HappyHorse 1.0 vs Seedance 2.0: We Tested Both Models


HappyHorse 1.0 and Seedance 2.0 are currently the most powerful Chinese AI video models of 2026, with HappyHorse dominating text-to-video blind benchmarks and Seedance excelling in multimodal reference control. However, while their cinematic output is groundbreaking, creators trying to compare them often hit immediate roadblocks: HappyHorse 1.0 is largely restricted to complex developer APIs, while Seedance 2.0 suffers from strict geo-blocking and massive generation queues due to recent copyright controversies.
If you are trying to decide which model fits your workflow, the answer depends entirely on your creative approach. HappyHorse 1.0 is the superior choice for prompt-first generation, utilizing a single-stream architecture to deliver unmatched 1080p visual fidelity and native audio synchronization in a single pass. Conversely, Seedance 2.0 acts as a "director-level" engine, offering unparalleled control for complex, multi-shot narratives through diverse image, audio, and video reference inputs.
This comprehensive guide breaks down their blind-test benchmark performances, technical specifications, copyright risks, and specific prompt strategies to help you make an informed decision. For creators looking to bypass current beta and regional restrictions immediately, GlobalGPT offers a unified $10.8 Pro Plan to test these models—alongside Veo 3.1, Wan and Kling—in one seamless dashboard.
Quick Verdict: HappyHorse 1.0 vs Seedance 2.0
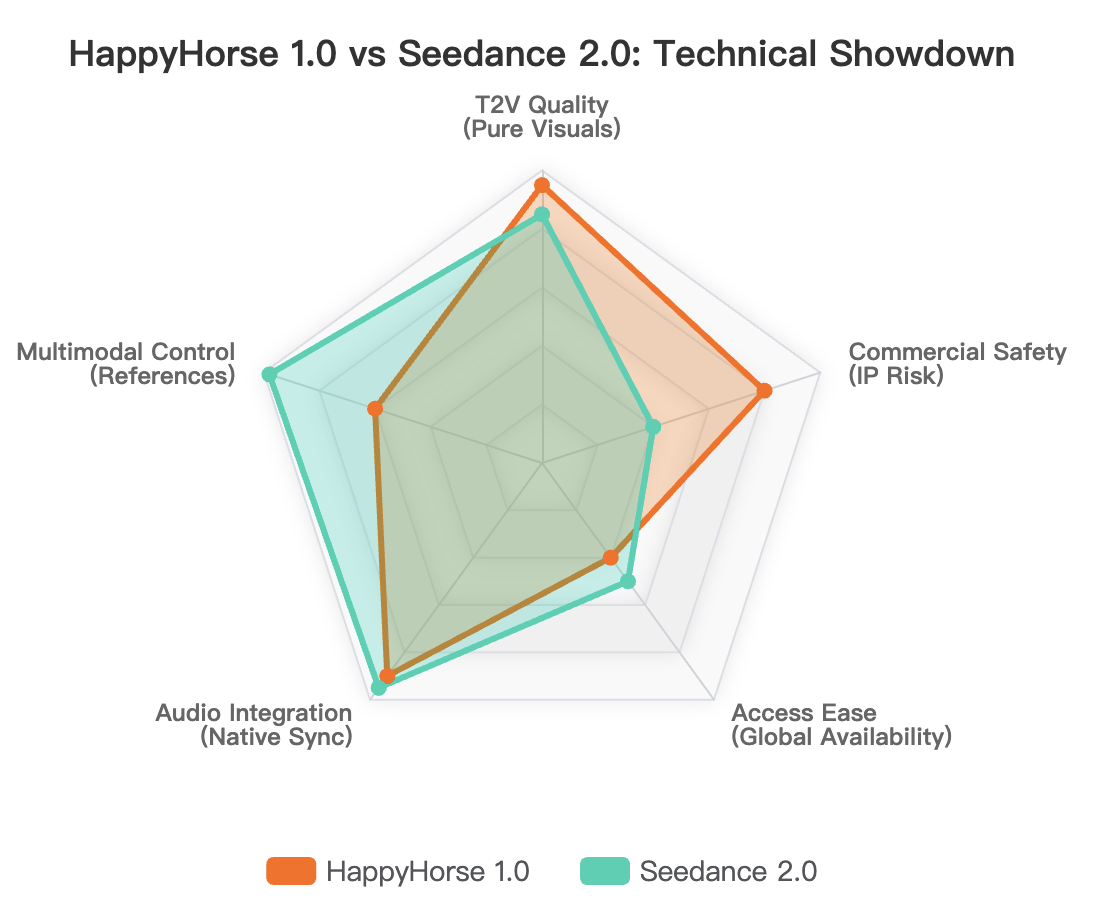
HappyHorse 1.0 and Seedance 2.0 represent the pinnacle of Chinese AI video generation in 2026. Both models are backed by massive tech conglomerates and deliver stunning cinematic realism. However, their core philosophies are entirely different.
According to data from the Artificial Analysis Video Arena, HappyHorse 1.0 is a pure generation powerhouse. It relies on a single-stream architecture to deliver unmatched 1080p visuals and native audio in a single pass. Seedance 2.0, conversely, functions as a highly complex multimodal editor.
If you need the highest quality text-to-video output with minimal prompting, HappyHorse wins. If your workflow demands multi-shot consistency guided by precise image, audio, and video references, Seedance 2.0 is the superior tool.
Use Case | Better Choice |
Best current T2V benchmark performance | HappyHorse 1.0 |
Text-to-video generation | HappyHorse 1.0 |
Image-to-video generation | Tie / depends on platform |
Multimodal reference control | Seedance 2.0 |
Audio-video joint generation | Seedance 2.0 |
Cinematic short clips | HappyHorse 1.0 |
Creator ecosystem | Seedance 2.0 |
Lower copyright controversy | HappyHorse 1.0 (for now) |
More mature official model page | Seedance 2.0 |
What Is HappyHorse 1.0? Alibaba’s Cinematic Dark Horse
A Comprehensive Video Family: T2V, I2V, R2V, and Video Editing
HappyHorse 1.0 is Alibaba’s newest AI video generation model, developed internally by the Alibaba Token Hub (ATH) innovation unit. It was designed with one specific goal: "cinematic creative generation" with ultimate dynamic details.
While initially famous for its text-to-video (T2V) and image-to-video (I2V) dominance, official documentation reveals that HappyHorse is actually a complete video production family. Beyond generating native 1080p clips ranging from 3 to 15 seconds (supporting 16:9, 9:16, 1:1, 4:3, 3:4 aspect ratios), it features a highly advanced Reference-to-Video (R2V) workflow. This allows creators to upload up to 9 reference images alongside a prompt to tightly control character identity, visual style, and scene consistency.
Additionally, HappyHorse includes a powerful Video Edit capability (Video-to-Video). Creators can upload existing footage and use natural language instructions—combined with up to 5 reference images—to execute precise local modifications (e.g., changing a character's outfit) or global transformations (e.g., recoloring a scene's atmosphere). For commercial creators, the takeaway is clear: HappyHorse 1.0 is not just a generation engine from scratch, but an end-to-end production suite capable of generating, guiding, and refining cinematic assets.
For a deeper dive into its exact parameter specs, development history, and extended prompt tutorials, check out our complete guide on [What is HappyHorse 1.0].
The ATH Architecture: Native Joint Audio-Video Generation Explained
What makes HappyHorse groundbreaking is its 15B-parameter, single-stream Transformer architecture. It bypasses the multi-stage pipelines used by every major competitor.
This model does not use cross-attention modules. Instead, it processes video and audio simultaneously in a single forward pass. This allows it to generate perfectly synchronized sound effects, ambient noise, and multilingual lip-sync (across 7 languages) from the very first frame.
Furthermore, its highly efficient 8-step inference means it can generate a 5-second 1080p video in roughly 10 to 38 seconds (depending on the GPU infrastructure), setting a new industry standard for speed without compromising post-production editing control.
What Is Seedance 2.0? ByteDance’s Multimodal Creative Engine
Beyond Prompts: The Power of Multimodal Reference (Image, Audio, Video)
Seedance 2.0 is the next-generation generative media model developed by ByteDance Seed. It is fundamentally different from HappyHorse because it is built on a dual-branch Diffusion Transformer (DiT) architecture.
Seedance 2.0 is not just a text-to-video prompt-taker; it is a unified multimodal audio-video generation system. It acts as an "AI Director," allowing creators to input up to 9 images, 3 video clips, and 3 audio tracks simultaneously to guide the final output.
This makes it exceptionally powerful for professional creators who need strict reference-based control over character consistency, complex lighting, and specific camera movements across multiple shots.
Creator Ecosystem: Integration with Dreamina and BytePlus ModelArk
While HappyHorse is primarily accessed via developer APIs, Seedance 2.0 is deeply embedded into ByteDance’s massive creator ecosystem.
It is designed to power consumer-facing tools like Dreamina (Jimeng) and CapCut Pro. It excels at audio-video joint generation, specifically in matching sound effects to physical collisions and maintaining narrative flow.
However, Seedance 2.0 is much closer to a comprehensive editing engine. This makes it incredibly ambitious, but also much more complicated from a legal, safety, and global access perspective.
Performance Showdown: Benchmark & Feature Comparison
Blind-Test Leaderboard Results (Artificial Analysis Elo Ratings)
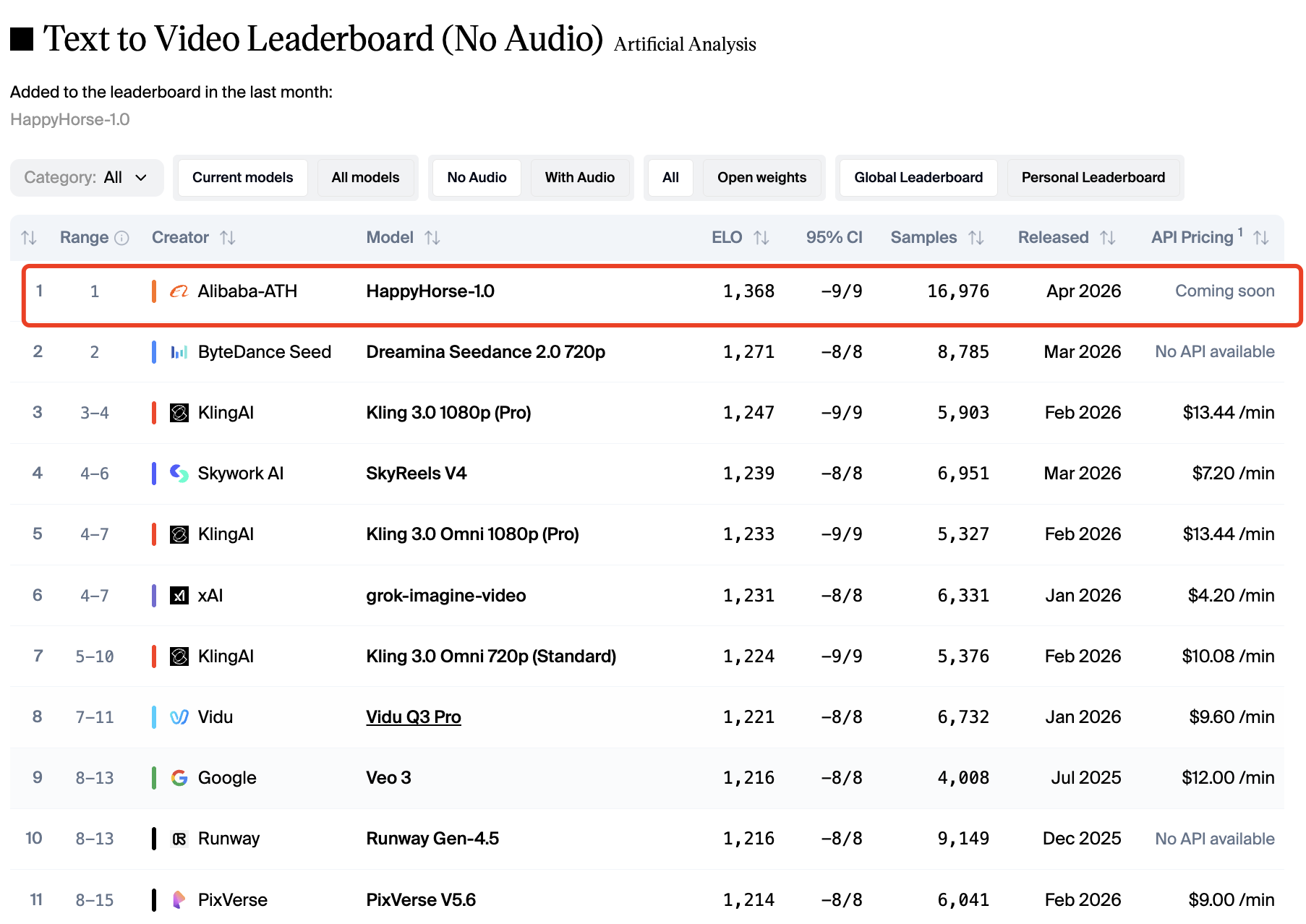
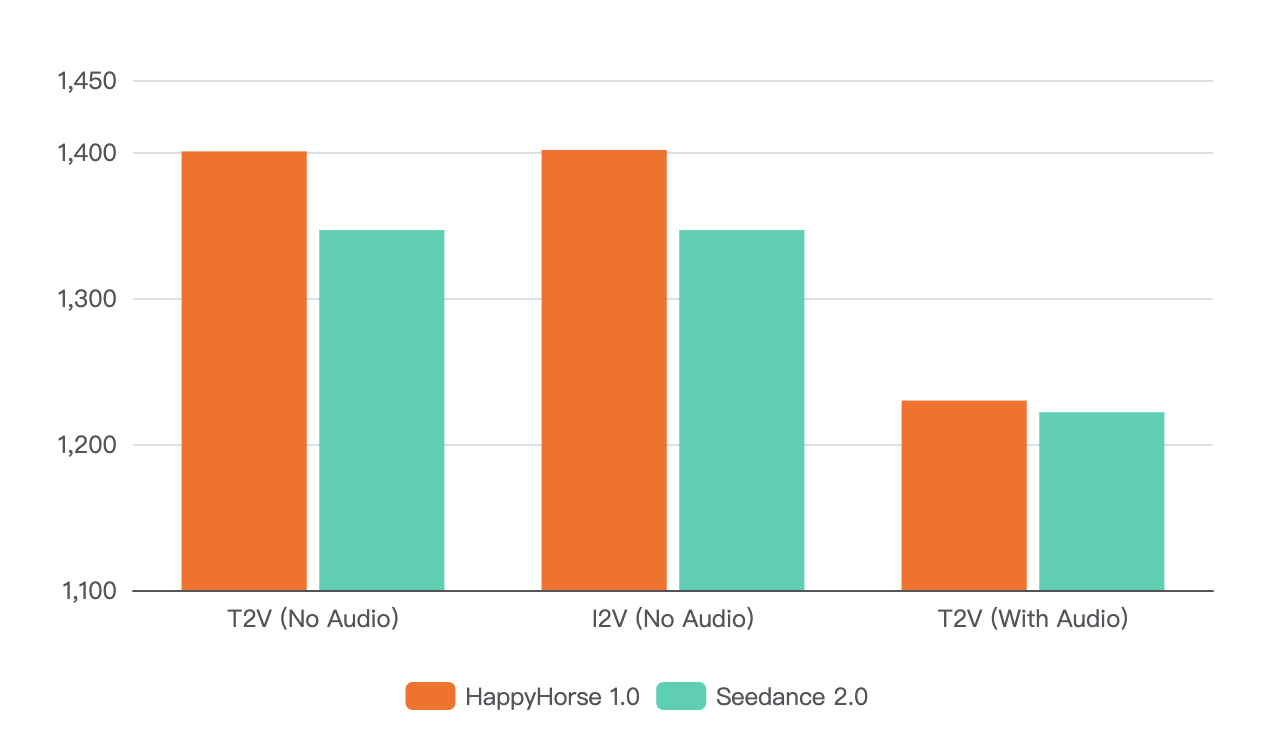
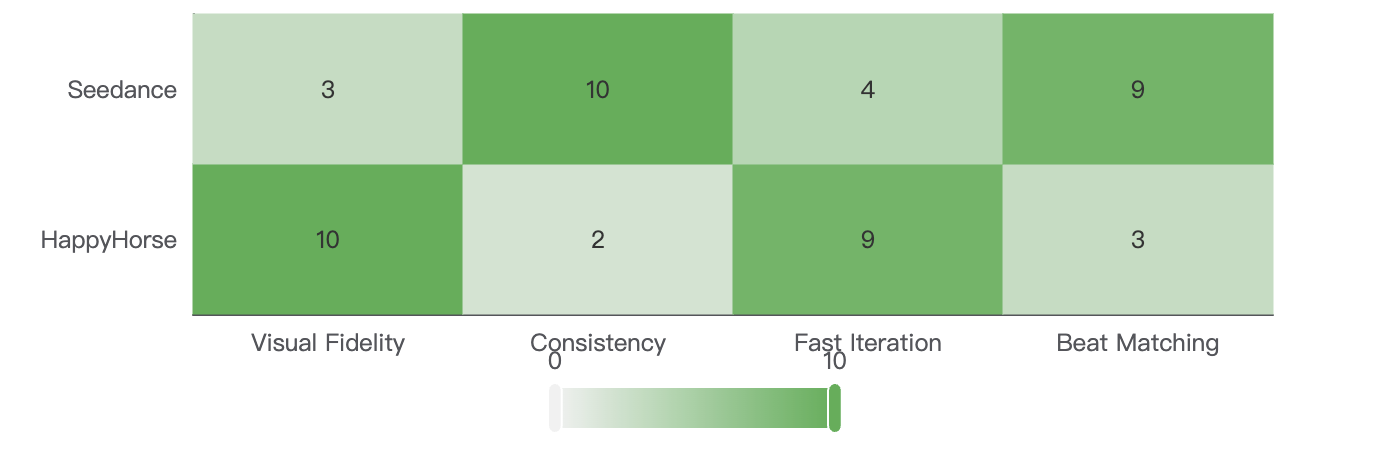
According to the trusted Artificial Analysis Video Arena, HappyHorse 1.0 currently dominates the leaderboards. In the Text-to-Video (No Audio) category, HappyHorse boasts a massive 1401 Elo, significantly outperforming Seedance 2.0's 1347 Elo.
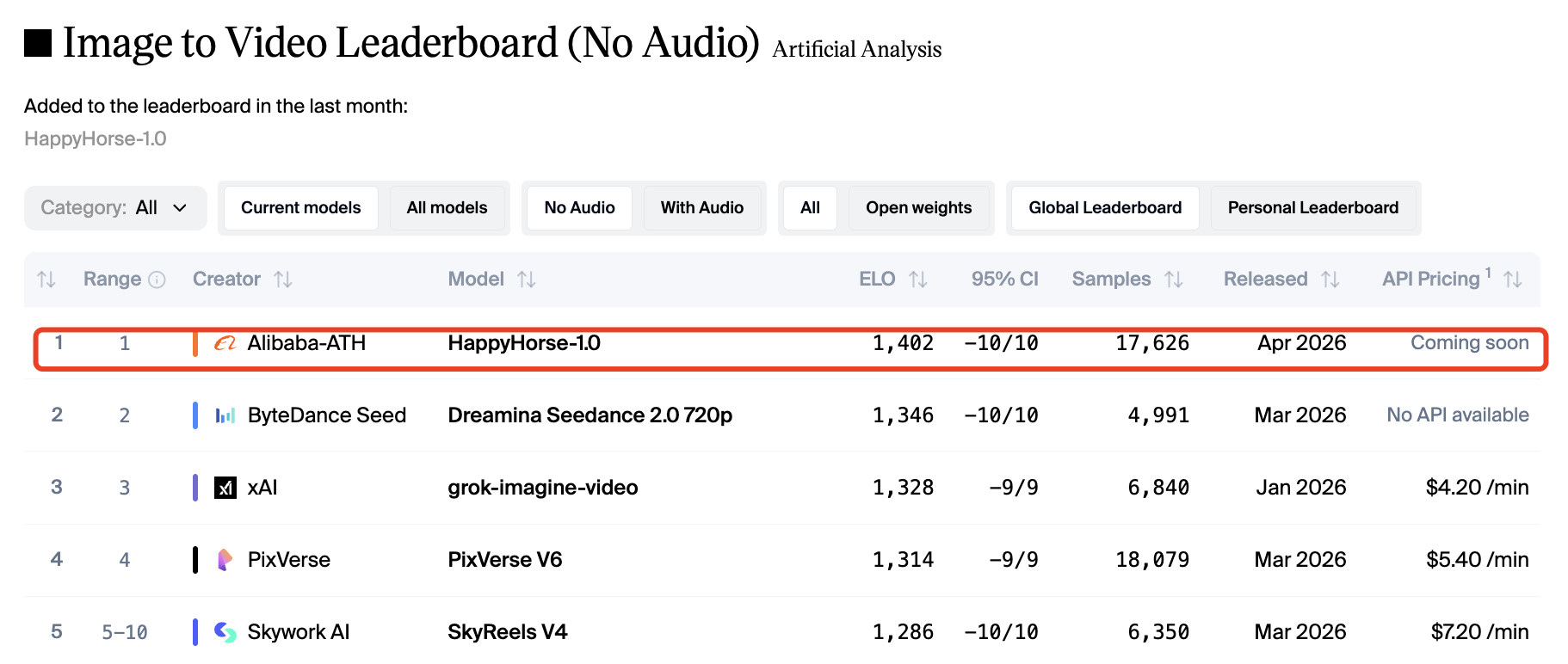
In the Image-to-Video (No Audio) category, HappyHorse hit 1402 Elo. When audio is introduced, HappyHorse still leads with 1230 Elo, closely followed by Seedance 2.0 at 1222 Elo.
These blind-test results indicate that when real humans judge visual quality without knowing the brand, they heavily prefer HappyHorse’s cinematic output. However, leaderboards do not measure editing control or long-workflow consistency.
Technical Feature Matrix: Specs, Resolutions, and Input Modalities
To make the best commercial decision, creators must look past the Elo scores and examine the hard technical limits of each system.
HappyHorse provides a highly streamlined API experience focused on output fidelity. Seedance offers a broader spectrum of inputs but requires navigating complex platform ecosystems.
Feature | HappyHorse 1.0 | Seedance 2.0 |
Text-to-video | Yes (Stronger Quality) | Yes |
Image-to-video | Yes (Highly Detailed) | Yes |
Audio/Video Reference | Not supported natively | Yes (Highly Supported) |
Resolution | 720P / 1080P | Platform-dependent (Up to 2K) |
Duration | 3–15 seconds | Platform-dependent (Up to 15s) |
Best Used For | High-quality short AI clips | Multimodal creator workflows |
Realism vs. Control: Analyzing Motion Stability and Creative Flexibility
HappyHorse 1.0 excels in "Realism." Its single-stream architecture generates incredibly stable physics, natural motion blur, and cinematic lighting with minimal prompt engineering.
Seedance 2.0 excels in "Control." Because it processes audio and video in separate branches that fuse via cross-attention, it is better equipped to handle complex narrative planners, character continuity across shots, and precise audio-visual beat matching.
Prompting & Creative Control: From Text-First to Reference-First
Prompting & Creative Control: From Text-First to Reference-First
The way you communicate with these models dictates the quality of your output. Because their underlying architectures process data differently, your prompting strategies must adapt.
For HappyHorse 1.0, the golden rule is "Brevity Wins." The model performs best with prompts around 20 to 30 words. You must define the core elements—subject, action, lighting, and a single camera movement—clearly and concisely. Stacking too many abstract adjectives ("masterpiece," "ultra-realistic") will confuse the model and dilute the physics engine.
For Seedance 2.0, prompts act as a director's script. Because the model is built around multimodal reference control, you are not just describing a scene; you are directing how the uploaded images, audio, and video interact over time. Focus on character consistency, audio-visual mood, and multi-shot narrative continuity.
If you are looking to master these complex multi-modal commands or want a cheat sheet for text-to-video framing, be sure to read our comprehensive [AI Video Generation Prompt Guide].
Below are three specific use-case comparisons to demonstrate the difference in workflow:
Use Case 1: High-Speed Action & Physics
HappyHorse 1.0 (Text-to-Video Focus):
Prompt: "Close-up of a crystal glass shattering in ultra-slow motion, water splashing outwards, dark background, dramatic rim lighting, high-speed macro cinematography."

Seedance 2.0 (Multimodal Control Focus):
Prompt: "[Reference Image: image1] Animate the glass shattering upon impact from an unseen object. [Reference Audio: audio1] Synchronize the visual shatter exactly to the peak of the audio crash. Maintain the exact lighting of the reference image."

Use Case 2: Character Emotion & Lip-Sync
HappyHorse 1.0 (Image-to-Video Focus):
Prompt: "The woman looks directly at the camera and smiles warmly, natural wind blowing her hair, soft overcast daylight, shallow depth of field, 35mm lens."

Seedance 2.0 (Audio-Driven Narrative Focus):
Prompt: Medium-close-up: A confident 30-year-old woman in a navy blazer smiles warmly in soft studio lighting. [Audio-Visual Sync] She looks at the camera and says clearly: 'Welcome to the future of creative production.' Her lip-sync and expressions must perfectly match her warm voice. [Camera Control] Slow, continuous zoom in. 1080p.
![Prompt: Medium-close-up: A confident 30-year-old woman in a navy blazer smiles warmly in soft studio lighting. [Audio-Visual Sync] She looks at the camera and says clearly: 'Welcome to the future of creative production.' Her lip-sync and expressions must perfectly match her warm voice. [Camera Control] Slow, continuous zoom in. 1080p.](https://statics.mylandingpages.co/static/aaaad6abzhcu6fy5/image/bd802e138b7345bcb756694ba33f9062.gif)
Use Case 3: Cinematic World-Building & Editing
HappyHorse 1.0 (Atmospheric Generation):
Prompt: "A vast alien desert with twin glowing moons, a lone astronaut walking towards the horizon, red dust blowing, wide aerial tracking shot, cinematic sci-fi color grading, 16:9."

Seedance 2.0 (Video-to-Video Transformation):
Prompt: "[Reference Video: Drone shot of a Sahara desert] Transform this desert into an alien landscape with glowing purple sand. Keep the original drone movement and speed completely intact, but change the atmosphere to a dark, cinematic sci-fi style."

If you are comparing HappyHorse 1.0 and Seedance 2.0, it is usually worth testing them against other leading video models. GlobalGPT brings multiple AI video and image models into one platform, so creators can compare different generation styles, prompt behavior, and output quality without switching between separate tools. You can use GlobalGPT to build a more flexible creative pipeline combining LLMs with top-tier video engines.

Pricing & Official Access: Alibaba Cloud vs. BytePlus Cost Structure
Pricing is one of the hardest metrics to compare because both models are highly fragmented across different cloud APIs, beta waitlists, and consumer-facing subscription platforms.
HappyHorse 1.0 Pricing (API & Consumer)
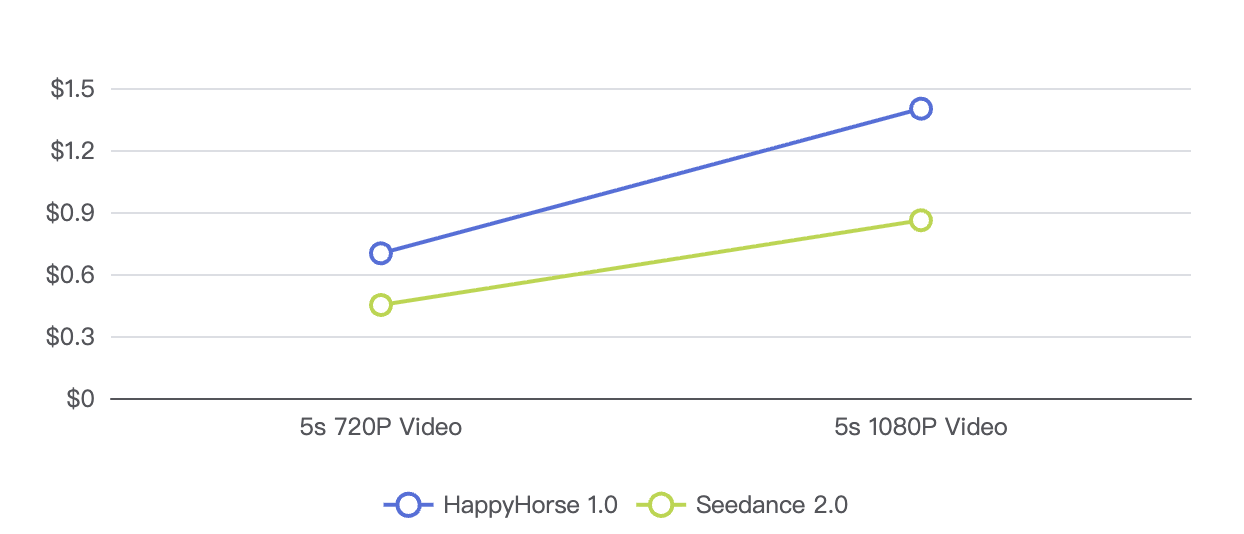
HappyHorse 1.0 pricing is highly transparent for developers. Through the Alibaba Cloud Model Studio and partner APIs , billing is strictly duration and resolution-based. For every second of 720p video generated, you are charged $0.14. For 1080p video, the cost doubles to $0.28 per second.
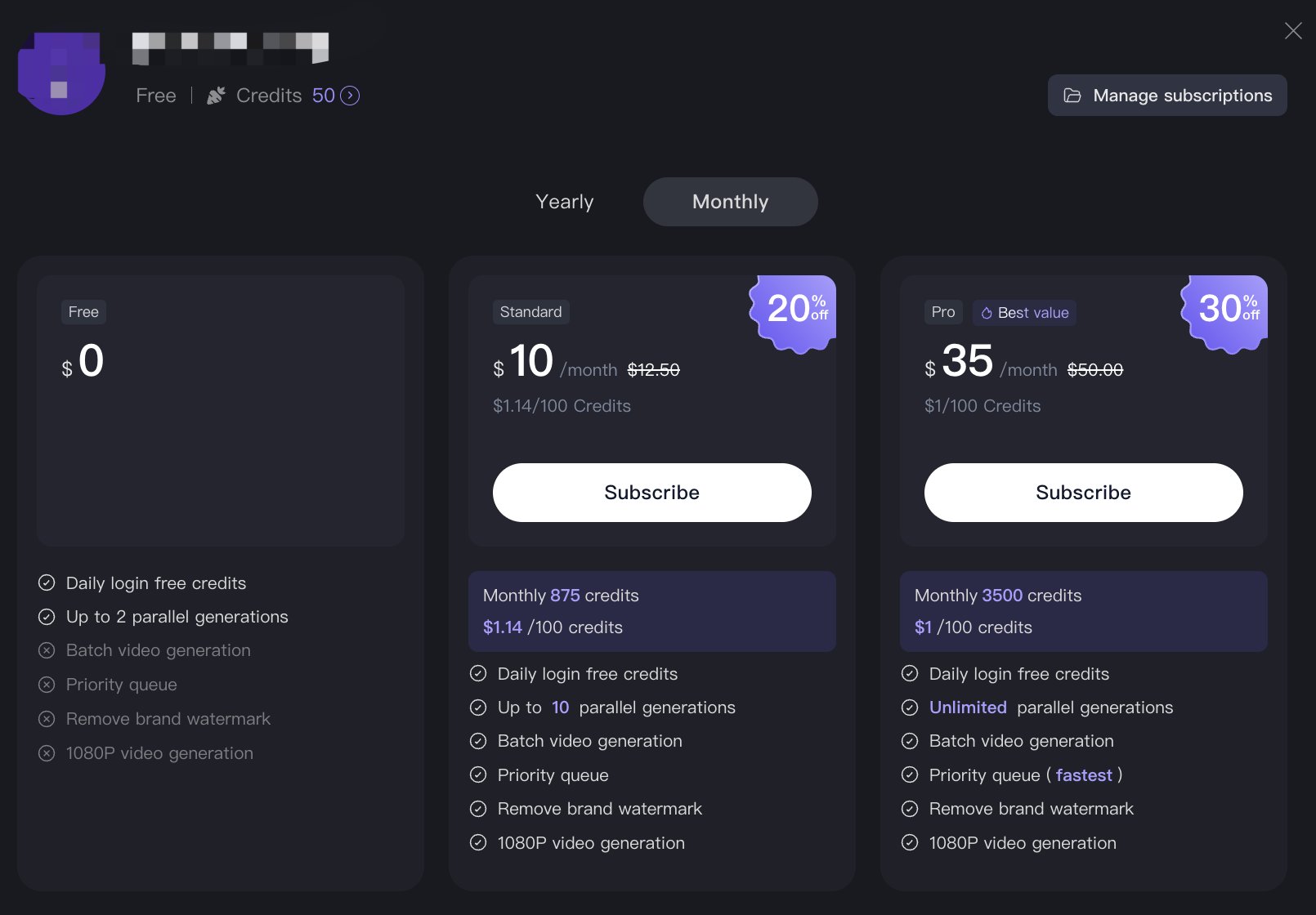
For regular creators who do not want to manage API keys, the official consumer-facing platform (happyhorse.com) offers a credit-based subscription model. New users receive 66 free sign-up credits, and active monthly subscribers can generate a standard 5-second 720p video for as low as $0.32.
Seedance 2.0 Pricing (API & Consumer)
For enterprise users, Seedance 2.0 API access via BytePlus ModelArk follows a pay-as-you-go model ranging from roughly $0.10 to $0.80 per minute of generated video, heavily fluctuating based on generation mode and your account's geographical region.
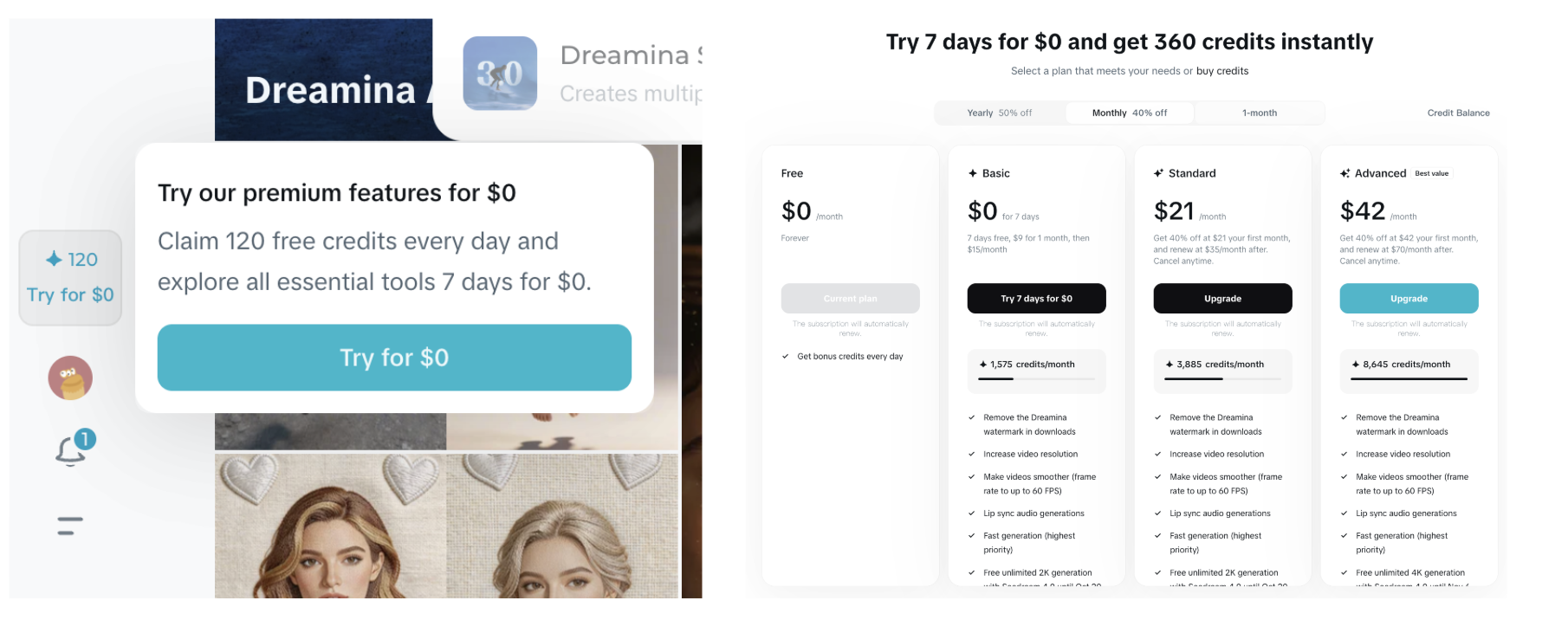
For personal creators, access is primarily routed through ByteDance’s consumer tool, Dreamina (Jimeng). Dreamina utilizes a tiered monthly membership system: the Basic Membership starts at approximately $15/month (7 days free, $9 for 1 month) for 1,575 credits, scaling up to the Standard tier at $35/month (get 40% off at $21 your first month, and renew at $35/month after) for 3,885 credits, and an Advanced tier at ~$70/month (Get 40% off at $42 your first month, and renew at $70/month after) for 8645 credits.
Before choosing either model for your pipeline, check the latest official documentation, as AI video pricing changes rapidly from closed beta to public launch.
Seedance 2.0 and the Hollywood Pushback: Understanding the IP Risks
Technical specs do not matter if you cannot legally or physically access the model. Seedance 2.0 has suffered massive global rollout delays due to severe copyright controversies.
ByteDance faced severe pushback from Hollywood studios (including Disney) and unions like SAG-AFTRA over the generation of copyrighted characters and celebrity likenesses. Furthermore, their "Face-to-Voice" feature sparked identity theft terrors, leading to feature suspensions. Consequently, Seedance 2.0 is heavily geo-blocked and strictly moderated.
HappyHorse 1.0: Developer API Focus and ToC Access Gaps
HappyHorse 1.0 has avoided major copyright scandals thus far, largely because it lacks a massive consumer-facing application like Dreamina.
However, its access barrier is technical. It is heavily focused on developer APIs. For non-coders, finding a reliable, zero-code platform to use HappyHorse without managing cloud infrastructure is currently a significant hurdle.
Risk Area | Recommendation |
Copyrighted characters | Avoid direct use unless licensed. |
Celebrity likeness | Avoid realistic impersonation to prevent bans. |
Client work | Review platform terms and output rights before delivery. |
Reference images | Only use assets you legally own or license. |
Final Decision: Which Model Should You Use for Your Next Project?
Choosing between the two best AI video models in China comes down to your creative philosophy.
Choose HappyHorse 1.0 if:
You prioritize pure visual quality and T2V leaderboard dominance.
You want stunning cinematic short clips in 1080p without complex editing.
Your workflow is prompt-first, requiring fast, single-pass generation.
You are comfortable navigating developer APIs or dedicated third-party platforms.
Choose Seedance 2.0 if:
Your projects demand complex, multi-modal reference control.
You rely heavily on image, audio, or video inputs to guide the AI.
You need audio-video joint generation tailored to precise narrative beats.
You have the patience to navigate platform waitlists and strict copyright filters.
For pure text-to-video quality, HappyHorse 1.0 is currently the more convincing choice. For multimodal creative workflows, Seedance 2.0 remains one of the most powerful options available today.
Experience the Full AI Video Ecosystem with GlobalGPT
Navigating beta waitlists, API keys, and regional copyright blocks should not be your full-time job. With GlobalGPT, you can bypass the friction of accessing restricted Chinese AI models and focus entirely on creating. Start exploring the world's top visual engines and compare results in real-time, all within a single, powerful creative dashboard.
Frequently Asked Questions (FAQs)
Is HappyHorse 1.0 better than Seedance 2.0?
HappyHorse 1.0 currently scores higher in text-to-video benchmark rankings for raw cinematic quality. However, Seedance 2.0 is superior for workflows requiring multimodal reference control and complex audio-video editing.
Does HappyHorse 1.0 support image-to-video?
Yes. HappyHorse 1.0 natively supports image-to-video generation through documented API platforms, animating a reference image with optional text prompts at 1080p resolution.
Does Seedance 2.0 support audio input?
Yes. Seedance 2.0 is a true multimodal system that supports text, image, audio, and video reference inputs to guide the final output.
Which model is safer for commercial use?
Neither is entirely risk-free. HappyHorse 1.0 currently faces fewer public controversies, but creators must actively avoid generating copyrighted characters or celebrity likenesses on both platforms.
Is Seedance 2.0 available globally?
Global availability for Seedance 2.0 has been delayed and is subject to strict regional blocks and platform restrictions due to ongoing copyright and IP-related disputes.