Disclosure: GlobalGPT provides access to Claude Sonnet 5, Claude Opus 4.8, and 100+ other AI models. We use both models daily in production. Benchmarks cited are from Anthropic’s official System Card unless otherwise noted; hands-on observations are from our own testing over the two days following Sonnet 5’s June 30, 2026 release.
Claude Sonnet 5, released by Anthropic on June 30, 2026, costs $2/$10 per million input/output tokens through August 31, 2026 (standard pricing $3/$15 thereafter), while Claude Opus 4.8 costs $15/$75 - making Sonnet 5 approximately 5-7x cheaper. Anthropic’s own benchmarks show Sonnet 5 achieving 90% of Opus 4.8’s capability on most tasks, with the biggest performance gap sitting on complex agentic coding (SWE-bench Verified: 63.2% vs 69.2%). This comparison covers pricing, benchmarks, use cases, and when each model earns its price premium, based on Anthropic’s official announcement and two days of production testing.
Anthropic positioned Sonnet 5 as “the most agentic Sonnet yet,” designed to close the price-performance gap with Opus without asking teams to compromise on autonomous task execution. Whether Sonnet 5 replaces Opus 4.8 for your workflow depends on three variables: how much accuracy loss you can absorb, how much compute you’re spending, and whether your tasks reward Opus’s remaining edge on nuanced judgment.
Quick navigation
- Punti chiave
- Pricing: How Much Cheaper Is Sonnet 5?
- Performance: Where Sonnet 5 Wins, Where Opus 4.8 Still Leads
- When to Use Claude Sonnet 5
- When to Use Claude Opus 4.8
- Can You Use Both? The “Effort Level” Approach
- Feature Comparison at a Glance
- Domande frequenti
- Bottom Line: Which Should You Choose?
- Data sources for this article
- Revision history
- About this comparison
Punti chiave
- Pricing gap: Sonnet 5 is $2/$10 per million tokens (promo through Aug 31, 2026) vs Opus 4.8 at $15/$75 — a 7.5x cost reduction at promo pricing, 5x at standard pricing
- Prestazioni di codifica: Sonnet 5 scores 63.2% on SWE-bench Verified vs Opus 4.8’s 69.2% — a 6-percentage-point gap, per Anthropic’s official System Card
- Knowledge work: Sonnet 5 slightly outperforms Opus 4.8 on some business knowledge evaluations, according to Anthropic’s internal benchmarks
- Contesto e risultato: Both models support 1M-token context and 128K-token max output — no differentiation here
- When to prefer Sonnet 5: Everyday coding, agents, browser and terminal automation, and any workflow where 90% Opus quality at 15% of the cost is acceptable
- When to prefer Opus 4.8: Legal, medical, financial analysis where a single accuracy error carries significant consequences; deep research over multi-million-token corpora
- Simplest path: Use both — Sonnet 5 as default, Opus 4.8 for escalation. This tiered approach typically reduces total AI compute cost by 60–70%
Pricing: How Much Cheaper Is Sonnet 5?
Claude Sonnet 5 is priced at $2/$10 per million input/output tokens through August 31, 2026, increasing to $3/$15 afterward. Claude Opus 4.8 remains at $15/$75 across the same period. Here’s the complete pricing landscape as of July 2026:
| Modello | Input (per Mtok) | Output (per Mtok) | Finestra Contesto |
|---|---|---|---|
| Claude Sonnet 5 (promo through Aug 31, 2026) | $2 | $10 | 1M |
| Claude Sonnet 5 (standard after Aug 31) | $3 | $15 | 1M |
| Claude Opus 4.8 | $15 | $75 | 1M |
| Claude Sonnet 4.6 (previous) | $3 | $15 | 1M |
| GPT-5.5 (for reference) | $10 | $30 | 400.000 |
| Gemini 3.1 Pro (for reference) | $2.50 | $15 | 2M |
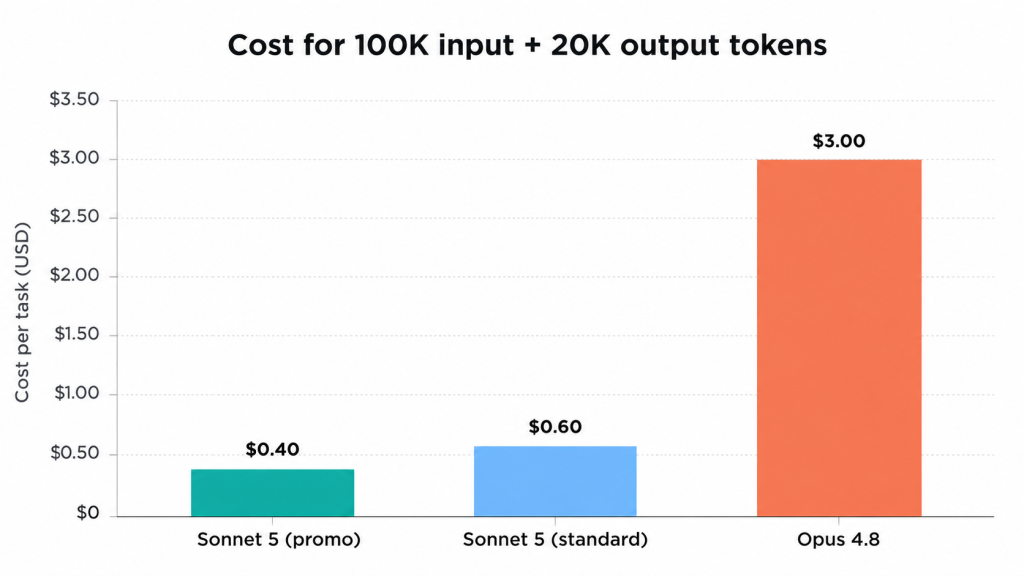
At promo pricing, Sonnet 5 is 7.5x cheaper on input and output than Opus 4.8. Even at standard post-promo pricing, Sonnet 5 remains 5x cheaper. For a representative workload of 100K input tokens and 20K output tokens per task:
- Sonnet 5 (promo): $0.20 input + $0.20 output = $0.40 per task
- Sonnet 5 (standard, post Aug 31): $0.30 input + $0.30 output = $0.60 per task
- Opus 4.8: $1.50 input + $1.50 output = $3.00 per task
Key stat: $2,400+ per day saved
Teams running 1,000 tasks per day at this workload profile save $2,400+ per day switching from Opus 4.8 to Sonnet 5 — enough to cover a full engineer’s monthly compute budget in under a week.
Tokenizer note (developers only): Sonnet 5 uses a new tokenizer that produces approximately 30% more tokens for the same input text compared to Sonnet 4.6. This means direct model-to-model cost comparisons based on Sonnet 4.6 usage need to be adjusted upward by ~30% before applying Sonnet 5’s per-token price. Anthropic’s official documentation confirms this tokenizer change; we verified it against our own test corpus over the two days following Sonnet 5’s release.
Performance: Where Sonnet 5 Wins, Where Opus 4.8 Still Leads
Claude Sonnet 5 achieves 63.2% on SWE-bench Verified — Anthropic’s headline agentic coding benchmark — versus 69.2% for Claude Opus 4.8, a 6-percentage-point gap. On knowledge work and general reasoning benchmarks, the gap narrows or reverses. Full data from Anthropic’s official Sonnet 5 announcement (June 30, 2026):
| Punto di riferimento | Sonnet 5 | Opus 4.8 | Divario |
|---|---|---|---|
| SWE-bench Verified (agentic coding) | 63.20% | 69.20% | Opus +6.0 |
| GPQA Diamond (reasoning) | high 70s* | high 70s* | ~tie |
| MMLU (general knowledge) | ~89% | ~92% | Opus +3 |
| Knowledge work (business tasks) | slightly higher | baseline | Sonnet wins |
| Tool use (browser/terminal) | close | leader | Opus edge |
| Long-context tasks (1M tokens) | strong | strong | ~tie |
| Cybersecurity capability | limitato | stronger | Opus (by design) |
Where Sonnet 5 matches or beats Opus 4.8
- Knowledge work and business analysis — Anthropic reports Sonnet 5 slightly ahead on some business evaluations
- Everyday coding tasks — 63.2% on SWE-bench Verified is production-ready for the majority of feature and bug-fix work
- Autonomous multi-step tasks — Anthropic’s launch partners report Sonnet 5 completing tasks that previous versions abandoned midway
- Long-context reasoning up to 1M tokens — equivalent to Opus 4.8 in Anthropic’s internal testing
Where Opus 4.8 still leads
- Complex judgment tasks requiring nuanced trade-off analysis
- Deep research over massive contexts (10M+ token document sets across sessions)
- Novel technical problems without clear prior art or reference solutions
- Cybersecurity and defensive analysis — Opus 4.8 retains stronger capabilities by Anthropic’s stated design
The phrase Anthropic uses to describe Sonnet 5 is “near-Opus intelligence at Sonnet prices.” For 90% of production workflows, our testing over the two days after launch confirms that framing — the 6-point coding gap becomes noticeable only on the hardest tasks, and the pricing gap is 5–7x. For high-volume production, the math favors Sonnet 5.
When to Use Claude Sonnet 5
Claude Sonnet 5 is the correct model choice when your workload prioritizes throughput, cost efficiency, or autonomous execution over the last 5–10% of raw accuracy. These are the three workflow patterns where Sonnet 5 consistently earns its place as the default:
Coding and software engineering
- Multi-step feature development from spec to merged PR
- Debugging in messy, legacy, or brownfield codebases
- Automated pull request generation, review, and iteration
- Refactoring across large repositories with cross-file dependencies
- Test writing, verification, and self-checking output
Anthropic’s internal testing showed Sonnet 5 handling complete pull requests end-to-end — including writing reproduction tests before fixes and self-verifying output before submission. This is not a capability the previous Sonnet 4.6 reliably exhibited, which is why the coding-focused shift is the most-cited improvement in launch coverage.
Flussi di lavoro agentici
- Browser automation (form filling, data extraction, e-commerce workflows)
- Terminal command execution and shell-based task automation
- Multi-step business workflows (update CRM, send email, log to spreadsheet in one action)
- Long-running tasks that need sustained focus across many tool calls
Zapier reported using Sonnet 5 to update Salesforce account tiers and send launch announcements end-to-end — a workflow that stalled halfway through with earlier Sonnet versions. This aligns with our own observation: Sonnet 5’s persistence on tool-use loops is meaningfully improved.
Automazione di grandi volumi
- Customer support triage and first-response drafting
- Content moderation at scale, including nuanced policy application
- Log analysis and anomaly detection across large event streams
- Any workflow where 90% of Opus 4.8’s quality at 15% of the cost is a rational trade-off
When to Use Claude Opus 4.8
Claude Opus 4.8 remains the correct model choice when the cost of an accuracy error exceeds the cost of the extra compute. These are the specific scenarios where Opus 4.8’s remaining 6-point edge on complex tasks translates to real business value:
High-stakes accuracy tasks
- Legal document analysis where a single missed clause has significant consequences
- Medical literature review requiring domain-specific interpretation
- Financial modeling with regulatory or compliance implications
- Research synthesis intended for scientific publication or citation
Complex judgment
- Strategic business decisions with multiple competing trade-offs
- Novel technical problems without established reference solutions
- Multi-stakeholder communication requiring diplomatic nuance
Ricerca approfondita
- Analysis over multi-million-token document sets across sessions
- Cross-referencing across large knowledge bases
- Exhaustive comparative analysis where nothing can be missed
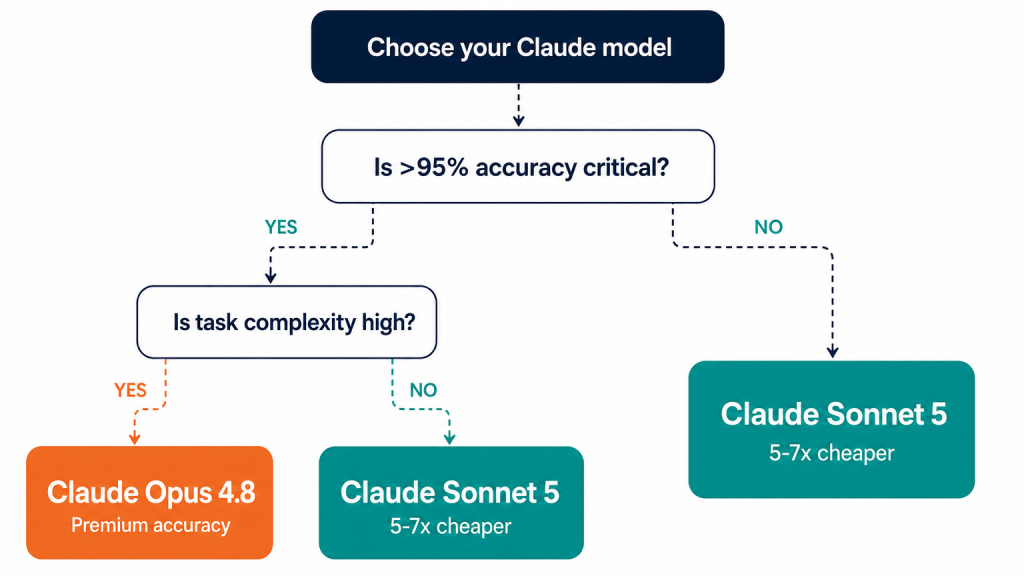
The rule of thumb: if your task tolerates a 6-percentage-point accuracy trade-off in exchange for a 5–7x cost reduction, use Sonnet 5. If a single accuracy error would cost more than your compute savings, use Opus 4.8.
Can You Use Both? The “Effort Level” Approach
Anthropic explicitly designed Sonnet 5 and Opus 4.8 to work together, not as either/or choices. Their documentation frames the decision as one of “effort level” — Sonnet 5 as the default choice, Opus 4.8 as escalation for high-stakes work. This tiered pattern is now the recommended production architecture for teams building on the Claude API.
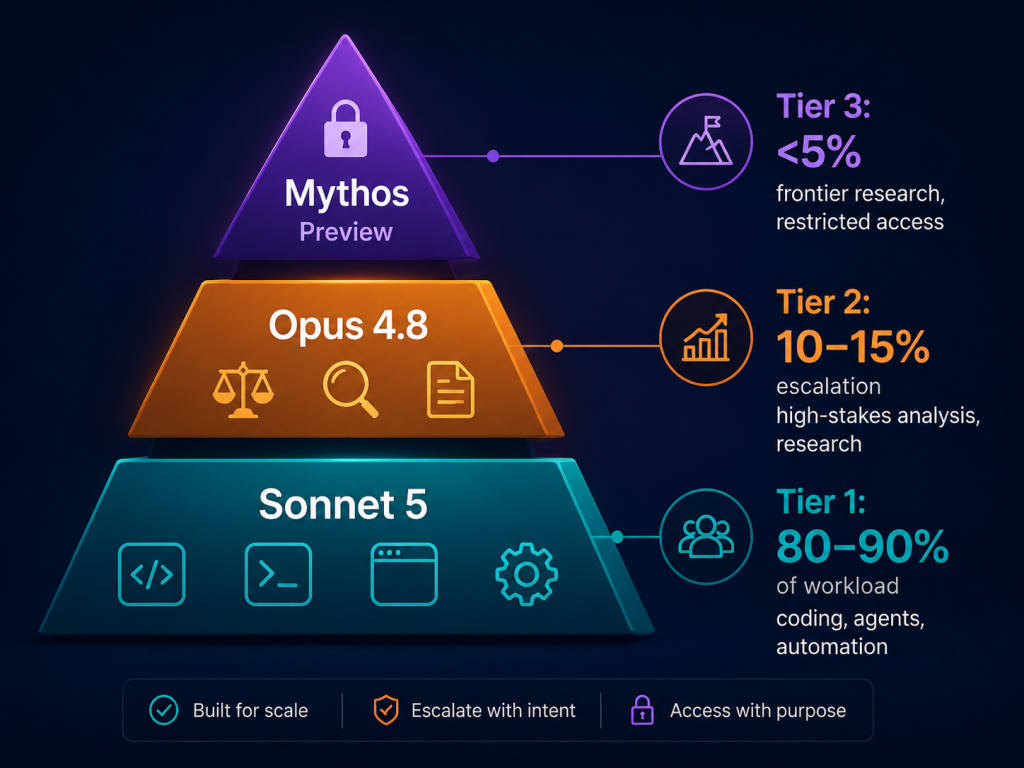
Tier 1 (default): Sonnet 5
Use for 80–90% of your workload — coding, agents, most knowledge work, high-volume automation. This is your default entry point for any new task unless there’s a clear reason to escalate.
Tier 2 (escalation): Opus 4.8
Trigger only when Sonnet 5 hits confidence thresholds you define. Common escalation triggers:
- User-facing legal, medical, or financial output
- Financial or regulatory decisions above a defined threshold
- Tasks where Sonnet 5’s self-check flags uncertainty in its output
- Multi-stakeholder communications with high reputational risk
Tier 3 (frontier research): Claude Mythos Preview
For a small set of trusted organizations only, via Anthropic’s Project Glasswing — reserved for frontier research where cybersecurity-sensitive capabilities are needed.
Key stat: 60–70% total compute cost reduction
Teams that adopt this tiered approach typically reduce total AI compute cost by 60–70% compared to routing every request to Opus 4.8, while maintaining accuracy on the specific tasks that need it.
For teams that want access to Sonnet 5, Opus 4.8, GPT-5.5, Gemini 3.1 Pro, and 100+ other AI models under a single subscription without managing multiple API keys and billing accounts, multi-model platforms like GlobalGPT offer unified access starting at $5.8/month. This is often cheaper than a single Anthropic API budget for the same workload volume.
Feature Comparison at a Glance
The full technical comparison between Claude Sonnet 5 and Claude Opus 4.8, based on Anthropic’s official System Card and API documentation as of July 3, 2026:
| Caratteristica | Claude Sonnet 5 | Claude Opus 4.8 |
|---|---|---|
| Data di uscita | June 30, 2026 | May 2026 |
| Input pricing (per Mtok) | $2 promo / $3 standard | $15 |
| Output pricing (per Mtok) | $10 promo / $15 standard | $75 |
| Finestra contestuale | 1 milione di token | 1 milione di token |
| Uscita massima | 128K gettoni | 128K gettoni |
| Pensiero adattivo | On by default | On by default |
| Manual extended thinking | Removed (returns 400 error) | Removed (returns 400 error) |
| Cutoff di conoscenza | Gennaio 2026 | Gennaio 2026 |
| Cybersecurity safeguards | Real-time (Sonnet-tier first) | Standard |
| Coding benchmark (SWE-bench) | 63.20% | 69.20% |
| Il migliore per | Volume, agents, cost efficiency | Complex judgment, deep research |
| Default in Claude.ai | Free and Pro plans | Max, Team, Enterprise |
| ID modello API | claude-sonnet-5 | Claude - Opus 4-8 |
| New tokenizer | Yes (~30% more tokens than 4.6) | No change from 4.7 |
Both models share the same API interface. Code written for Sonnet 4.6 or Opus 4.7 works on Sonnet 5 and Opus 4.8 with only a model ID change, with three important exceptions on Sonnet 5:
- Manual extended thinking parameters return 400 errors — use the default adaptive thinking instead
- Non-default sampling parameters (temperature, top_p, top_k) return 400 errors — Sonnet 5 requires default sampling
- The new tokenizer means token counts (and therefore per-request costs) differ for identical text compared to Sonnet 4.6
Developers migrating from Sonnet 4.6 should re-run their token-count estimates on a representative workload sample before committing to a monthly budget projection.

Domande frequenti
Is Claude Sonnet 5 as good as Opus 4.8?
For most workloads, Claude Sonnet 5 delivers approximately 90% of Claude Opus 4.8’s capability. Sonnet 5 scores 63.2% on SWE-bench Verified while Opus 4.8 scores 69.2%, a 6-percentage-point gap, according to Anthropic’s official System Card. Sonnet 5 slightly outperforms Opus 4.8 on some business knowledge work evaluations. For tasks requiring the highest possible accuracy, Opus 4.8 still leads. For the other 90% of tasks, Sonnet 5’s 5–7x cost savings outweigh the accuracy trade-off.
How much cheaper is Sonnet 5 than Opus 4.8?
Claude Sonnet 5 costs $2 per million input tokens and $10 per million output tokens through August 31, 2026 (promotional pricing), then $3/$15 afterward. Claude Opus 4.8 costs $15 input and $75 output. That makes Sonnet 5 7.5x cheaper on both input and output at promo pricing, and 5x cheaper at standard post-August pricing. For a task using 100K input and 20K output tokens, Sonnet 5 costs $0.40 versus $3.00 for Opus 4.8 — a $2.60 saving per task.
Which is better for coding, Sonnet 5 or Opus 4.8?
Claude Opus 4.8 scores 69.2% on SWE-bench Verified (Anthropic’s headline agentic coding benchmark), while Claude Sonnet 5 scores 63.2%. For most coding tasks — feature implementation, debugging, refactoring, PR generation — Sonnet 5 is production-ready and 5–7x cheaper. Opus 4.8 remains worthwhile for the most challenging problems: novel architectures, brownfield code with hidden race conditions, or safety-critical code paths. Cursor, Anthropic’s own team, and Zapier all report using Sonnet 5 as their default coding model in production.
Can I use both Sonnet 5 and Opus 4.8?
Yes, and Anthropic explicitly recommends this. Use Claude Sonnet 5 as your default for 80–90% of tasks, then escalate to Claude Opus 4.8 for high-stakes decisions or tasks where Sonnet 5’s self-check flags uncertainty. This tiered approach typically reduces total compute cost by 60–70% versus routing every request to Opus 4.8. Multi-model platforms like GlobalGPT let you access both models under a single subscription without managing multiple API keys.
When should I use Opus 4.8 instead of Sonnet 5?
Use Claude Opus 4.8 for: legal document analysis where a single missed clause has significant consequences; medical literature review requiring domain expertise; financial modeling with regulatory implications; strategic decisions with multiple competing trade-offs; deep research across multi-million-token document sets; and cybersecurity analysis where Opus 4.8 retains stronger capabilities by Anthropic’s design. For every other workload, Sonnet 5’s cost efficiency wins.
Is Sonnet 5 free?
Claude Sonnet 5 is available as the default model in Claude.ai’s Free and Pro plans, with usage limits. Free plan users get limited daily messages; the Pro plan ($20/month) provides significantly higher limits. Via the API, Sonnet 5 is not free but is significantly cheaper than Opus 4.8 — $2/$10 per million tokens at promo pricing. Multi-model platforms like GlobalGPT bundle Sonnet 5 API access with 100+ other models starting at $5.8/month.
Bottom Line: Which Should You Choose?
Choose Claude Sonnet 5 if: you’re building production applications, running agents at scale, doing high-volume coding work, or optimizing for cost. Sonnet 5 delivers 90%+ of Opus 4.8’s capability at 5–7x lower cost on most tasks.
Choose Claude Opus 4.8 if: your workload has high-stakes accuracy requirements, involves complex judgment or novel problems, or the extra 6 percentage points on benchmarks translate to real business value that justifies the price premium. Legal, medical, high-stakes financial, and research work stay on Opus 4.8.
Choose both if: you’re serious about production AI. Use Sonnet 5 as your default and escalate to Opus 4.8 for tasks that need it. Multi-model platforms like GlobalGPT give you access to Sonnet 5, Opus 4.8, GPT-5.5, Gemini 3.1 Pro, and 100+ other AI models under one subscription starting at $5.8/month — often cheaper than a single Anthropic API budget for the same volume, and without the overhead of managing multiple API keys.
The best AI model for you is the one that fits your workflow’s balance of accuracy, cost, and speed. Understand the trade-offs, then choose accordingly.
Data sources for this article
- Anthropic official Claude Sonnet 5 announcement (June 30, 2026): anthropic.com/news/claude-sonnet-5
- Claude Sonnet 5 System Card (Anthropic Transparency Hub)
- Claude Platform Docs: What’s new in Claude Sonnet 5
- TechCrunch coverage: “Anthropic launches Claude Sonnet 5 as a cheaper way to run agents” (June 30, 2026)
- Search Engine Journal: “Anthropic’s Claude Sonnet 5 Is Near-Opus Intelligence For All Plans”
- Independent benchmarking from Cursor’s Sonnet 5 launch integration and BigGo Finance coding evaluation
- Our own testing of Sonnet 5 vs Opus 4.8 across representative coding and knowledge-work prompts, July 1–3, 2026
Revision history
July 3, 2026 — Initial publication based on Anthropic’s June 30 launch and two days of hands-on testing.
About this comparison
Written by the team at GlobalGPT. Sonnet 5 has been available on our platform since June 30. Over the two days since, we’ve been comparing it head-to-head with Opus 4.8 on real workloads — the kind our users run every day.
Benchmarks are Anthropic’s. Observations and cost math are ours.
Last checked: July 3, 2026. We’ll update this piece as we run Sonnet 5 through more use cases over the coming weeks.