that every account receives the same number of images every calendar day.
Official data point
OpenAI’s published Go allowance is 10x the Free tier for image creation
This is the cleanest public number for estimating Go. It supports a bigger daily working range than Free, but it still does not create a fixed daily counter.
Source: OpenAI, “Introducing ChatGPT Go,” checked July 13, 2026. The 10x figure covers messages, file uploads, and image creation versus Free.
The practical takeaway is simple: OpenAI confirms that Go gets more image creation than Free and that plan limits can vary. It does not confirm a stable public number such as “30 images every day for every Go account.”
How Many Images per Day Should You Expect?
For planning purposes, expect ChatGPT Go to be comfortable for a few dozen image generations per day. I would use 20-30 images as the working range for a normal day, especially if you spread requests out instead of sending one large batch.
The range is useful because it matches how people actually plan image work: concept, variation, selection, and a few revisions. You may see more capacity during quiet periods, less during heavy demand, and a different experience if OpenAI changes plan limits. The public basis for the estimate is OpenAI’s 10x Free-tier positioning, not a published Go-only daily cap.
| 问题 | Best answer | Confidence |
|---|---|---|
| Does Go include image generation? | Yes. OpenAI lists extended access to image generation for Go. | 官方核实 |
| Is there a fixed public daily cap? | No fixed Go-only number is published in OpenAI’s public help page. | Officially verified by absence and limits wording |
| What daily number should you plan around? | Roughly 20-30 images per day for moderate use. | Practical estimate |
For client or campaign work, I would split the batch into stages: a small concept pass, a refinement pass, and a final variation pass. That keeps Go useful without depending on a long uninterrupted run of image generations.
ChatGPT Go vs Free vs Plus Image Limits
The most important comparison is Free vs Go. Free is fine for occasional image tests, but OpenAI labels Free image generation as limited and slower. Go is the budget tier for people who want enough room for regular prompts without jumping straight to Plus.
Plus and Pro sit above Go. On the pricing page I checked, Plus is framed around more complex and accurate image creation, while Pro is framed around maximum and faster image creation. That tells you how to read the tiers: Go is for regular use at a lower price, while Plus and Pro are where OpenAI pushes heavier image workflows.
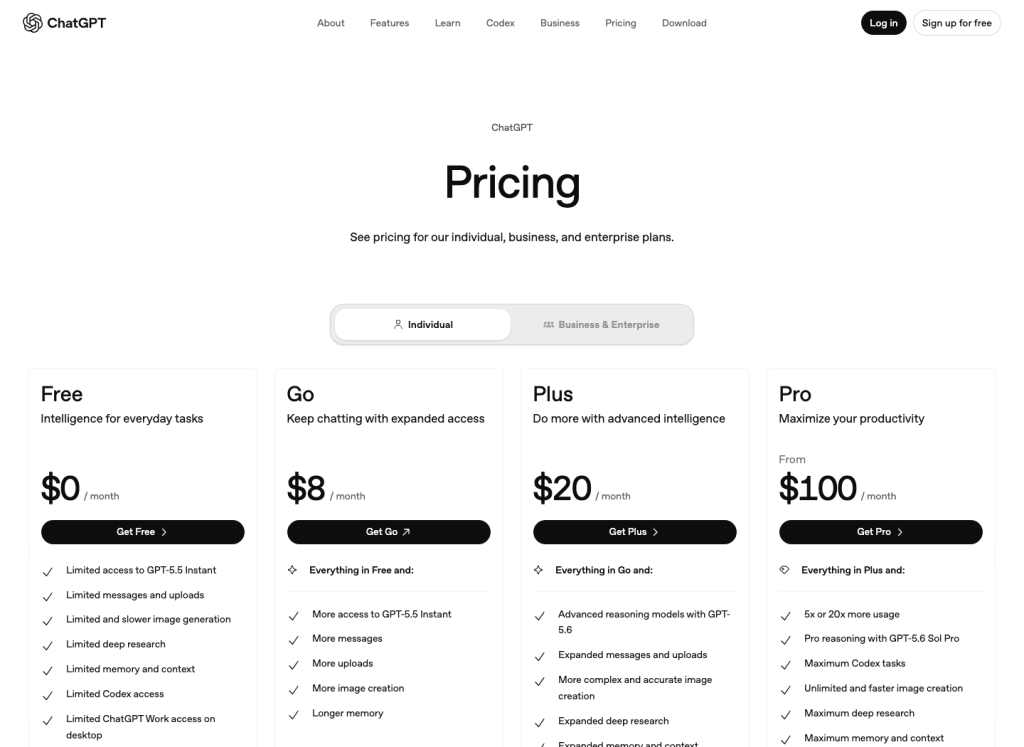
US pricing view
The price jump from Go to Plus is small; the workflow jump is the real question
On the US pricing page checked for this update, Go sits at $8/month, Plus at $20/month, and Pro starts much higher. If you only need a few dozen image generations, Go is the lower-cost experiment. If image work is part of a daily job, compare the limit friction against the price difference.
Source: ChatGPT Pricing page, US view captured July 13, 2026. Local pricing can differ by market and account.
| 计划 | Image generation fit | How to use this for Go decisions |
|---|---|---|
| 免费 | Light tests and occasional images. | Upgrade if you keep hitting limits after only a few tries. |
| 聊天GPT Go | Everyday image creation at a lower price. | Use the 20-30/day estimate as a moderate-use planning range. |
| 加 | Heavier and more advanced image work. | Compare Plus if Go’s rolling limits interrupt your workflow. |
| 专业 | Power-user image creation and broader high-usage workflows. | Do not use Pro as a benchmark for a budget Go subscription. |
If your question is specifically about Plus, use the separate ChatGPT Plus image limit guide. If your question is whether Go can create images at all, start with the ChatGPT Go image generation capability guide. This page is about Go’s quantity and limits.
Uploading Images vs Generating Images: Different Limits
Many people mix up three different actions:
- Generating an image means asking ChatGPT to create a new image from a prompt.
- Uploading an image means attaching an existing image so ChatGPT can inspect, describe, or edit it.
- Uploading a file can include documents, spreadsheets, presentations, PDFs, and images.
OpenAI’s ChatGPT Images help page confirms that ChatGPT can create and edit images. The file upload FAQ is a different source because upload limits are not the same as generation limits.
That distinction matters when you are planning a real batch of work. If you upload 15 product photos for analysis, you are using upload capacity. If you ask ChatGPT to create 15 new ad concepts, you are using image generation capacity. The same ChatGPT plan may limit both, but they are not the same action.
Image File Size and Upload Limits with ChatGPT Go
For uploaded files, OpenAI publishes clearer limits than it does for Go-only generated images. The file upload FAQ lists a 512MB hard limit for many uploaded files, a 20MB limit for image files, up to 80 file uploads every 3 hours, and a lower daily upload limit for Free users. OpenAI also says upload limits can be reduced during peak hours.

Upload limits are separate
OpenAI gives file-upload numbers, not a Go-only generated-image counter
These limits help with image uploads and file analysis. They do not tell you how many new images ChatGPT Go will generate in a day.
Source: OpenAI File Uploads FAQ, checked July 13, 2026.
For ChatGPT Go users, the practical reading is this: Go gives more upload room than Free, but uploads remain limited, and uploaded-image limits should stay separate from daily generated-image planning.
How Rolling Image Limits Work in Real Use
ChatGPT image limits are easier to understand as rolling usage windows than as a midnight reset. A user who generates eight images in the morning, eight in the afternoon, and six at night may have a smoother day than a user who tries to generate 40 images back to back.
A realistic Go workflow might look like this:
- Morning: 6-10 images for concept exploration.
- Afternoon: 6-10 images to refine style, layout, or copy direction.
- Evening: 4-8 images for final variations.
That lands near the 20-30 image planning range without assuming the plan is unlimited. If a batch stalls, the more useful move is to pause, save the strongest prompt, and return later with a tighter variation request.
ChatGPT Go Availability and Price
As of July 13, 2026, OpenAI’s ChatGPT Go help page says Go is available in all ChatGPT-supported countries. The same help page points users to the ChatGPT pricing page for current subscription prices. OpenAI’s launch post lists the US price at $8 per month and notes that Go pricing is localized in some markets.
For pricing, there are two practical rules:
- Use $8/month when you are referring specifically to US pricing.
- For non-US readers, use the price inside the official ChatGPT pricing page or their account upgrade flow.
For a deeper price comparison, use the 完整 ChatGPT Go 价格指南. For regional access questions, the US availability guide 是一篇值得阅读的后续文章。.
ChatGPT Go 是否提供无限图像生成?
No. ChatGPT Go does not offer unlimited image generation. It is a larger budget plan than Free, but image generation is still a heavier workload than plain text chat, and OpenAI manages it through plan limits, rolling windows, and temporary changes during high demand.
This is why “10x more than Free” can be both a meaningful upgrade and still not enough for high-volume creators. If you only need images for class projects, blog visuals, light marketing concepts, or personal design ideas, Go may feel generous. If you need many final assets every day, the limit friction matters more than the headline price.
If you want to understand the broader trade-offs beyond image limits, read the ChatGPT Go benefits and limits breakdown or the 聊天GPT围棋与免费 比较。.
Who Should Use ChatGPT Go for Image Generation?
ChatGPT Go is best for users who generate images regularly but not at production scale. It fits students, casual creators, small marketers, bloggers, and people who want more room than Free without paying for a higher ChatGPT tier.
It is less ideal for users who need predictable high-volume output, many same-day variations, or a mix of image and video models. That is where a multi-model workflow starts to feel less like a luxury and more like a time saver. For example, GlobalGPT’s GPT Image 2 workspace can sit alongside other image, video, and chat tools, while the GlobalGPT 定价页面 is the right place to compare its own plans.
The right choice depends on your real workload. Pick Go if you want a cheaper ChatGPT upgrade for moderate image use. Pick a higher or broader plan if your work depends on many images, multiple models, or fewer interruptions during a production day.
ChatGPT Go Image Limits at a Glance
| 问题 | Best answer |
|---|---|
| How many images can ChatGPT Go generate per day? | Plan around 20-30 images per day for moderate use, but read that as an estimate. |
| Does OpenAI publish a fixed Go image cap? | No public Go-only daily image number is listed in the help page. |
| Is Go unlimited? | No. Go has higher limits than Free, but limits can vary. |
| Are uploads and generated images the same limit? | No. Uploading an image and generating a new image are different actions. |
| Is Go enough for daily creative work? | Usually yes for moderate use, but not for high-volume production. |
常见问题
Does OpenAI publish an exact ChatGPT Go daily image generation limit?
No. OpenAI publicly says ChatGPT Go includes more image creation than Free and higher usage limits, but it does not publish one fixed Go-only daily image number. Limits may vary based on system conditions.
How many images should I plan to generate with ChatGPT Go per day?
A practical planning estimate is around 20-30 images per day for moderate use. Use that as a working range based on Go’s higher allowance, not as an official guarantee.
Is ChatGPT Go unlimited for image generation?
No. ChatGPT Go is not unlimited. It is a budget paid plan with more capacity than Free, but image generation still uses plan limits and rolling usage windows.
How many images can I upload to ChatGPT Go?
Uploading images is different from generating images. OpenAI’s file upload FAQ lists a 20MB limit per image file and other upload caps, while Go itself offers more upload capacity than Free. Keep upload limits separate from generated-image planning.
Does ChatGPT Go have the same image limits as ChatGPT Plus?
No. Go and Plus are separate tiers. Plus is positioned for heavier and more advanced work, while Go is the lower-cost upgrade from Free.
Is ChatGPT Go available in my country?
OpenAI’s ChatGPT Go help page says Go is available in all ChatGPT-supported countries as of July 13, 2026. Availability and local pricing can still depend on what your ChatGPT account and official pricing page show.
Should I choose ChatGPT Go or a multi-model platform for images?
Choose ChatGPT Go if you mainly want a cheaper ChatGPT upgrade for moderate image generation. Consider a multi-model platform if your workflow also needs other chat models, research tools, image models, or video generation in one place.

