
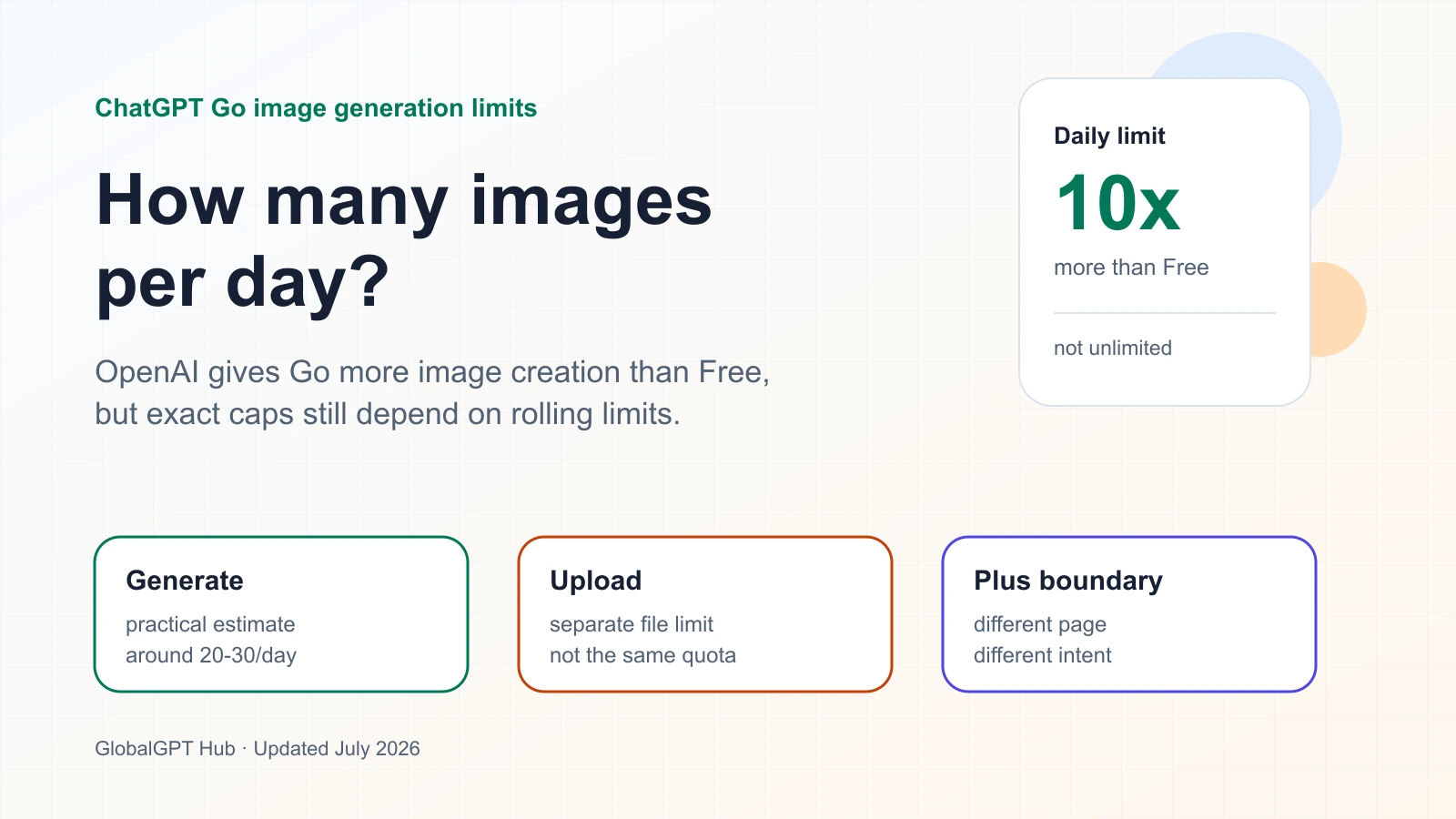
OpenAI ไม่ประกาศจำนวนการสร้างภาพต่อวันที่คงที่สำหรับ ChatGPT Go ตัวเลขที่ควรใช้ในการวางแผนยังคงเป็นช่วงค่า: Go ได้รับการอธิบายอย่างเป็นทางการว่ามีความสามารถในการสร้างภาพสูงกว่า Free ประมาณ 10 เท่า ดังนั้น ผู้ใช้ระดับปานกลางควรวางแผนไว้ที่ประมาณไม่กี่สิบภาพต่อวัน (ประมาณ 20-30 ภาพ) โดยคาดการณ์ว่าขีดจำกัดจริงอาจเปลี่ยนแปลงไปตามสถานะบัญชี ความต้องการ และสภาพระบบ.
สิ่งนี้ทำให้ Go เป็นตัวเลือกที่คุ้มค่าสำหรับการทำงานกับภาพเป็นครั้งคราว แต่ไม่ใช่แผนการผลิตปริมาณมากที่สามารถคาดการณ์ได้ เอกสารสาธารณะของ OpenAI ให้ข้อมูลเกี่ยวกับความจุสัมพัทธ์และตำแหน่งของแผนบริการ แต่ไม่ได้ระบุจำนวนภาพต่อวันที่ชัดเจนสำหรับทุกบัญชี Go ดังนั้นคำถามที่ดีกว่าไม่ใช่เพียง “ขีดจำกัดคือเท่าไร?” แต่เป็น “แผนนี้จะเหมาะกับวิธีการสร้างภาพของฉันจริง ๆ หรือไม่?”
ChatGPT Go มีข้อจำกัดน้อยกว่าเวอร์ชัน Free มากสำหรับการสร้างภาพตามคำสั่งประจำวัน แต่ระบบอาจทำงานช้าลงหรือหยุดชั่วคราวได้หากคุณสร้างภาพจำนวนมากในระยะเวลาสั้นๆ สำหรับผู้ใช้ที่กำลังเปรียบเทียบบริการสมัครสมาชิก AI ทางเลือกที่เหมาะสมคือพิจารณาว่า ราคาที่ต่ำกว่าของ Go จะเพียงพอสำหรับงานสร้างภาพในระดับปานกลาง หรือว่าชุดเครื่องมือที่กว้างขวางกว่าจะช่วยประหยัดเวลาได้มากขึ้น.
หากข้อจำกัดด้านภาพเป็นหนึ่งในเหตุผลที่คุณกำลังเปรียบเทียบแพ็กเกจ AI ต่าง ๆ, โกลบอลจีพีที เป็นตัวเลือกที่ควรพิจารณาในฐานะพื้นที่ทำงาน AI แบบครบวงจร โดยเฉพาะอย่างยิ่งหากงานของคุณใช้เกินโควตาภาพของ ChatGPT หนึ่งภาพ ชุดเครื่องมือด้านภาพของมันสามารถ ภาพหน้าปกที่สร้างด้วย GPT Image 2, Nano Banana Pro และ Nano Banana 2 รวมถึงการทำงานกับวิดีโอโดยใช้ Sora 2, Kling 3.0, Wan 2.7, Seedance 2.0, Grok Imagine และ Veo 3.1 ส่วนการสนทนาและการวิจัยสามารถทำให้เรียบง่ายขึ้นได้: ใช้ GPT, Claude, Gemini หรือ Perplexity เพื่อร่างคำสั่ง เปรียบเทียบแนวคิด และปรับปรุงเนื้อหา โดยไม่ต้องสมัครสมาชิกหลายบริการหรือเปลี่ยนแท็บทุกขั้นตอน.
สารบัญ
- OpenAI กล่าวอย่างไรเกี่ยวกับข้อจำกัดจำนวนภาพใน ChatGPT Go
- คุณควรคาดหวังว่าจะได้รับภาพกี่ภาพต่อวัน?
- ChatGPT Go vs Free vs Plus: ข้อจำกัดจำนวนรูปภาพ
- การอัปโหลดภาพกับการสร้างภาพ: ข้อจำกัดที่แตกต่างกัน
- ขนาดไฟล์ภาพและข้อจำกัดการอัปโหลดกับ ChatGPT Go
- กลไกการทำงานของขีดจำกัดภาพที่เลื่อนไปมาในการใช้งานจริง
- ความพร้อมใช้งานและราคาของ ChatGPT Go
- ChatGPT Go ให้บริการการสร้างภาพไม่จำกัดหรือไม่?
- ใครควรใช้ ChatGPT Go เพื่อสร้างภาพ?
- สรุปข้อจำกัดของ ChatGPT Go Image
- คำถามที่พบบ่อย
OpenAI กล่าวอย่างไรเกี่ยวกับข้อจำกัดจำนวนภาพใน ChatGPT Go
หน้าช่วยเหลือ ChatGPT Go ของ OpenAI อธิบายว่า Go เป็นแพ็กเกจสมัครสมาชิกราคาถูกที่ให้สิทธิ์ใช้งานคุณสมบัติยอดนิยมของ ChatGPT ได้อย่างกว้างขวางยิ่งขึ้น สำหรับงานที่เกี่ยวข้องกับภาพ คำสำคัญคือ Go ให้สิทธิ์ใช้งานการสร้างภาพได้มากขึ้น ในบทความช่วยเหลือเดียวกัน ส่วนที่กล่าวถึงข้อจำกัดการใช้งานระบุว่า Go มีข้อจำกัดที่สูงกว่าเวอร์ชัน Free และข้อจำกัดดังกล่าวอาจเปลี่ยนแปลงได้ตามสภาพระบบ.


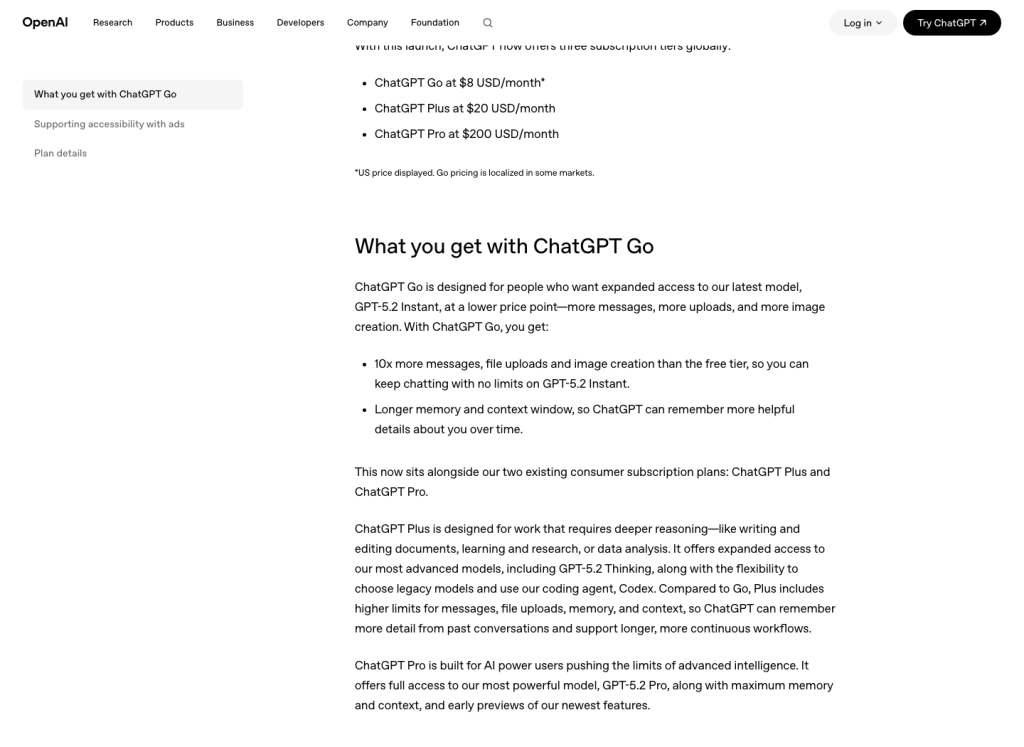
โพสต์ประกาศเปิดตัวของ OpenAI ให้การเปรียบเทียบที่ชัดเจนยิ่งขึ้น: ChatGPT Go มีจำนวนข้อความ การอัปโหลดไฟล์ และการสร้างภาพมากกว่าประมาณ 10 เท่าเมื่อเทียบกับแพ็กเกจ Free ตัวเลขนี้ถือเป็นสัญญาณสาธารณะที่ชัดเจนที่สุดสำหรับการประเมินความจุในการสร้างภาพของ Go อย่างไรก็ตาม นี่เป็นเพียงตัวคูณเชิงสัมพัทธ์เท่านั้น ไม่ใช่คำสัญญาว่าทุกบัญชีจะได้รับจำนวนภาพเท่ากันทุกวันตามปฏิทิน.
ข้อมูลอย่างเป็นทางการ
วงเงิน Go ที่ OpenAI ประกาศไว้สำหรับการสร้างภาพนั้นสูงกว่า 10 เท่าของระดับ Free tier
นี่คือหมายเลขสาธารณะที่สะอาดที่สุดสำหรับการประมาณค่า Go มันรองรับช่วงการทำงานรายวันที่กว้างกว่าเวอร์ชัน Free แต่ยังไม่สร้างตัวนับรายวันที่คงที่.
แหล่งที่มา: OpenAI, “Introducing ChatGPT Go,” ตรวจสอบเมื่อวันที่ 13 กรกฎาคม 2026 ตัวเลข 10x นี้รวมถึงการส่งข้อความ การอัปโหลดไฟล์ และการสร้างภาพ เมื่อเทียบกับเวอร์ชันฟรี.
ข้อสรุปที่นำไปใช้ได้จริงนั้นเรียบง่าย: OpenAI ยืนยันว่าแผน Go ได้รับสิทธิ์สร้างภาพมากกว่าแผน Free และขีดจำกัดของแผนอาจแตกต่างกันได้ แต่ไม่ได้ยืนยันตัวเลขที่คงที่สำหรับสาธารณะ เช่น “30 ภาพต่อวันสำหรับทุกบัญชี Go”
คุณควรคาดหวังว่าจะได้รับภาพกี่ภาพต่อวัน?
เพื่อวัตถุประสงค์ในการวางแผน ให้คาดการณ์ว่า ChatGPT Go จะสามารถสร้างภาพได้หลายสิบภาพต่อวันอย่างสะดวกสบาย ผมจะกำหนดช่วงการทำงานสำหรับวันปกติไว้ที่ 20-30 ภาพ โดยเฉพาะอย่างยิ่งหากคุณแบ่งคำขอออกเป็นหลายส่วน แทนที่จะส่งเป็นชุดใหญ่ครั้งเดียว.
ช่วงนี้มีความประโยชน์เพราะสอดคล้องกับวิธีที่ผู้คนวางแผนงานภาพจริง ๆ ได้แก่ การกำหนดแนวคิด การสร้างเวอร์ชันต่าง ๆ การเลือกภาพ และการแก้ไขเล็กน้อย คุณอาจเห็นความจุเพิ่มขึ้นในช่วงเวลาที่ระบบไม่คึกคัก ลดลงในช่วงที่มีความต้องการสูง และประสบการณ์การใช้งานที่แตกต่างออกไปหาก OpenAI ปรับเปลี่ยนขีดจำกัดของแผนบริการ พื้นฐานสาธารณะสำหรับการประมาณการนี้คือตำแหน่งของ OpenAI ในระดับ Free-tier 10x ไม่ใช่ขีดจำกัดรายวันที่ประกาศไว้สำหรับ Go เท่านั้น.
| คำถาม | คำตอบที่ดีที่สุด | ความมั่นใจ |
|---|---|---|
| Go มีฟังก์ชันสร้างภาพหรือไม่? | ใช่ OpenAI ได้ระบุไว้ว่า Go จะได้รับสิทธิ์การเข้าถึงที่ขยายออกไปสำหรับการสร้างภาพ. | ได้รับการตรวจสอบอย่างเป็นทางการ |
| มีขีดจำกัดสูงสุดประจำวันสำหรับประชาชนที่กำหนดไว้หรือไม่? | ในหน้าช่วยเหลือสาธารณะของ OpenAI ไม่มีการเผยแพร่หมายเลขโทรศัพท์เฉพาะสำหรับ Go อย่างเป็นทางการ. | ได้รับการยืนยันอย่างเป็นทางการจากข้อความเกี่ยวกับ "การไม่ปรากฏตัว" และ "ข้อจำกัด" |
| คุณควรวางแผนตามตัวเลขรายวันใด? | ประมาณ 20-30 ภาพต่อวัน สำหรับการใช้งานระดับปานกลาง. | การประมาณการแบบปฏิบัติ |
สำหรับงานของลูกค้าหรือแคมเปญ ผมจะแบ่งชุดงานออกเป็นหลายขั้นตอน ได้แก่ ขั้นตอนการคิดแนวคิดเบื้องต้น ขั้นตอนการปรับปรุงให้ละเอียดขึ้น และขั้นตอนการสร้างเวอร์ชันสุดท้าย วิธีนี้ช่วยให้ Go ยังคงมีประโยชน์ได้ โดยไม่ต้องพึ่งพาการสร้างภาพอย่างต่อเนื่องเป็นเวลานานโดยไม่หยุดพัก.
ChatGPT Go vs Free vs Plus: ข้อจำกัดจำนวนรูปภาพ
การเปรียบเทียบที่สำคัญที่สุดคือระหว่าง Free และ Go Free เหมาะสำหรับการทดสอบภาพเป็นครั้งคราว แต่ OpenAI ระบุว่าบริการสร้างภาพแบบ Free มีข้อจำกัดและทำงานช้ากว่า Go เป็นระดับราคาประหยัดสำหรับผู้ที่ต้องการพื้นที่เพียงพอสำหรับการสร้างคำสั่งอย่างสม่ำเสมอ โดยไม่ต้องต้องอัปเกรดไปใช้ Plus ทันที.
Plus และ Pro อยู่เหนือ Go บนหน้าข้อมูลราคาที่ผมตรวจสอบ พบว่า Plus เน้นไปที่การสร้างภาพที่ซับซ้อนและแม่นยำยิ่งขึ้น ส่วน Pro เน้นไปที่การสร้างภาพได้เร็วที่สุดและในปริมาณสูงสุด สิ่งนี้ช่วยให้คุณเข้าใจวิธีอ่านระดับบริการได้ชัดเจนขึ้น: Go เหมาะสำหรับการใช้งานทั่วไปในราคาที่ต่ำกว่า ส่วน Plus และ Pro เป็นระดับที่ OpenAI มุ่งเน้นสำหรับกระบวนการทำงานด้านภาพที่ซับซ้อนและหนักหน่วงยิ่งขึ้น.
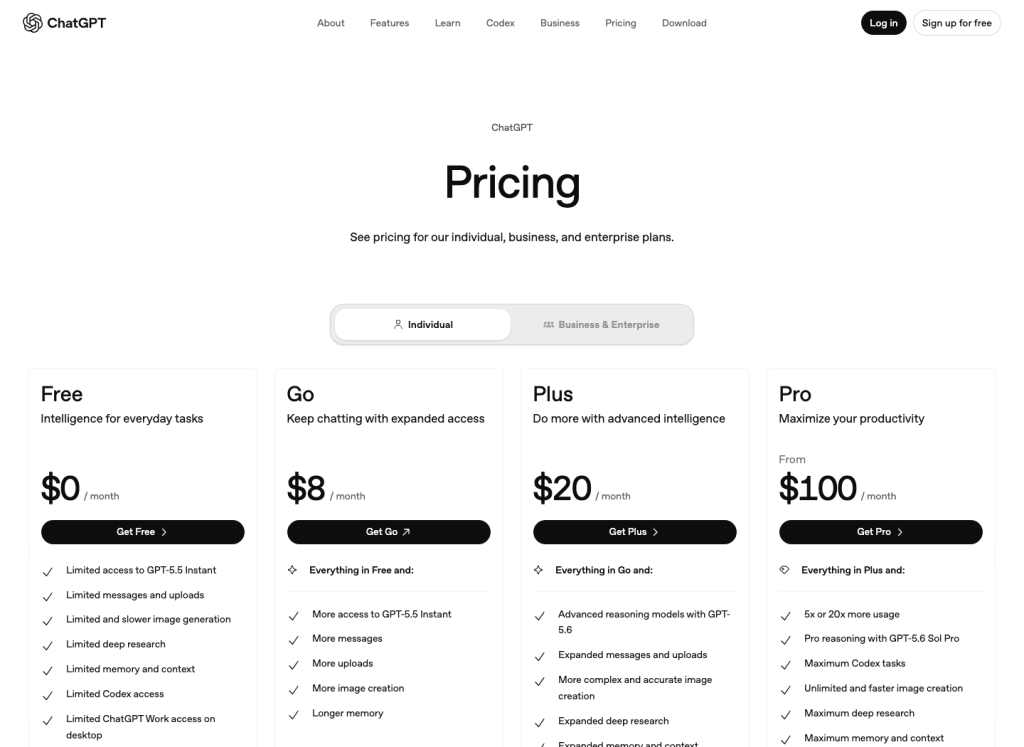
มุมมองเกี่ยวกับราคาในสหรัฐอเมริกา
การเพิ่มราคาจาก Go ไปสู่ Plus นั้นไม่มากนัก; แต่ความแตกต่างในกระบวนการทำงานต่างหากที่เป็นประเด็นสำคัญ
บนหน้ากำหนดราคาของสหรัฐฯ ที่ตรวจสอบสำหรับการอัปเดตนี้ Go มีราคา $8/เดือน Plus มีราคา $20/เดือน ส่วน Pro มีราคาเริ่มต้นที่สูงกว่ามาก หากคุณต้องการสร้างภาพเพียงไม่กี่สิบภาพ Go เป็นตัวเลือกทดลองที่มีค่าใช้จ่ายต่ำที่สุด หากการสร้างภาพเป็นส่วนหนึ่งของงานประจำวัน ให้เปรียบเทียบความยุ่งยากจากข้อจำกัดกับส่วนต่างของราคา.
แหล่งที่มา: หน้าข้อมูลราคา ChatGPT, ภาพหน้าจอเวอร์ชันสหรัฐอเมริกาที่บันทึกเมื่อวันที่ 13 กรกฎาคม 2026 ราคาในท้องถิ่นอาจแตกต่างกันไปตามตลาดและบัญชี.
| แผน | ความเหมาะสมในการสร้างภาพ | วิธีใช้สิ่งนี้ในการตัดสินใจเกี่ยวกับ Go |
|---|---|---|
| ฟรี | การทดสอบแสงและภาพถ่ายเป็นครั้งคราว. | หากคุณยังคงถึงขีดจำกัดหลังจากลองเพียงไม่กี่ครั้ง ให้อัปเกรด. |
| แชทจีพีที โก | สร้างภาพทุกวันด้วยราคาที่ถูกกว่า. | ใช้การประมาณ 20-30 ครั้งต่อวัน เป็นช่วงการวางแผนสำหรับระดับการใช้งานปานกลาง. |
| พลัส | งานประมวลผลภาพที่ซับซ้อนและขั้นสูงยิ่งขึ้น. | ลองใช้ Compare Plus หากการปรับขีดจำกัดแบบต่อเนื่องของ Go ทำให้กระบวนการทำงานของคุณถูกขัดจังหวะ. |
| ข้อดี | การสร้างภาพสำหรับผู้ใช้ระดับสูง และกระบวนการทำงานที่มีการใช้งานอย่างกว้างขวาง. | อย่าใช้ Pro เป็นเกณฑ์เปรียบเทียบสำหรับแพ็กเกจ Go ราคาประหยัด. |
หากคำถามของคุณเกี่ยวข้องกับ Plus โดยเฉพาะ ให้ใช้ส่วนที่แยกต่างหาก คู่มือเกี่ยวกับขีดจำกัดภาพของ ChatGPT Plus. หากคำถามของคุณคือ Go สามารถสร้างภาพได้หรือไม่ ให้เริ่มจาก คู่มือเกี่ยวกับความสามารถในการสร้างภาพของ ChatGPT Go. หน้านี้กล่าวถึงปริมาณและข้อจำกัดของ Go.
การอัปโหลดภาพกับการสร้างภาพ: ข้อจำกัดที่แตกต่างกัน
หลายคนมักสับสนระหว่างสามการกระทำที่แตกต่างกัน:
- สร้างภาพ หมายถึงการขอให้ ChatGPT สร้างภาพใหม่จากคำสั่ง.
- การอัปโหลดรูปภาพ หมายถึงการแนบภาพที่มีอยู่เพื่อให้ ChatGPT สามารถตรวจสอบ อธิบาย หรือแก้ไขภาพนั้นได้.
- การอัปโหลดไฟล์ สามารถรวมถึงเอกสาร ตารางข้อมูล การนำเสนอ PDF และรูปภาพ.
หน้าช่วยเหลือของ ChatGPT Images ของ OpenAI ยืนยันว่า ChatGPT สามารถสร้างและแก้ไขภาพได้ ส่วนคำถามที่พบบ่อยเกี่ยวกับการอัปโหลดไฟล์เป็นแหล่งข้อมูลที่ต่างออกไป เนื่องจากข้อจำกัดในการอัปโหลดไม่เหมือนกับข้อจำกัดในการสร้างภาพ.
ความแตกต่างนี้มีความสำคัญเมื่อคุณกำลังวางแผนงานในปริมาณที่มากจริง ๆ หากคุณอัปโหลดภาพสินค้า 15 ภาพเพื่อวิเคราะห์ คุณกำลังใช้ความจุในการอัปโหลด แต่หากคุณขอให้ ChatGPT สร้างแนวคิดโฆษณาใหม่ 15 แนว คุณกำลังใช้ความจุในการสร้างภาพ แม้แผน ChatGPT เดียวกันอาจจำกัดทั้งสองอย่าง แต่ทั้งสองอย่างนี้ไม่ใช่การกระทำแบบเดียวกัน.
ขนาดไฟล์ภาพและข้อจำกัดการอัปโหลดกับ ChatGPT Go
สำหรับไฟล์ที่อัปโหลด OpenAI กำหนดขีดจำกัดที่ชัดเจนกว่าเมื่อเทียบกับภาพที่สร้างขึ้นโดยใช้ Go เท่านั้น ในส่วนคำถามที่พบบ่อยเกี่ยวกับการอัปโหลดไฟล์ ระบุว่ามีขีดจำกัดสูงสุด 512MB สำหรับไฟล์ส่วนใหญ่ ขีดจำกัด 20MB สำหรับไฟล์ภาพ สามารถอัปโหลดไฟล์ได้สูงสุด 80 ไฟล์ทุก 3 ชั่วโมง และขีดจำกัดการอัปโหลดรายวันที่ต่ำกว่าสำหรับผู้ใช้ Free OpenAI ยังระบุด้วยว่าขีดจำกัดการอัปโหลดอาจถูกลดลงในช่วงเวลาที่มีการใช้งานสูง.

ขีดจำกัดการอัปโหลดเป็นแต่ละส่วน
OpenAI ให้ข้อมูลจำนวนการอัปโหลดไฟล์ ไม่ใช่ตัวนับภาพที่สร้างขึ้นโดย Go เท่านั้น
ข้อจำกัดเหล่านี้ช่วยในการอัปโหลดภาพและการวิเคราะห์ไฟล์ แต่ไม่ได้ระบุจำนวนภาพใหม่ที่ ChatGPT Go จะสร้างขึ้นในหนึ่งวัน.
แหล่งที่มา: คำถามที่พบบ่อยเกี่ยวกับการอัปโหลดไฟล์ของ OpenAI, ตรวจสอบเมื่อวันที่ 13 กรกฎาคม 2026.
สำหรับผู้ใช้ ChatGPT Go ข้อควรทราบในทางปฏิบัติคือ: Go ให้พื้นที่อัปโหลดมากกว่าเวอร์ชัน Free แต่การอัปโหลดยังคงมีข้อจำกัด และควรแยกข้อจำกัดจำนวนภาพที่อัปโหลดออกจากแผนการสร้างภาพรายวัน.
กลไกการทำงานของขีดจำกัดภาพที่เลื่อนไปมาในการใช้งานจริง
การจำกัดจำนวนภาพของ ChatGPT จะเข้าใจได้ง่ายกว่าหากมองเป็นช่วงเวลาการใช้งานแบบต่อเนื่อง แทนที่จะเป็นการรีเซ็ตเมื่อถึงเที่ยงคืน ผู้ใช้ที่สร้างภาพ 8 ภาพในช่วงเช้า 8 ภาพในช่วงบ่าย และ 6 ภาพในช่วงค่ำ อาจมีประสบการณ์การใช้งานที่ราบรื่นกว่าผู้ใช้ที่พยายามสร้างภาพ 40 ภาพติดต่อกัน.
ขั้นตอนการทำงานของ Go ที่สมจริงอาจมีลักษณะดังนี้:
- ตอนเช้า: 6-10 ภาพ เพื่อสำรวจแนวคิด.
- ช่วงบ่าย: 6-10 ภาพ เพื่อปรับแต่งสไตล์ การจัดวาง หรือทิศทางเนื้อหา.
- ช่วงเย็น: 4-8 ภาพสำหรับเวอร์ชันสุดท้าย.
ผลลัพธ์นี้อยู่ในช่วงการวางแผนภาพประมาณ 20-30 ภาพ โดยไม่สมมติว่าแผนการนั้นไม่มีขีดจำกัด หากการประมวลผลแบบกลุ่มหยุดชะงัก วิธีที่มีประโยชน์ที่สุดคือหยุดชั่วคราว บันทึกคำสั่งที่ให้ผลลัพธ์ดีที่สุด และกลับมาดำเนินการใหม่ในภายหลังด้วยคำขอปรับเปลี่ยนที่เฉพาะเจาะจงมากขึ้น.
ความพร้อมใช้งานและราคาของ ChatGPT Go
ตั้งแต่วันที่ 13 กรกฎาคม 2026 หน้าช่วยเหลือ ChatGPT Go ของ OpenAI ระบุว่า Go มีให้บริการในทุกประเทศที่ ChatGPT รองรับ หน้าช่วยเหลือเดียวกันนี้ยังชี้ให้ผู้ใช้ไปยังหน้ากำหนดราคา ChatGPT เพื่อดูราคาสมัครสมาชิกปัจจุบัน โพสต์ประกาศการเปิดตัวของ OpenAI ระบุราคาในสหรัฐอเมริกาอยู่ที่ $8 ต่อเดือน และชี้ว่าราคา Go ได้รับการปรับให้เหมาะสมกับแต่ละตลาด.
สำหรับเรื่องราคา มีกฎปฏิบัติสองข้อดังนี้:
- ใช้ $8/เดือน เมื่อคุณกำลังกล่าวถึงราคาในสหรัฐอเมริกาโดยเฉพาะ.
- สำหรับผู้อ่านที่ไม่ได้อยู่ในสหรัฐอเมริกา ให้ใช้ราคาที่แสดงในหน้ากำหนดราคาอย่างเป็นทางการของ ChatGPT หรือในขั้นตอนการอัปเกรดบัญชีของพวกเขา.
หากต้องการเปรียบเทียบราคาอย่างละเอียดยิ่งขึ้น ให้ใช้ คู่มือราคาเต็มของ ChatGPT Go. สำหรับคำถามเกี่ยวกับการเข้าถึงในภูมิภาคต่างๆ, คู่มือการจำหน่ายในสหรัฐอเมริกา เป็นหนังสือที่ควรอ่านต่อต่อไป.
ChatGPT Go ให้บริการการสร้างภาพไม่จำกัดหรือไม่?
ไม่ ChatGPT Go ไม่ให้บริการสร้างภาพแบบไม่จำกัด แม้จะเป็นแพ็กเกจที่มีงบประมาณสูงกว่าแพ็กเกจ Free แต่การสร้างภาพยังคงเป็นงานที่มีภาระหนักกว่าการสนทนาด้วยข้อความธรรมดา และ OpenAI จัดการเรื่องนี้ผ่านข้อจำกัดของแพ็กเกจ หน้าต่างแบบหมุนเวียน และการปรับเปลี่ยนชั่วคราวในช่วงที่มีความต้องการสูง.
นี่คือเหตุผลที่ “10x more than Free” สามารถเป็นการอัปเกรดที่มีความหมายได้ แต่ก็ยังไม่เพียงพอสำหรับผู้สร้างเนื้อหาในปริมาณมาก หากคุณต้องการภาพเพียงเพื่อโครงการในชั้นเรียน ภาพประกอบบล็อก แนวคิดการตลาดแบบเบาๆ หรือไอเดียการออกแบบส่วนตัว แพ็กเกจ Go อาจดูเป็นตัวเลือกที่คุ้มค่า แต่หากคุณต้องการสินทรัพย์สำเร็จรูปจำนวนมากทุกวัน ข้อจำกัดในการใช้งานจะมีความสำคัญมากกว่าราคาที่โฆษณาไว้.
หากต้องการเข้าใจการแลกเปลี่ยนผลประโยชน์ในภาพรวมที่ไปไกลกว่าข้อจำกัดของภาพ โปรดอ่าน ข้อดีและข้อจำกัดของ ChatGPT Go ความขัดข้อง หรือ ChatGPT Go vs ฟรี การเปรียบเทียบ.
ใครควรใช้ ChatGPT Go เพื่อสร้างภาพ?
ChatGPT Go เหมาะที่สุดสำหรับผู้ใช้ที่สร้างภาพอย่างสม่ำเสมอ แต่ยังไม่ถึงระดับการผลิตจริง เหมาะสำหรับนักศึกษา ผู้สร้างเนื้อหาแบบไม่เป็นทางการ นักการตลาดขนาดเล็ก บล็อกเกอร์ และผู้ที่ต้องการพื้นที่ใช้งานมากกว่าเวอร์ชันฟรี โดยไม่ต้องจ่ายค่าบริการเพื่ออัปเกรดไปยังแพ็กเกจ ChatGPT ระดับสูง.
วิธีนี้อาจไม่เหมาะสมนักสำหรับผู้ใช้ที่ต้องการผลลัพธ์ปริมาณมากที่คาดการณ์ได้ การสร้างเนื้อหาหลายรูปแบบในวันเดียว หรือการใช้โมเดลภาพและวิดีโอร่วมกัน นี่คือจุดที่กระบวนการทำงานแบบหลายโมเดลเริ่มไม่ใช่เพียงสิ่งหรูหรา แต่กลายเป็นเครื่องมือที่ช่วยประหยัดเวลาได้จริง ตัวอย่างเช่น GlobalGPT’s พื้นที่ทำงาน GPT Image 2 สามารถใช้งานร่วมกับเครื่องมืออื่น ๆ สำหรับรูปภาพ วิดีโอ และการแชทได้ ส่วน หน้าราคาของ GlobalGPT เป็นสถานที่ที่เหมาะสมที่สุดสำหรับการเปรียบเทียบแพ็กเกจของตัวเอง.
การเลือกที่เหมาะสมขึ้นอยู่กับปริมาณงานจริงของคุณ หากต้องการอัปเกรด ChatGPT ในราคาที่ถูกกว่าสำหรับการใช้งานภาพในระดับปานกลาง ให้เลือก Go แต่หากงานของคุณต้องพึ่งพาภาพจำนวนมาก โมเดลหลายตัว หรือต้องการลดการขัดจังหวะระหว่างวันทำงาน ให้เลือกแพ็กเกจที่มีระดับสูงกว่าหรือครอบคลุมมากขึ้น.
สรุปข้อจำกัดของ ChatGPT Go Image
| คำถาม | คำตอบที่ดีที่สุด |
|---|---|
| ChatGPT Go สามารถสร้างภาพได้กี่ภาพต่อวัน? | ควรวางแผนใช้ประมาณ 20-30 ภาพต่อวัน สำหรับการใช้งานระดับปานกลาง แต่อย่าถือว่านี่เป็นตัวเลขที่แน่นอน. |
| OpenAI กำหนดขีดจำกัดจำนวนภาพ Go ที่สามารถอัปโหลดได้หรือไม่? | ในหน้าช่วยเหลือไม่มีตัวเลขภาพประจำวันแบบ Go-only ที่เปิดเผยต่อสาธารณะ. |
| Go มีไม่จำกัดหรือไม่? | ไม่ครับ Go มีขีดจำกัดที่สูงกว่า Free แต่ขีดจำกัดอาจแตกต่างกันได้. |
| การอัปโหลดและภาพที่สร้างขึ้นมีขีดจำกัดเดียวกันหรือไม่? | ไม่ การอัปโหลดภาพและการสร้างภาพใหม่เป็นสองการกระทำที่ต่างกัน. |
| Go เพียงพอสำหรับงานสร้างสรรค์ประจำวันหรือไม่? | โดยทั่วไปแล้วสามารถใช้ได้สำหรับการใช้งานระดับปานกลาง แต่ไม่เหมาะสำหรับการผลิตในปริมาณมาก. |
คำถามที่พบบ่อย
OpenAI ประกาศขีดจำกัดการสร้างภาพรายวันของ ChatGPT Go อย่างชัดเจนหรือไม่?
ไม่ OpenAI ประกาศอย่างเป็นทางการว่า ChatGPT Go มีฟังก์ชันสร้างภาพมากกว่าเวอร์ชัน Free และขีดจำกัดการใช้งานที่สูงกว่า แต่ไม่ได้กำหนดจำนวนภาพที่สร้างได้ต่อวันแบบคงที่สำหรับเวอร์ชัน Go เท่านั้น ขีดจำกัดอาจแตกต่างกันไปตามสภาพของระบบ.
ผมควรวางแผนสร้างภาพด้วย ChatGPT Go วันละกี่ภาพดี?
การประมาณการวางแผนที่ปฏิบัติได้จริงคือประมาณ 20-30 ภาพต่อวัน สำหรับการใช้งานในระดับปานกลาง ให้ใช้ตัวเลขนี้เป็นช่วงอ้างอิงตามโควตาที่สูงขึ้นของ Go ไม่ใช่การรับประกันอย่างเป็นทางการ.
ChatGPT Go มีคุณสมบัติสร้างภาพแบบไม่จำกัดหรือไม่?
ไม่ ChatGPT Go ไม่ใช่บริการแบบไม่จำกัด แต่เป็นแพ็กเกจแบบชำระเงินราคาประหยัดที่มีความจุมากกว่าเวอร์ชันฟรี อย่างไรก็ตาม การสร้างภาพยังคงถูกจำกัดตามขีดจำกัดของแพ็กเกจและช่วงเวลาการใช้งานแบบหมุนเวียน.
ฉันสามารถอัปโหลดรูปภาพได้กี่รูปใน ChatGPT Go?
การอัปโหลดภาพนั้นแตกต่างจากการสร้างภาพ คำถามที่พบบ่อยเกี่ยวกับการอัปโหลดไฟล์ของ OpenAI ระบุว่ามีขีดจำกัด 20MB ต่อไฟล์ภาพ และขีดจำกัดการอัปโหลดอื่นๆ ในขณะที่ Go เองมีความจุการอัปโหลดมากกว่าเวอร์ชัน Free ดังนั้น ควรแยกการวางแผนขีดจำกัดการอัปโหลดออกจากแผนการสร้างภาพ.
ChatGPT Go มีข้อจำกัดด้านภาพเหมือนกับ ChatGPT Plus หรือไม่?
No. Go และ Plus เป็นระดับบริการที่แยกกัน Plus ได้รับการออกแบบมาสำหรับงานที่มีปริมาณมากและซับซ้อนยิ่งขึ้น ส่วน Go เป็นตัวเลือกอัปเกรดที่มีราคาถูกกว่าจากเวอร์ชัน Free.
ChatGPT Go มีให้บริการในประเทศของฉันหรือไม่?
หน้าช่วยเหลือ ChatGPT Go ของ OpenAI ระบุว่า Go มีให้บริการในทุกประเทศที่ ChatGPT รองรับ ตั้งแต่วันที่ 13 กรกฎาคม 2026 อย่างไรก็ตาม ความพร้อมให้บริการและราคาในท้องถิ่นอาจขึ้นอยู่กับข้อมูลที่แสดงในบัญชี ChatGPT ของคุณและหน้ากำหนดราคาอย่างเป็นทางการ.
ผมควรเลือก ChatGPT Go หรือแพลตฟอร์มหลายโมเดลสำหรับภาพดี?
เลือก ChatGPT Go หากคุณต้องการอัปเกรด ChatGPT ในราคาที่ถูกกว่า สำหรับการสร้างภาพในระดับปานกลาง ส่วนหากกระบวนการทำงานของคุณยังต้องการโมเดลแชทอื่น ๆ เครื่องมือวิจัย โมเดลภาพ หรือการสร้างวิดีโอในแพลตฟอร์มเดียว ก็ควรพิจารณาใช้แพลตฟอร์มแบบหลายโมเดล.

