
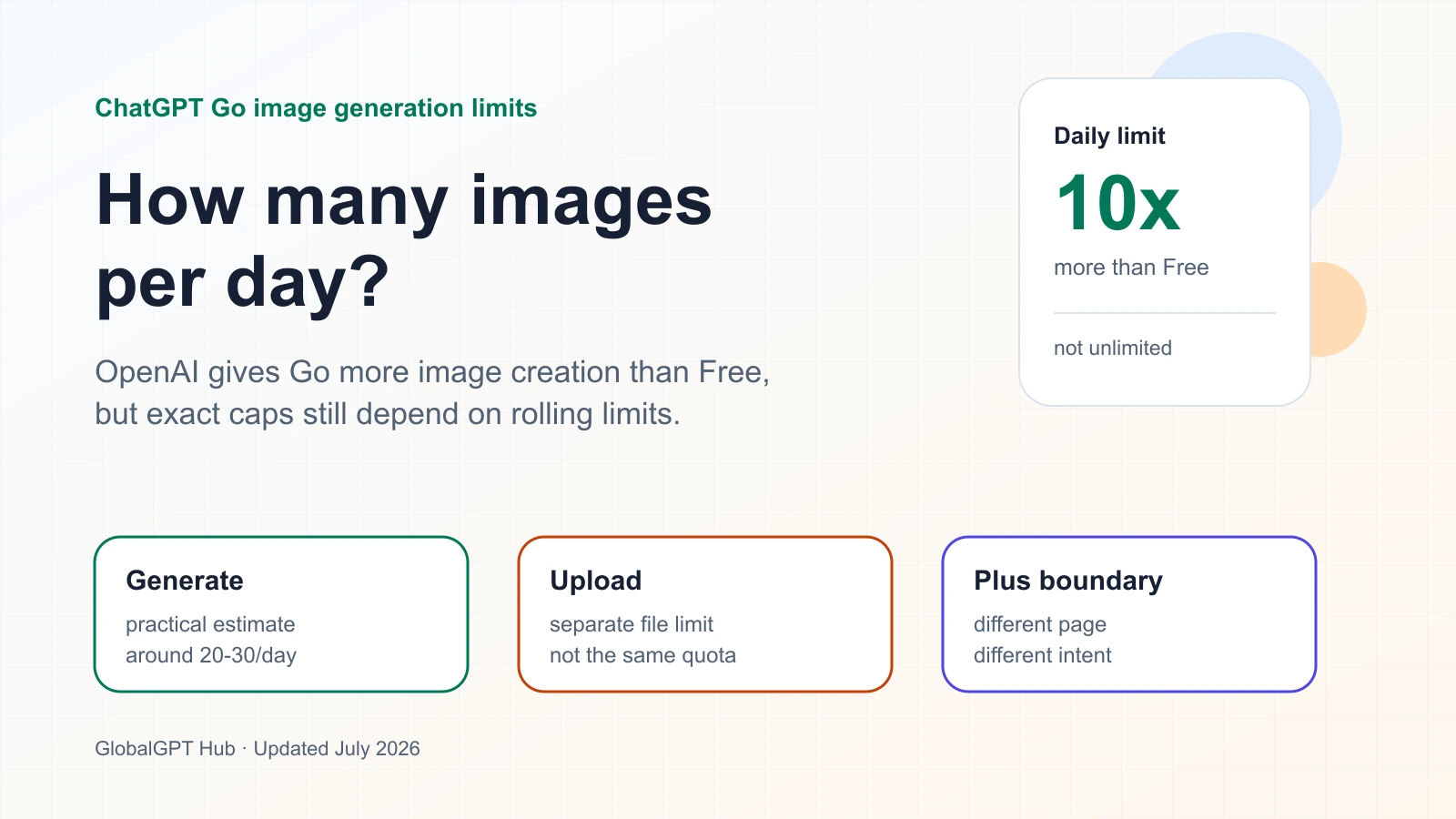
OpenAI no publica una cifra fija diaria de generación de imágenes para ChatGPT Go. La cifra orientativa sigue siendo un rango: oficialmente, se describe que Go tiene una capacidad de creación de imágenes aproximadamente 10 veces superior a la de la versión gratuita, por lo que los usuarios moderados deberían prever unas pocas docenas de imágenes al día, entre 20 y 30 aproximadamente, teniendo en cuenta que los límites reales pueden variar en función del estado de la cuenta, la demanda y las condiciones del sistema.
Esto convierte a Go en una mejora interesante para trabajos ocasionales con imágenes, pero no en un plan de producción predecible para grandes volúmenes. Los materiales públicos de OpenAI ofrecen información sobre la capacidad relativa y el posicionamiento del plan, pero no un recuento diario preciso de imágenes para cada cuenta de Go. Por lo tanto, la pregunta más acertada no es solo “¿cuál es el límite?”, sino “¿se ajustará este plan a la forma en que realmente creo imágenes?”.”
ChatGPT Go es mucho menos restrictivo que la versión gratuita para las solicitudes de imágenes cotidianas, pero aún así puede ralentizarse o detenerse temporalmente si se generan muchas imágenes en un breve intervalo de tiempo. Para los usuarios que comparan suscripciones de IA, la decisión práctica es si el precio más bajo de Go es suficiente para un trabajo moderado con imágenes o si un conjunto de herramientas más amplio les ahorraría más tiempo.
Si los límites de imágenes son uno de los motivos por los que estás comparando suscripciones a servicios de IA, GlobalGPT merece la pena tenerlo en cuenta como un espacio de trabajo de IA «todo en uno», sobre todo si tu trabajo supera la cuota de imágenes de ChatGPT. Su gama de herramientas visuales puede Imagen de portada creada con GPT Image 2, Nano Banana Pro y Nano Banana 2, además de trabajos de vídeo con Sora 2, Kling 3.0, Wan 2.7, Seedance 2.0, Grok Imagine y Veo 3.1. En cuanto al chat y la investigación, todo puede ser más sencillo: utiliza GPT, Claude, Gemini o Perplexity para redactar indicaciones, comparar conceptos y pulir textos sin tener que acumular suscripciones distintas ni cambiar de pestaña en cada paso.
Índice
- Lo que dice realmente OpenAI sobre los límites de imágenes de ChatGPT Go
- ¿Cuántas imágenes al día puedes esperar recibir?
- ChatGPT Go, Free y Plus: límites de imágenes
- Subir imágenes frente a generar imágenes: límites diferentes
- Tamaño de los archivos de imagen y límites de subida con ChatGPT Go
- Cómo funcionan los límites de imágenes en movimiento en la práctica
- Disponibilidad y precio de ChatGPT Go
- ¿Ofrece ChatGPT Go generación ilimitada de imágenes?
- ¿Quién debería utilizar ChatGPT Go para la generación de imágenes?
- Resumen de los límites de imágenes de ChatGPT Go
- PREGUNTAS FRECUENTES
Lo que dice realmente OpenAI sobre los límites de imágenes de ChatGPT Go
La página de ayuda de ChatGPT Go de OpenAI describe Go como una suscripción de bajo coste que ofrece un acceso ampliado a las funciones más populares de ChatGPT. En lo que respecta al trabajo con imágenes, lo más destacado es que Go incluye un acceso ampliado a la generación de imágenes. En el mismo artículo de ayuda, la sección sobre límites de uso indica que Go tiene límites más altos que la versión gratuita, y que dichos límites pueden variar en función de las condiciones del sistema.


La publicación de lanzamiento de OpenAI ofrece una comparación más concreta: ChatGPT Go incluye aproximadamente 10 veces más mensajes, subidas de archivos y creación de imágenes que el plan gratuito. Esa cifra es el indicador público más claro para estimar la capacidad de Go en cuanto a imágenes. Sigue siendo un multiplicador relativo, no una garantía de que todas las cuentas reciban el mismo número de imágenes cada día natural.
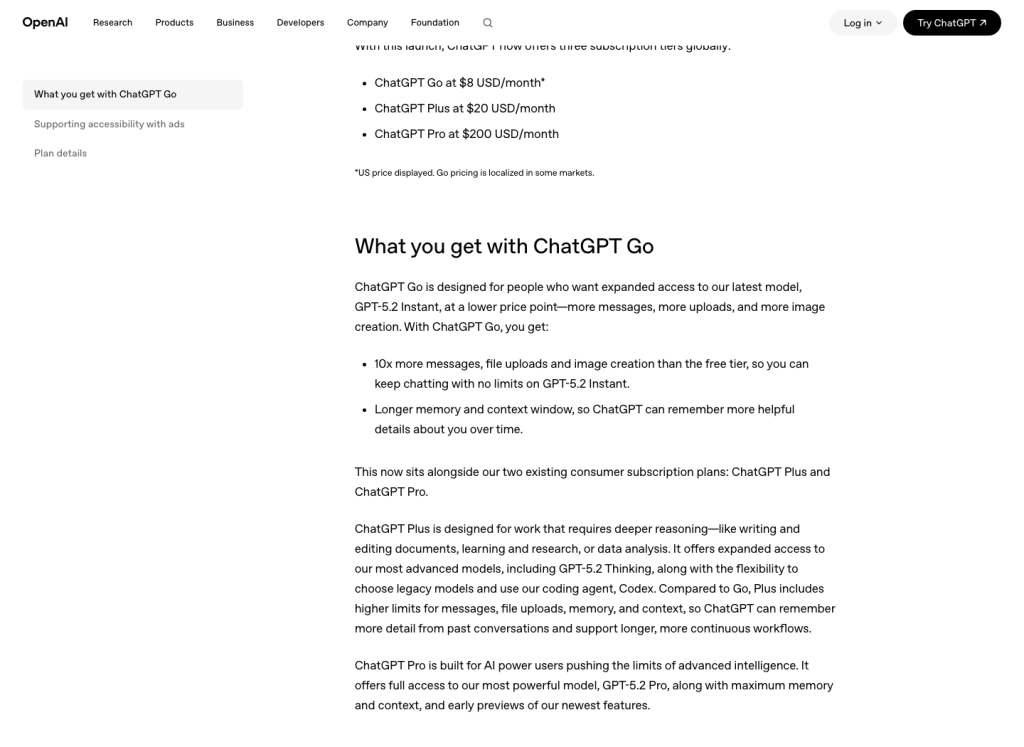
Dato oficial
La asignación de Go publicada por OpenAI es 10 veces superior al nivel gratuito para la creación de imágenes.
Este es el número público más preciso para calcular el Go. Admite un rango de trabajo diario mayor que el de la versión gratuita, pero sigue sin crear un contador diario fijo.
Fuente: OpenAI, “Introducing ChatGPT Go”, consultado el 13 de julio de 2026. La cifra de 10 veces incluye mensajes, subida de archivos y creación de imágenes, en comparación con la versión gratuita.
La conclusión práctica es sencilla: OpenAI confirma que el plan Go permite crear más imágenes que el plan Free y que los límites de cada plan pueden variar. No confirma una cifra pública fija, como “30 imágenes al día por cada cuenta Go”.”
¿Cuántas imágenes al día puedes esperar recibir?
A efectos de planificación, ten en cuenta que ChatGPT Go puede generar sin problemas varias docenas de imágenes al día. Yo recomendaría entre 20 y 30 imágenes como rango de trabajo para un día normal, sobre todo si distribuyes las solicitudes a lo largo del día en lugar de enviar un único lote grande.
Este rango resulta útil porque se ajusta a la forma en que la gente planifica realmente el trabajo con imágenes: concepto, variaciones, selección y algunas revisiones. Es posible que observes una mayor capacidad durante los periodos de menor actividad, menor durante los de mayor demanda y una experiencia diferente si OpenAI modifica los límites de los planes. La base pública para la estimación es el posicionamiento del nivel gratuito «10x» de OpenAI, no un límite diario publicado exclusivo para Go.
| Pregunta | Mejor respuesta | Confianza |
|---|---|---|
| ¿Go incluye la generación de imágenes? | Sí. OpenAI incluye el acceso ampliado a la generación de imágenes para Go. | Verificado oficialmente |
| ¿Existe un límite máximo diario fijo para el público? | En la página de ayuda pública de OpenAI no se publica ningún número exclusivo para Go. | Verificado oficialmente mediante la formulación de «ausencia» y «límites» |
| ¿Qué cifra diaria deberías tener en cuenta a la hora de planificar? | Entre 20 y 30 imágenes al día, aproximadamente, para un uso moderado. | Estimación práctica |
En el caso de trabajos para clientes o campañas, dividiría el lote en varias fases: una primera fase de conceptualización, una fase de perfeccionamiento y una fase final de variaciones. De este modo, Go sigue siendo útil sin depender de un proceso prolongado e ininterrumpido de generación de imágenes.
ChatGPT Go, Free y Plus: límites de imágenes
La comparación más importante es entre Free y Go. La versión Free está bien para pruebas ocasionales con imágenes, pero OpenAI señala que la generación de imágenes en la versión Free es limitada y más lenta. Go es el nivel económico para quienes quieren suficiente capacidad para realizar solicitudes habituales sin tener que pasar directamente a Plus.
Los planes Plus y Pro están por encima de Go. Según la página de precios que he consultado, el plan Plus está orientado a la creación de imágenes más complejas y precisas, mientras que el plan Pro se centra en la creación de imágenes al máximo y con mayor rapidez. Esto te da una idea de cómo interpretar los distintos niveles: Go está pensado para un uso habitual a un precio más bajo, mientras que Plus y Pro son los planes con los que OpenAI apuesta por flujos de trabajo de imágenes más exigentes.
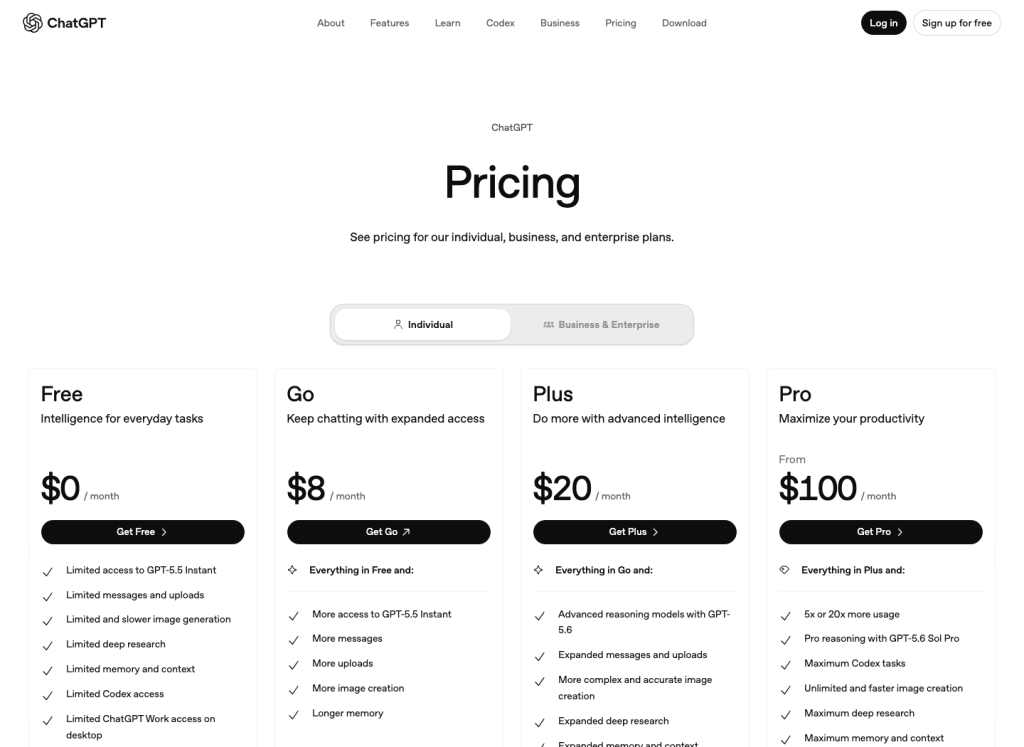
Precios en EE. UU.
La diferencia de precio entre la versión Go y la Plus es mínima; lo que realmente importa es la diferencia en el flujo de trabajo.
En la página de precios de EE. UU. consultada para esta actualización, el plan Go cuesta $8 al mes, el Plus, $20 al mes, y el Pro parte de un precio mucho más elevado. Si solo necesitas generar unas pocas docenas de imágenes, Go es la opción más económica para experimentar. Si el trabajo con imágenes forma parte de tu actividad diaria, compara la facilidad de uso frente a la diferencia de precio.
Fuente: Página de precios de ChatGPT, captura de pantalla de la versión para EE. UU. del 13 de julio de 2026. Los precios locales pueden variar según el mercado y la cuenta.
| Plan | Ajuste de la generación de imágenes | Cómo utilizar esto para tomar decisiones en el Go |
|---|---|---|
| Gratis | Pruebas de iluminación e imágenes esporádicas. | Pasa a la versión superior si sigues alcanzando los límites tras solo unos pocos intentos. |
| ChatGPT Go | Creación diaria de imágenes a un precio más económico. | Utiliza la estimación de 20-30 al día como referencia para planificar un uso moderado. |
| Más | Trabajos de imagen más complejos y avanzados. | Prueba Compare Plus si los límites progresivos de Go interrumpen tu flujo de trabajo. |
| Pro | Creación de imágenes para usuarios avanzados y flujos de trabajo más amplios de uso intensivo. | No utilices la versión Pro como referencia para una suscripción Go económica. |
Si tu pregunta se refiere específicamente a Plus, utiliza el Guía sobre el límite de imágenes de ChatGPT Plus. Si lo que te preguntas es si Go es capaz de crear imágenes, empieza por Guía sobre la función de generación de imágenes de ChatGPT Go. Esta página trata sobre las cantidades y los límites en Go.
Subir imágenes frente a generar imágenes: límites diferentes
Mucha gente confunde tres acciones diferentes:
- Creación de una imagen significa pedirle a ChatGPT que cree una nueva imagen a partir de una indicación.
- Subir una imagen significa adjuntar una imagen ya existente para que ChatGPT pueda examinarla, describirla o editarla.
- Subir un archivo pueden incluir documentos, hojas de cálculo, presentaciones, archivos PDF e imágenes.
La página de ayuda «Imágenes de ChatGPT» de OpenAI confirma que ChatGPT puede crear y editar imágenes. Las preguntas frecuentes sobre la subida de archivos son una fuente diferente, ya que los límites de subida no son los mismos que los límites de generación.
Esa distinción es importante a la hora de planificar un lote de trabajo real. Si subes 15 fotos de productos para su análisis, estás utilizando la capacidad de subida de archivos. Si le pides a ChatGPT que cree 15 nuevos conceptos publicitarios, estás utilizando la capacidad de generación de imágenes. Es posible que un mismo plan de ChatGPT limite ambas cosas, pero no se trata de la misma acción.
Tamaño de los archivos de imagen y límites de subida con ChatGPT Go
En el caso de los archivos subidos, OpenAI publica límites más claros que en el caso de las imágenes generadas exclusivamente con Go. En las preguntas frecuentes sobre la subida de archivos se indica un límite máximo de 512 MB para muchos archivos subidos, un límite de 20 MB para los archivos de imagen, un máximo de 80 archivos subidos cada 3 horas y un límite diario de subida más bajo para los usuarios de la versión gratuita. OpenAI también señala que los límites de subida pueden reducirse durante las horas de mayor tráfico.

Los límites de subida son independientes
OpenAI facilita las cifras de archivos subidos, pero no un contador específico de imágenes generadas exclusivamente por Go.
Estos límites facilitan la subida de imágenes y el análisis de archivos. No indican cuántas imágenes nuevas generará ChatGPT Go al día.
Fuente: Preguntas frecuentes sobre la subida de archivos de OpenAI, consultadas el 13 de julio de 2026.
Para los usuarios de ChatGPT Go, la conclusión práctica es la siguiente: Go ofrece más espacio de almacenamiento que la versión gratuita, pero las subidas siguen estando limitadas, y los límites de imágenes subidas deben mantenerse al margen de la planificación diaria de imágenes generadas.
Cómo funcionan los límites de imágenes en movimiento en la práctica
Los límites de imágenes de ChatGPT se entienden mejor como ventanas de uso continuas que como un reinicio a medianoche. Un usuario que genere ocho imágenes por la mañana, ocho por la tarde y seis por la noche puede tener un día más tranquilo que uno que intente generar 40 imágenes seguidas.
Un flujo de trabajo realista en Go podría ser algo así:
- Por la mañana: entre 6 y 10 imágenes para explorar el concepto.
- Por la tarde: entre 6 y 10 imágenes para perfeccionar el estilo, la maquetación o la línea editorial.
- Por la tarde: entre 4 y 8 imágenes para las variaciones finales.
Esto nos sitúa en el rango de planificación de entre 20 y 30 imágenes, sin dar por sentado que el plan sea ilimitado. Si un lote se atasca, lo más útil es hacer una pausa, guardar la sugerencia más sólida y volver más tarde con una solicitud de variación más concreta.
Disponibilidad y precio de ChatGPT Go
A fecha de 13 de julio de 2026, la página de ayuda de ChatGPT Go de OpenAI indica que Go está disponible en todos los países en los que se ofrece ChatGPT. Esa misma página de ayuda remite a los usuarios a la página de tarifas de ChatGPT para consultar los precios actuales de las suscripciones. La publicación de OpenAI sobre el lanzamiento indica que el precio en EE. UU. es de $8 al mes y señala que las tarifas de Go se adaptan a cada mercado.
En cuanto a los precios, hay dos reglas prácticas:
- Utiliza «$8/mes» cuando te refieras específicamente a los precios de EE. UU.
- Para los lectores que no sean de EE. UU., utilicen el precio que figura en la página oficial de tarifas de ChatGPT o en el proceso de actualización de su cuenta.
Para realizar una comparación de precios más detallada, utiliza el Guía completa de precios de ChatGPT Go. Para consultas sobre el acceso regional, el Guía de disponibilidad en EE. UU. es una lectura muy recomendable para seguir profundizando en el tema.
¿Ofrece ChatGPT Go generación ilimitada de imágenes?
No. ChatGPT Go no ofrece generación ilimitada de imágenes. Se trata de un plan con un presupuesto mayor que el plan gratuito, pero la generación de imágenes sigue suponiendo una carga de trabajo mayor que el chat de texto sin formato, y OpenAI la gestiona mediante límites por plan, ventanas móviles y cambios temporales durante los picos de demanda.
Por eso, “10 veces más que la versión gratuita” puede suponer una mejora significativa y, aun así, no ser suficiente para los creadores que producen grandes volúmenes de contenido. Si solo necesitas imágenes para proyectos de clase, ilustraciones para un blog, conceptos de marketing sencillos o ideas de diseño personales, la versión Go puede parecerte generosa. Si, por el contrario, necesitas muchos recursos finales cada día, las limitaciones imponen más que el precio anunciado.
Si quieres comprender las implicaciones más amplias que van más allá de los límites de las imágenes, lee el Ventajas y limitaciones de ChatGPT Go avería o el ChatGPT Go vs Gratis comparación.
¿Quién debería utilizar ChatGPT Go para la generación de imágenes?
ChatGPT Go es ideal para usuarios que generan imágenes con regularidad, pero no a escala industrial. Es perfecto para estudiantes, creadores ocasionales, pequeñas empresas de marketing, blogueros y personas que desean más espacio que el que ofrece la versión gratuita sin tener que pagar por un plan superior de ChatGPT.
No es la opción más adecuada para los usuarios que necesitan un volumen de producción elevado y predecible, muchas variaciones en el mismo día o una combinación de modelos de imagen y vídeo. Es ahí donde un flujo de trabajo multimodelo deja de parecer un lujo y se convierte en una forma de ahorrar tiempo. Por ejemplo, GlobalGPT’s Área de trabajo de GPT Image 2 puede utilizarse junto con otras herramientas de imagen, vídeo y chat, mientras que el Página de precios de GlobalGPT es el lugar ideal para comparar sus propias tarifas.
La elección adecuada depende de tu carga de trabajo real. Elige «Go» si quieres una actualización de ChatGPT más económica para un uso moderado de imágenes. Elige un plan superior o más amplio si tu trabajo depende de muchas imágenes, de varios modelos o de que haya menos interrupciones durante una jornada de producción.
Resumen de los límites de imágenes de ChatGPT Go
| Pregunta | Mejor respuesta |
|---|---|
| ¿Cuántas imágenes puede generar ChatGPT Go al día? | Calcula unas 20-30 imágenes al día para un uso moderado, pero ten en cuenta que se trata de una estimación. |
| ¿Publica OpenAI un límite máximo fijo de imágenes de Go? | En la página de ayuda no aparece ninguna referencia al número de imágenes diarias exclusivas de Go. |
| ¿Go es ilimitado? | No. La versión Go tiene límites más altos que la versión Free, pero los límites pueden variar. |
| ¿Se aplica el mismo límite tanto a las subidas como a las imágenes generadas? | No. Subir una imagen y generar una nueva imagen son acciones diferentes. |
| ¿Es suficiente Go para el trabajo creativo diario? | Normalmente sí, para un uso moderado, pero no para una producción a gran escala. |
PREGUNTAS FRECUENTES
¿Publica OpenAI un límite diario exacto para la generación de imágenes en ChatGPT Go?
No. OpenAI afirma públicamente que ChatGPT Go incluye más funciones de creación de imágenes que la versión Free y límites de uso más elevados, pero no publica una cifra fija de imágenes diarias exclusiva para la versión Go. Los límites pueden variar en función de las condiciones del sistema.
¿Cuántas imágenes debería prever generar al día con ChatGPT Go?
Una estimación práctica es de unas 20-30 imágenes al día para un uso moderado. Utilízala como referencia, basándote en el límite superior de Go, pero no como una garantía oficial.
¿ChatGPT Go ofrece un uso ilimitado para la generación de imágenes?
No. ChatGPT Go no es ilimitado. Se trata de un plan de pago económico con mayor capacidad que la versión gratuita, pero la generación de imágenes sigue estando sujeta a los límites del plan y a los periodos de uso acumulativos.
¿Cuántas imágenes puedo subir a ChatGPT Go?
Subir imágenes no es lo mismo que generarlas. En la sección de preguntas frecuentes sobre la subida de archivos de OpenAI se establece un límite de 20 MB por archivo de imagen, así como otros límites de subida, mientras que el propio Go ofrece más capacidad de subida que la versión gratuita. Hay que tener en cuenta los límites de subida por separado a la hora de planificar la generación de imágenes.
¿Tiene ChatGPT Go los mismos límites de imágenes que ChatGPT Plus?
No. Go y Plus son planes distintos. Plus está pensado para trabajos más exigentes y avanzados, mientras que Go es la opción más económica para pasar del plan gratuito.
¿Está disponible ChatGPT Go en mi país?
La página de ayuda de ChatGPT Go de OpenAI indica que Go está disponible en todos los países en los que se ofrece ChatGPT a partir del 13 de julio de 2026. La disponibilidad y los precios locales pueden seguir dependiendo de lo que indiquen tu cuenta de ChatGPT y la página oficial de precios.
¿Debería elegir ChatGPT Go o una plataforma multimodelo para imágenes?
Elige ChatGPT Go si lo que buscas principalmente es una versión más económica de ChatGPT para la generación moderada de imágenes. Plantéate optar por una plataforma multimodelo si tu flujo de trabajo también requiere otros modelos de chat, herramientas de investigación, modelos de imágenes o generación de vídeos, todo en un mismo lugar.

