การเปิดเผยข้อมูล: GlobalGPT ให้คุณเข้าถึง Claude Sonnet 5, Claude Opus 4.8 และโมเดล AI อีกกว่า 100 แบบ เราใช้ทั้งสองโมเดลนี้ในระบบผลิตจริงทุกวัน ผลวัดประสิทธิภาพที่อ้างอิงมาจากการ์ดระบบอย่างเป็นทางการของ Anthropic เว้นแต่จะระบุไว้เป็นอย่างอื่น ส่วนผลการสังเกตจากการใช้งานจริงมาจากการทดสอบของเราเองในช่วงสองวันหลังจากการเปิดตัว Sonnet 5 เมื่อวันที่ 30 มิถุนายน 2026.
Claude Sonnet 5, ที่เปิดตัวโดย Anthropic เมื่อวันที่ 30 มิถุนายน 2026, มีค่าใช้จ่าย $2/$10 ต่อหนึ่งล้านโทเคนอินพุต/เอาต์พุต จนถึงวันที่ 31 สิงหาคม 2026 (ราคาปกติ $3/$15 หลังจากนั้น) ส่วน Claude Opus 4.8 มีค่าใช้จ่าย $15/$75 — ทำให้โซเน็ต 5 มีจำนวนประมาณ 5–ถูกกว่า 7 เท่า. ผลการทดสอบมาตรฐานของ Anthropic เองแสดงให้เห็นว่า Sonnet 5 สามารถบรรลุ 90% ของความสามารถ Opus 4.8 ในงานส่วนใหญ่ โดยช่องว่างด้านประสิทธิภาพที่ใหญ่ที่สุดอยู่ที่การเขียนโค้ดแบบเอเจนต์ที่ซับซ้อน (SWE-bench Verified: 63.2% เทียบกับ 69.2%) การเปรียบเทียบนี้ครอบคลุมด้านราคา การทดสอบประสิทธิภาพ กรณีการใช้งาน และเมื่อใดที่แต่ละโมเดลจะคุ้มค่ากับราคาที่สูงขึ้น โดยอ้างอิงจากประกาศอย่างเป็นทางการของ Anthropic และการทดสอบในสภาพแวดล้อมการผลิตเป็นเวลาสองวัน.
Anthropic ได้กำหนดตำแหน่ง Sonnet 5 เป็น “Sonnet ที่มีคุณสมบัติการตัดสินใจอย่างอิสระมากที่สุดจนถึงปัจจุบัน” ซึ่งออกแบบมาเพื่อลดช่องว่างด้านราคาและประสิทธิภาพเมื่อเทียบกับ Opus โดยไม่ต้องให้ทีมต้องลดทอนความสามารถในการดำเนินการงานแบบอัตโนมัติ การว่า Sonnet 5 จะแทนที่ Opus 4.8 ในกระบวนการทำงานของคุณหรือไม่ ขึ้นอยู่กับสามปัจจัย ได้แก่ ระดับการสูญเสียความแม่นยำที่คุณสามารถรับได้ ปริมาณการประมวลผลที่คุณใช้ และว่างานของคุณจะให้ประโยชน์จากข้อได้เปรียบที่เหลืออยู่ของ Opus ในด้านการตัดสินใจที่ละเอียดอ่อนหรือไม่.
การนำทางอย่างรวดเร็ว
- ประเด็นสำคัญ
- ราคา: Sonnet 5 ถูกกว่าเท่าไร?
- ด้านการแสดง: จุดที่ Sonnet 5 ชนะ และจุดที่ Opus 4.8 ยังคงนำหน้า
- เมื่อใดควรใช้ Claude Sonnet 5
- เมื่อใดควรใช้ Claude Opus 4.8
- สามารถใช้ทั้งสองวิธีได้หรือไม่? วิธี “ระดับความพยายาม”
- การเปรียบเทียบคุณสมบัติในภาพรวม
- คำถามที่พบบ่อย
- สรุป: คุณควรเลือกอันไหน?
- แหล่งข้อมูลสำหรับบทความนี้
- ประวัติการแก้ไข
- เกี่ยวกับการเปรียบเทียบนี้
ประเด็นสำคัญ
- ความแตกต่างของราคา: Sonnet 5 มีอัตรา $2/$10 ต่อหนึ่งล้านโทเคน (โปรโมชั่นจนถึงวันที่ 31 สิงหาคม 2026) เทียบกับ Opus 4.8 ที่อัตรา $15/$75 — ลดค่าใช้จ่ายลง 7.5 เท่าเมื่อใช้ราคาโปรโมชั่น, 5 เท่าเมื่อใช้ราคาปกติ
- ประสิทธิภาพการเขียนโค้ด: Sonnet 5 ได้คะแนน 63.2% บน SWE-bench Verified เมื่อเทียบกับ Opus 4.8 ที่ได้ 69.2% — มีความแตกต่าง 6 จุดเปอร์เซ็นต์ ตามข้อมูลจาก System Card อย่างเป็นทางการของ Anthropic
- งานด้านความรู้: ตามผลการทดสอบภายในของ Anthropic Sonnet 5 มีประสิทธิภาพดีกว่า Opus 4.8 เล็กน้อยในบางการประเมินความรู้ด้านธุรกิจ
- บริบทและผลลัพธ์: ทั้งสองโมเดลรองรับบริบท 1 ล้านโทเคน และผลลัพธ์สูงสุด 128K โทเคน — ไม่มีความแตกต่างในจุดนี้
- เมื่อใดควรเลือกใช้ Sonnet 5: การเขียนโค้ดในชีวิตประจำวัน, ตัวแทนระบบ, การอัตโนมัติของเบราว์เซอร์และเทอร์มินัล, และกระบวนการทำงานใดๆ ที่คุณภาพระดับ 90% Opus ด้วยค่าใช้จ่ายเพียง 15% ถือเป็นที่ยอมรับได้
- เมื่อใดควรเลือกใช้ Opus 4.8: การวิเคราะห์ด้านกฎหมาย การแพทย์ และการเงิน ซึ่งความผิดพลาดเพียงเล็กน้อยในความแม่นยำก็อาจก่อให้เกิดผลตามมาอย่างรุนแรง; การวิจัยเชิงลึกบนชุดข้อมูลที่มีจำนวนโทเคนหลายล้าน
- ทางที่ง่ายที่สุด: ใช้ทั้งสอง — Sonnet 5 เป็นค่าเริ่มต้น และ Opus 4.8 สำหรับการเพิ่มระดับความซับซ้อน วิธีนี้โดยทั่วไปจะช่วยลดค่าใช้จ่ายในการคำนวณ AI รวมลงได้ 60–70%
ราคา: Sonnet 5 ถูกกว่าเท่าไร?
Claude Sonnet 5 มีราคาอยู่ที่ $2/$10 ต่อหนึ่งล้านโทเคนเข้า/ออก จนถึงวันที่ 31 สิงหาคม 2026 และจะเพิ่มขึ้นเป็น $3/$15 หลังจากนั้น Claude Opus 4.8 ยังคงอยู่ที่ $15/$75 ตลอดช่วงเวลาเดียวกัน นี่คือภาพรวมราคาทั้งหมด ณ เดือนกรกฎาคม 2026:
| แบบจำลอง | ข้อมูลเข้า (ต่อ Mtok) | ผลผลิต (ต่อ Mtok) | หน้าต่างบริบท |
|---|---|---|---|
| Claude Sonnet 5 (โปรโมชั่นจนถึงวันที่ 31 สิงหาคม 2026) | $2 | $10 | 1 ล้าน |
| Claude Sonnet 5 (มาตรฐานหลังวันที่ 31 สิงหาคม) | $3 | $15 | 1 ล้าน |
| โคลด ออปุส 4.8 | $15 | $75 | 1 ล้าน |
| Claude Sonnet 4.6 (ฉบับก่อน) | $3 | $15 | 1 ล้าน |
| GPT-5.5 (เพื่อเป็นข้อมูลอ้างอิง) | $10 | $30 | 400,000 |
| Gemini 3.1 Pro (เพื่ออ้างอิง) | $2.50 | $15 | 2 ล้าน |
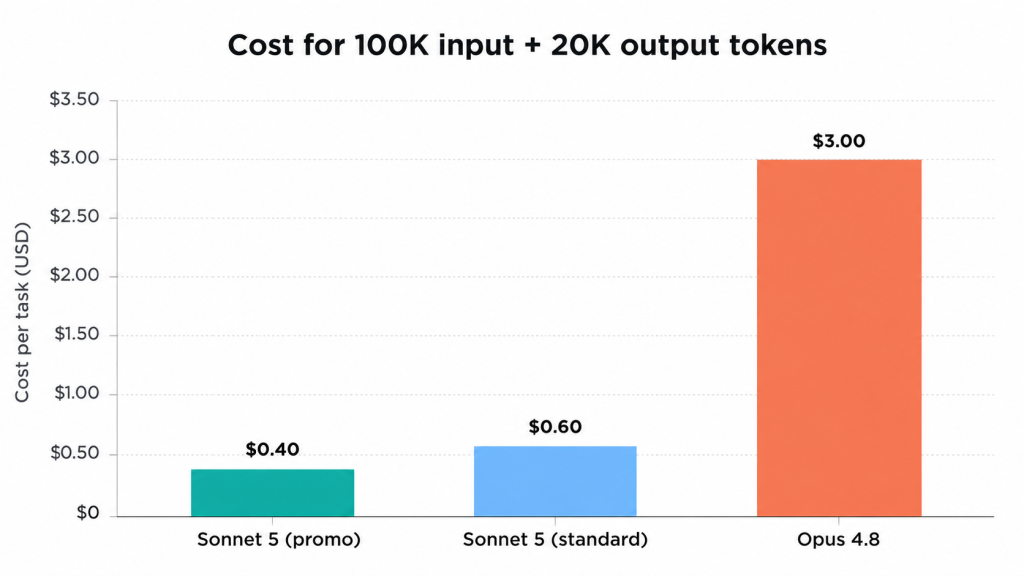
ด้วยราคาโปรโมชั่น Sonnet 5 มีราคา ค่าใช้จ่ายในการนำเข้าและส่งออกถูกกว่า 7.5 เท่า กว่า Opus 4.8 แม้จะคิดตามราคาปกติหลังช่วงโปรโมชั่น Sonnet 5 ก็ยังคง ถูกกว่า 5 เท่า. สำหรับปริมาณงานตัวอย่างที่มีโทเคนอินพุต 100K และโทเคนเอาต์พุต 20K ต่อแต่ละงาน:
- โซเน็ต 5 (เวอร์ชันโปรโมชัน): $0.20 (เข้า) + $0.20 (ออก) = $ 0.40 ต่องาน
- โซเน็ต 5 (ฉบับมาตรฐาน, หลังวันที่ 31 สิงหาคม): $0.30 (เข้า) + $0.30 (ออก) = $ 0.60 ต่องาน
- โอปัส 4.8: $1.50 (เข้า) + $1.50 (ออก) = $ 3.00 ต่องาน
ข้อมูลสำคัญ: ประหยัดได้ $2,400+ ต่อวัน
ทีมที่ดำเนินการ 1,000 งานต่อวันตามโปรไฟล์ปริมาณงานนี้ จะประหยัดได้ $2,400+ ต่อวัน เมื่อเปลี่ยนจาก Opus 4.8 มาใช้ Sonnet 5 — ซึ่งเพียงพอที่จะครอบคลุมงบประมาณการประมวลผลรายเดือนของวิศวกรหนึ่งคนภายในเวลาไม่ถึงหนึ่งสัปดาห์.
หมายเหตุเกี่ยวกับ Tokenizer (สำหรับผู้พัฒนาเท่านั้น): Sonnet 5 ใช้เครื่องมือแบ่งเป็นโทเคนแบบใหม่ ซึ่งสร้างโทเคนได้มากขึ้นประมาณ 30% สำหรับข้อความต้นทางเดียวกัน เมื่อเทียบกับ Sonnet 4.6. ซึ่งหมายความว่า การเปรียบเทียบค่าใช้จ่ายแบบโมเดลต่อโมเดลโดยตรงที่อิงตามการใช้งาน Sonnet 4.6 ต้องปรับเพิ่มประมาณ ~30% ก่อนที่จะนำราคาต่อโทเคนของ Sonnet 5 มาใช้ เอกสารทางการของ Anthropic ยืนยันการเปลี่ยนแปลงตัวแบ่งโทเคนนี้; เราได้ตรวจสอบความถูกต้องกับชุดข้อมูลทดสอบของเราเองในช่วงสองวันหลังจากการปล่อย Sonnet 5.
ด้านการแสดง: จุดที่ Sonnet 5 ชนะ และจุดที่ Opus 4.8 ยังคงนำหน้า
Claude Sonnet 5 บรรลุผล 63.2% บน SWE-bench Verified — มาตรฐานการวัดประสิทธิภาพการเขียนโค้ดแบบเอเจนต์หลักของ Anthropic — เมื่อเทียบกับ 69.2% ของ Claude Opus 4.8 ซึ่งมีความแตกต่าง 6 จุดเปอร์เซ็นต์ ในเกณฑ์วัดผลด้านงานความรู้และการให้เหตุผลทั่วไป ช่องว่างนี้แคบลงหรือกลับกัน ข้อมูลเต็มจาก Anthropic’s ประกาศอย่างเป็นทางการเกี่ยวกับ Sonnet 5 (30 มิถุนายน 2026):
| เกณฑ์มาตรฐาน | โซเน็ต 5 | โอปัส 4.8 | ช่องว่าง |
|---|---|---|---|
| ได้รับการตรวจสอบโดย SWE-bench (การเขียนโค้ดแบบเอเจนต์) | 63.20% | 69.20% | Opus +6.0 |
| GPQA Diamond (การวิเคราะห์) | ประมาณ 70 องศา* | ประมาณ 70 องศา* | ~เสมอ |
| MMLU (ความรู้ทั่วไป) | ~89% | ~92% | Opus +3 |
| งานด้านความรู้ (งานธุรกิจ) | สูงขึ้นเล็กน้อย | ค่าพื้นฐาน | โซเน็ตชนะ |
| การใช้เครื่องมือ (เบราว์เซอร์/เทอร์มินัล) | ปิด | ผู้นำ | Opus edge |
| งานที่มีบริบทยาว (1 ล้านโทเคน) | หนา | หนา | ~เสมอ |
| ความสามารถด้านความปลอดภัยทางไซเบอร์ | จำกัด | แข็งแกร่งขึ้น | Opus (ตามการออกแบบ) |
จุดที่ Sonnet 5 เทียบเท่าหรือเหนือกว่า Opus 4.8
- งานด้านความรู้และการวิเคราะห์ธุรกิจ — Anthropic รายงานว่า Sonnet 5 มีคะแนนนำเล็กน้อยในบางการประเมินทางธุรกิจ
- งานเขียนโค้ดประจำวัน — 63.2% บน SWE-bench Verified พร้อมใช้งานในระบบผลิตจริงสำหรับงานพัฒนาฟีเจอร์และแก้ไขข้อผิดพลาดส่วนใหญ่
- งานหลายขั้นตอนแบบอัตโนมัติ — พันธมิตรเปิดตัวของ Anthropic รายงานว่า Sonnet 5 ได้เสร็จสิ้นงานที่เวอร์ชันก่อนหน้าทิ้งไว้กลางทาง
- การวิเคราะห์บริบทยาวได้ถึง 1 ล้านโทเคน — เทียบเท่า Opus 4.8 ในการทดสอบภายในของ Anthropic
ที่ Opus 4.8 ยังคงเป็นผู้นำ
- งานตัดสินใจที่ซับซ้อน ซึ่งต้องการการวิเคราะห์การแลกเปลี่ยนผลประโยชน์อย่างละเอียด
- การวิจัยเชิงลึกในบริบทขนาดใหญ่ (ชุดเอกสารที่มีโทเคนมากกว่า 10 ล้านโทเคน ครอบคลุมหลายเซสชัน)
- ปัญหาทางเทคนิคที่ยังไม่เคยมีมาก่อน โดยไม่มีงานวิจัยหรือวิธีแก้ปัญหาที่ชัดเจนเป็นตัวอย่างอ้างอิง
- ความปลอดภัยทางไซเบอร์และการวิเคราะห์เชิงป้องกัน — Opus 4.8 ยังคงรักษาความสามารถที่แข็งแกร่งขึ้นตามการออกแบบที่ Anthropic ได้ระบุไว้
คำอธิบายที่ Anthropic ใช้เพื่ออธิบาย Sonnet 5 คือ “ความฉลาดที่ใกล้เคียงกับ Opus แต่ในราคาของ Sonnet” สำหรับเวิร์กโฟลว์การผลิตแบบ 90% การทดสอบของเราในช่วงสองวันหลังการเปิดตัวยืนยันว่า — ช่องว่างในการให้คะแนน 6 จุดจะสังเกตเห็นได้ชัดเจนเฉพาะในงานที่ยากที่สุดเท่านั้น และช่องว่างด้านราคาอยู่ที่ 5–7 เท่า สำหรับการผลิตในปริมาณมาก การคำนวณทางคณิตศาสตร์ชี้ให้เห็นว่า Sonnet 5 เป็นตัวเลือกที่คุ้มค่ากว่า.
เมื่อใดควรใช้ Claude Sonnet 5
Claude Sonnet 5 เป็นตัวเลือกโมเดลที่เหมาะสมที่สุด เมื่อภาระงานของคุณให้ความสำคัญกับปริมาณการประมวลผล (throughput) ความคุ้มค่าด้านต้นทุน หรือการทำงานแบบอัตโนมัติ มากกว่าความแม่นยำดิบในช่วง 5–10% สุดท้าย นี่คือสามรูปแบบการทำงานที่ Sonnet 5 มักได้รับการเลือกเป็นค่าเริ่มต้นเสมอ:
การเขียนโค้ดและวิศวกรรมซอฟต์แวร์
- การพัฒนาคุณสมบัติหลายขั้นตอน ตั้งแต่ข้อกำหนดจนถึงการรวม PR
- การแก้ไขข้อผิดพลาดในฐานรหัสที่ยุ่งเหยิง รหัสเก่า หรือรหัสที่พัฒนาต่อจากระบบเดิม
- การสร้างคำขอ pull request การตรวจสอบ และการปรับปรุงแบบอัตโนมัติ
- การปรับโครงสร้างโค้ดในรีโพสิตอรีขนาดใหญ่ที่มีความสัมพันธ์ระหว่างไฟล์
- การเขียนการทดสอบ การตรวจสอบ และการตรวจสอบผลลัพธ์ด้วยตนเอง
ผลการทดสอบภายในของ Anthropic แสดงให้เห็นว่า Sonnet 5 สามารถจัดการคำขอ pull request ได้อย่างครบถ้วนตั้งแต่ต้นจนจบ — รวมถึงการเขียนการทดสอบเพื่อจำลองปัญหา ก่อนการแก้ไข และการตรวจสอบผลลัพธ์ด้วยตนเองก่อนส่ง ซึ่งนี่ไม่ใช่ความสามารถที่ Sonnet 4.6 เวอร์ชันก่อนหน้าแสดงให้เห็นได้อย่างน่าเชื่อถือ นั่นจึงเป็นเหตุผลที่การเปลี่ยนทิศทางไปสู่การเน้นการเขียนโค้ด ถือเป็นการปรับปรุงที่ได้รับการกล่าวถึงมากที่สุดในรายงานการเปิดตัว.
กระบวนการทำงานเชิงตัวแทน
- การอัตโนมัติของเบราว์เซอร์ (การกรอกแบบฟอร์ม การสกัดข้อมูล กระบวนการทำงานในระบบอีคอมเมิร์ซ)
- การดำเนินการคำสั่งในเทอร์มินัลและการอัตโนมัติงานบนระบบเชลล์
- กระบวนการทำงานทางธุรกิจหลายขั้นตอน (อัปเดต CRM, ส่งอีเมล, บันทึกข้อมูลลงในสเปรดชีตในขั้นตอนเดียว)
- งานที่ใช้เวลานานและต้องการความตั้งใจอย่างต่อเนื่องตลอดการเรียกใช้เครื่องมือหลายครั้ง
Zapier รายงานว่าได้ใช้ Sonnet 5 เพื่ออัปเดตระดับบัญชี Salesforce และส่งประกาศเปิดตัวแบบครบวงจร — ซึ่งเป็นกระบวนการทำงานที่หยุดชะงักกลางทางเมื่อใช้เวอร์ชัน Sonnet ก่อนหน้า สิ่งนี้สอดคล้องกับสิ่งที่เราสังเกตได้เอง: ความคงทนของ Sonnet 5 ในวงจรการใช้งานเครื่องมือได้รับการปรับปรุงอย่างมีนัยสำคัญ.
ระบบอัตโนมัติปริมาณสูง
- การจัดลำดับความสำคัญของคำร้องจากลูกค้าและการร่างคำตอบเบื้องต้น
- การควบคุมเนื้อหาในขนาดใหญ่ รวมถึงการนำนโยบายไปใช้อย่างละเอียดอ่อน
- การวิเคราะห์บันทึกและตรวจหาความผิดปกติในกระแสเหตุการณ์ขนาดใหญ่
- กระบวนการทำงานใดก็ตามที่ให้คุณภาพ 90% ของ Opus 4.8 ด้วยค่าใช้จ่าย 15% ถือเป็นความสมดุลที่สมเหตุสมผล
เมื่อใดควรใช้ Claude Opus 4.8
Claude Opus 4.8 ยังคงเป็นตัวเลือกโมเดลที่เหมาะสมที่สุด เมื่อค่าใช้จ่ายจากข้อผิดพลาดด้านความแม่นยำสูงกว่าค่าใช้จ่ายจากการคำนวณเพิ่มเติม นี่คือสถานการณ์เฉพาะที่ข้อได้เปรียบ 6 จุดของ Opus 4.8 ในงานที่ซับซ้อนจะแปลงเป็นมูลค่าทางธุรกิจที่แท้จริง:
งานที่ต้องการความแม่นยำสูง
- การวิเคราะห์เอกสารทางกฎหมาย ซึ่งการพลาดข้อกำหนดเพียงข้อเดียวก็อาจก่อให้เกิดผลตามมาอย่างรุนแรง
- การทบทวนวรรณกรรมทางการแพทย์ที่ต้องการการตีความเฉพาะด้าน
- การสร้างแบบจำลองทางการเงินที่มีผลกระทบต่อกฎระเบียบหรือการปฏิบัติตามข้อกำหนด
- การสังเคราะห์ผลการวิจัยเพื่อเผยแพร่ในสื่อวิชาการหรือเพื่ออ้างอิง
คำพิพากษาที่ซับซ้อน
- การตัดสินใจทางธุรกิจเชิงกลยุทธ์ที่มีหลายปัจจัยที่ต้องชั่งน้ำหนักและเลือกอย่างแข่งขันกัน
- ปัญหาทางเทคนิคที่ยังไม่เคยมีมาก่อน และไม่มีวิธีแก้ปัญหาที่ได้รับการยอมรับอย่างเป็นทางการ
- การสื่อสารระหว่างผู้มีส่วนได้ส่วนเสียหลายฝ่าย ซึ่งต้องการความละเอียดอ่อนทางทางการทูต
การวิจัยเชิงลึก
- การวิเคราะห์ชุดเอกสารที่มีจำนวนโทเคนหลายล้านชิ้นในหลายเซสชัน
- การอ้างอิงข้ามกันระหว่างฐานความรู้ขนาดใหญ่
- การวิเคราะห์เปรียบเทียบอย่างละเอียดถี่ถ้วน ที่ไม่มีสิ่งใดถูกมองข้าม
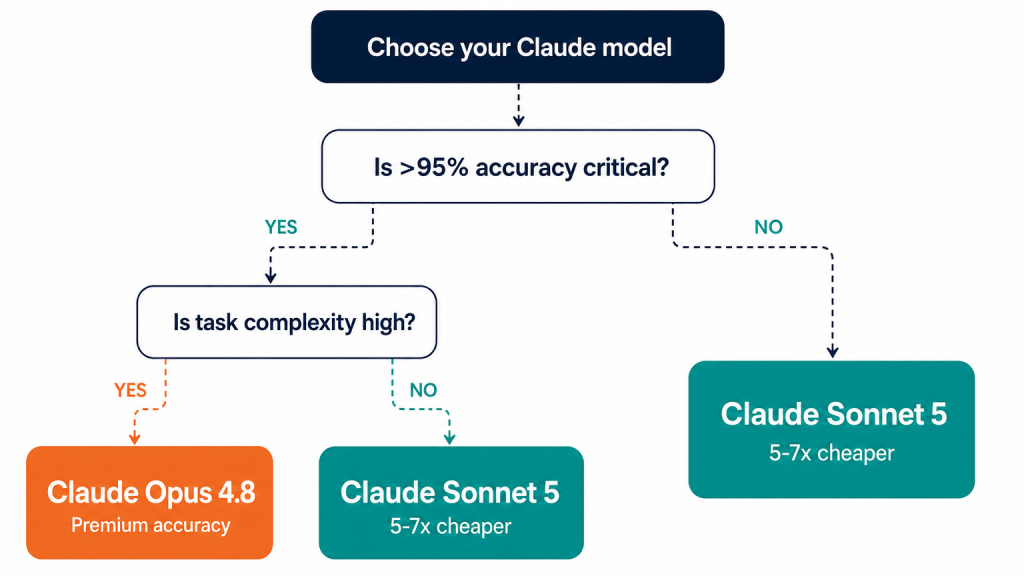
หลักทั่วไป: หากงานของคุณสามารถยอมรับการลดความแม่นยำลง 6 จุดเปอร์เซ็นต์ เพื่อแลกกับการลดค่าใช้จ่ายลง 5–7 เท่า ให้ใช้ Sonnet 5 แต่หากข้อผิดพลาดด้านความแม่นยำเพียงครั้งเดียวจะทำให้ค่าใช้จ่ายเพิ่มขึ้นมากกว่าการประหยัดค่าใช้จ่ายจากการคำนวณ ให้ใช้ Opus 4.8.
สามารถใช้ทั้งสองวิธีได้หรือไม่? วิธี “ระดับความพยายาม”
Anthropic ได้ออกแบบ Sonnet 5 และ Opus 4.8 ให้ทำงานร่วมกันอย่างชัดเจน ไม่ใช่เพื่อเป็นตัวเลือกที่ต้องเลือกอย่างใดอย่างหนึ่ง เอกสารของพวกเขากำหนดการตัดสินใจนี้ว่าเป็นเรื่อง “ระดับความพยายาม” — Sonnet 5 เป็นตัวเลือกมาตรฐาน ส่วน Opus 4.8 เป็นตัวเลือกขั้นสูงสำหรับงานที่มีความเสี่ยงสูง รูปแบบการจัดระดับนี้ปัจจุบันเป็นสถาปัตยกรรมการผลิตที่แนะนำสำหรับทีมที่พัฒนาบน Claude API.
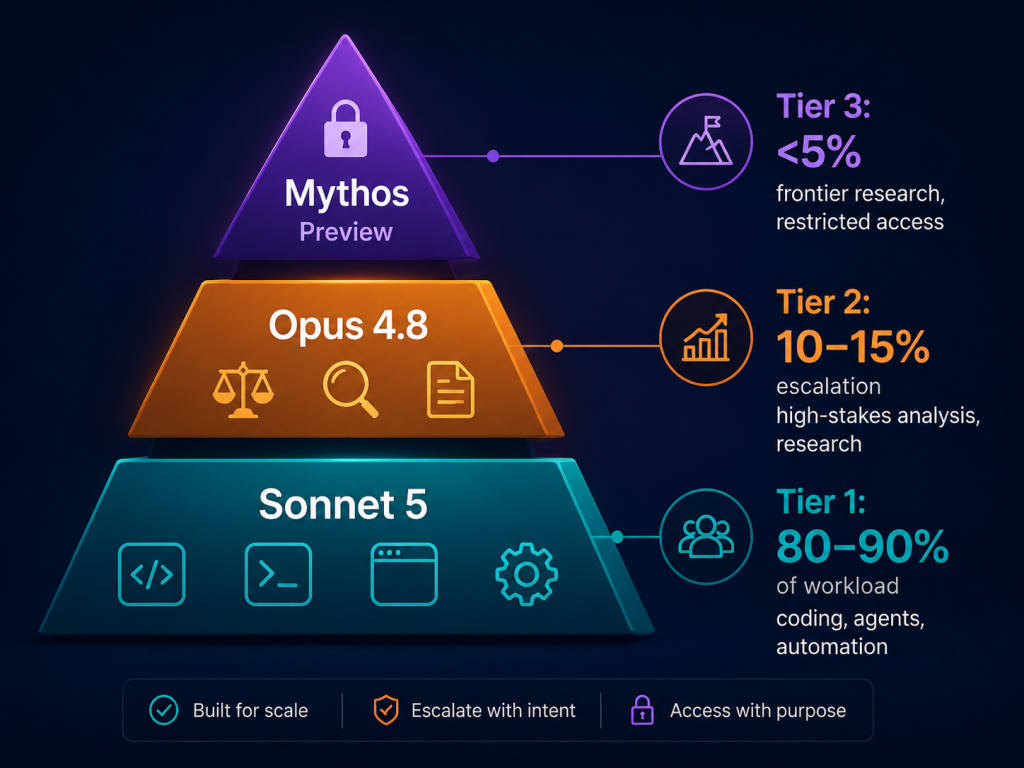
ระดับ 1 (ค่าเริ่มต้น): Sonnet 5
ใช้สำหรับ 80–90% ของงานของคุณ — การเขียนโค้ด, ตัวแทน, งานด้านความรู้ส่วนใหญ่, และการอัตโนมัติที่มีปริมาณสูง นี่คือจุดเริ่มต้นตามค่าเริ่มต้นสำหรับงานใหม่ทุกงาน เว้นแต่จะมีเหตุผลที่ชัดเจนที่จะยกระดับงาน.
ระดับ 2 (การส่งต่อ): Opus 4.8
จะทำงานเฉพาะเมื่อ Sonnet 5 ถึงระดับความมั่นใจที่คุณกำหนดไว้เท่านั้น ตัวอย่างการทริกเกอร์การยกระดับที่พบบ่อย:
- ผลลัพธ์ทางกฎหมาย การแพทย์ หรือการเงินที่แสดงให้ผู้ใช้เห็น
- การตัดสินใจด้านการเงินหรือด้านกฎระเบียบที่มีมูลค่าเกินระดับที่กำหนด
- งานที่ระบบตรวจสอบอัตโนมัติของ Sonnet 5 ชี้ให้เห็นถึงความไม่แน่นอนในผลลัพธ์
- การสื่อสารระหว่างผู้มีส่วนได้ส่วนเสียหลายฝ่ายที่มีความเสี่ยงต่อชื่อเสียงสูง
ระดับ 3 (การวิจัยแนวหน้า): Claude Mythos Preview
เฉพาะสำหรับกลุ่มองค์กรที่ได้รับการเชื่อถือจำนวนน้อยเท่านั้น ผ่านทาง โครงการ Glasswing ของ Anthropic — จัดไว้สำหรับงานวิจัยแนวหน้า ซึ่งจำเป็นต้องใช้ความสามารถที่เกี่ยวข้องกับความปลอดภัยทางไซเบอร์.
ข้อมูลสำคัญ: ลดค่าใช้จ่ายในการประมวลผลรวมลง 60–70%
ทีมที่นำวิธีการแบบหลายชั้นนี้มาใช้ มักจะลดค่าใช้จ่ายในการประมวลผล AI รวมลงได้ 60–70% เมื่อเทียบกับการส่งคำขอทุกครั้งไปยัง Opus 4.8 โดยยังคงรักษาความแม่นยำในภารกิจเฉพาะที่ต้องการความแม่นยำนั้น.
สำหรับทีมที่ต้องการเข้าถึง Sonnet 5, Opus 4.8, GPT-5.5, Gemini 3.1 Pro และโมเดล AI อีกกว่า 100 แบบ ภายใต้การสมัครสมาชิกเดียว โดยไม่ต้องจัดการกับกุญแจ API และบัญชีการชำระเงินหลายบัญชี แพลตฟอร์มแบบหลายโมเดล เช่น โกลบอลจีพีที เสนอการเข้าถึงแบบรวมเริ่มต้นที่ $5.8/เดือน ซึ่งมักมีราคาถูกกว่าการใช้เงินงบประมาณ API ของ Anthropic เพียงอย่างเดียวสำหรับปริมาณงานที่เท่ากัน.
การเปรียบเทียบคุณสมบัติในภาพรวม
การเปรียบเทียบทางเทคนิคอย่างละเอียดระหว่าง Claude Sonnet 5 และ Claude Opus 4.8 โดยอ้างอิงจาก System Card และเอกสาร API อย่างเป็นทางการของ Anthropic ณ วันที่ 3 กรกฎาคม 2026:
| คุณสมบัติ | โคลด โซเน็ต 5 | โคลด ออปุส 4.8 |
|---|---|---|
| วันวางจำหน่าย | 30 มิถุนายน 2569 | พฤษภาคม 2026 |
| ราคาป้อนเข้า (ต่อ Mtok) | โปรโมชั่น $2 / รุ่นมาตรฐาน $3 | $15 |
| ราคาขาย (ต่อ Mtok) | โปรโมชั่น $10 / มาตรฐาน $15 | $75 |
| หน้าต่างบริบท | 1 ล้านโทเค็น | 1 ล้านโทเค็น |
| กำลังสูงสุด | โทเค็น 128K | โทเค็น 128K |
| การคิดเชิงปรับตัว | เปิดตามค่าเริ่มต้น | เปิดตามค่าเริ่มต้น |
| การคิดเชิงลึกแบบทำด้วยมือ | ถูกลบ (แสดงข้อผิดพลาด 400) | ถูกลบ (แสดงข้อผิดพลาด 400) |
| ความรู้ที่สิ้นสุด | มกราคม 2026 | มกราคม 2026 |
| มาตรการป้องกันด้านความปลอดภัยไซเบอร์ | แบบเรียลไทม์ (ระดับ Sonnet เป็นอันดับแรก) | มาตรฐาน |
| เกณฑ์วัดประสิทธิภาพการเขียนโค้ด (SWE-bench) | 63.20% | 69.20% |
| เหมาะที่สุดสำหรับ | ปริมาณ, ตัวแทน, ความคุ้มค่า | การวิเคราะห์ที่ซับซ้อน การวิจัยอย่างลึกซึ้ง |
| ค่าเริ่มต้นใน Claude.ai | แพ็กเกจฟรีและแพ็กเกจโปร | Max, Team, Enterprise |
| รหัสโมเดล API | claude-sonnet-5 | โคลด-opus-4-8 |
| เครื่องมือแบ่งคำใหม่ | ใช่ (มีโทเคนมากกว่า (~30%) เมื่อเทียบกับ 4.6) | ไม่มีการเปลี่ยนแปลงจากเวอร์ชัน 4.7 |
ทั้งสองโมเดลมีอินเทอร์เฟซ API ที่เหมือนกัน โค้ดที่เขียนสำหรับ Sonnet 4.6 หรือ Opus 4.7 สามารถทำงานได้บน Sonnet 5 และ Opus 4.8 โดยเพียงแค่เปลี่ยน ID ของโมเดลเท่านั้น แต่มีสามข้อยกเว้นสำคัญบน Sonnet 5:
- การตั้งค่าพารามิเตอร์การคิดแบบขยายด้วยตนเองจะแสดงข้อผิดพลาด 400 — ให้ใช้การคิดแบบปรับตัวตามค่าเริ่มต้นแทน
- พารามิเตอร์การสุ่มตัวอย่างที่ไม่ใช้ค่าเริ่มต้น (temperature, top_p, top_k) ให้ข้อผิดพลาด 400 — Sonnet 5 ต้องการการสุ่มตัวอย่างตามค่าเริ่มต้น
- ตัวแบ่งคำแบบใหม่ทำให้จำนวนโทเคน (และด้วยเหตุนี้ ค่าใช้จ่ายต่อคำขอ) แตกต่างไปสำหรับข้อความที่เหมือนกัน เมื่อเทียบกับ Sonnet 4.6
ผู้พัฒนาที่กำลังย้ายจาก Sonnet 4.6 ควรดำเนินการคำนวณจำนวนโทเคนใหม่บนตัวอย่างงานที่เป็นตัวแทน ก่อนที่จะกำหนดการคาดการณ์งบประมาณรายเดือน.

คำถามที่พบบ่อย
Claude Sonnet 5 ดีเท่ากับ Opus 4.8 หรือไม่?
สำหรับงานส่วนใหญ่ Claude Sonnet 5 ให้ประสิทธิภาพประมาณ 90% เมื่อเทียบกับ Claude Opus 4.8 ตาม System Card อย่างเป็นทางการของ Anthropic Sonnet 5 ได้คะแนน 63.2% ใน SWE-bench Verified ในขณะที่ Opus 4.8 ได้คะแนน 69.2% ซึ่งมีความแตกต่าง 6 จุดเปอร์เซ็นต์ Sonnet 5 มีประสิทธิภาพดีกว่า Opus 4.8 เล็กน้อยในการประเมินงานด้านความรู้ทางธุรกิจบางประเภท สำหรับงานที่ต้องการความแม่นยำสูงสุด Opus 4.8 ยังคงเป็นผู้นำ ส่วนงานที่เหลืออีก 90% การประหยัดค่าใช้จ่าย 5–7 เท่าของ Sonnet 5 มีน้ำหนักมากกว่าการสูญเสียความแม่นยำ.
Sonnet 5 ถูกกว่า Opus 4.8 เท่าไหร่?
Claude Sonnet 5 มีค่าใช้จ่าย $2 ต่อหนึ่งล้านโทเคนอินพุต และ $10 ต่อหนึ่งล้านโทเคนเอาต์พุต จนถึงวันที่ 31 สิงหาคม 2026 (ราคาโปรโมชั่น) หลังจากนั้นจะเป็น $3/$15 Claude Opus 4.8 มีค่าใช้จ่าย $15 สำหรับโทเคนเข้า และ $75 สำหรับโทเคนออก ซึ่งทำให้ Sonnet 5 ถูกกว่า 7.5 เท่า ทั้งด้านโทเคนเข้าและโทเคนออกในราคาโปรโมชั่น และถูกกว่า 5 เท่าในราคาปกติหลังเดือนสิงหาคม สำหรับงานที่ใช้โทเคนอินพุต 100K และโทเคนเอาต์พุต 20K Sonnet 5 มีค่าใช้จ่าย $0.40 เทียบกับ $3.00 ของ Opus 4.8 — ประหยัดได้ $2.60 ต่องาน.
สำหรับงานเขียนโค้ดแล้ว Sonnet 5 หรือ Opus 4.8 ดีกว่ากัน?
Claude Opus 4.8 ได้คะแนน 69.2% บน SWE-bench Verified (เกณฑ์วัดประสิทธิภาพการเขียนโค้ดแบบเอเจนต์หลักของ Anthropic) ส่วน Claude Sonnet 5 ได้คะแนน 63.2% สำหรับงานเขียนโค้ดส่วนใหญ่ — การนำฟีเจอร์มาใช้ การดีบัก การรีแฟคเตอร์ และการสร้าง PR — Sonnet 5 พร้อมใช้งานในสภาพแวดล้อมจริงและมีค่าใช้จ่ายถูกกว่า 5–7 เท่า ส่วน Opus 4.8 ยังคงมีประโยชน์สำหรับปัญหาที่ท้าทายที่สุด: สถาปัตยกรรมแบบใหม่ โค้ดบราวน์ฟิลด์ที่มีเงื่อนไขการแข่งขันที่ซ่อนอยู่ หรือเส้นทางโค้ดที่มีความสำคัญต่อความปลอดภัย Cursor, ทีมของ Anthropic เอง และ Zapier ต่างรายงานว่าใช้ Sonnet 5 เป็นโมเดลการเขียนโค้ดเริ่มต้นในสภาพแวดล้อมการผลิต.
ผมสามารถใช้ Sonnet 5 และ Opus 4.8 พร้อมกันได้ไหมครับ?
ใช่ และ Anthropic แนะนำอย่างชัดเจนให้ทำเช่นนี้ ให้ใช้ Claude Sonnet 5 เป็นค่าเริ่มต้นสำหรับงานที่มีระดับความซับซ้อน 80–90% แล้วเปลี่ยนไปใช้ Claude Opus 4.8 สำหรับการตัดสินใจที่มีความเสี่ยงสูงหรืองานที่ระบบตรวจสอบตัวเองของ Sonnet 5 ชี้ให้เห็นถึงความไม่แน่นอน วิธีการแบ่งระดับนี้มักช่วยลดค่าใช้จ่ายในการประมวลผลรวมลงได้ 60–70% เมื่อเทียบกับการส่งคำขอทุกครั้งไปยัง Opus 4.8 แพลตฟอร์มหลายโมเดล เช่น โกลบอลจีพีที ให้คุณสามารถเข้าถึงทั้งสองโมเดลได้ภายใต้การสมัครสมาชิกเดียว โดยไม่ต้องจัดการกับกุญแจ API หลายชุด.
เมื่อใดควรใช้ Opus 4.8 แทน Sonnet 5?
ใช้ Claude Opus 4.8 สำหรับ: การวิเคราะห์เอกสารทางกฎหมาย ซึ่งการพลาดข้อกำหนดเพียงข้อเดียวก็อาจก่อให้เกิดผลตามมาอย่างรุนแรง; การทบทวนวรรณกรรมทางการแพทย์ที่ต้องการความเชี่ยวชาญในสาขาเฉพาะ; การสร้างแบบจำลองทางการเงินที่มีผลกระทบต่อกฎระเบียบ; การตัดสินใจเชิงกลยุทธ์ที่มีหลายทางเลือกที่ขัดแย้งกัน; การวิจัยเชิงลึกในชุดเอกสารที่มีหลายล้านโทเคน; และการวิเคราะห์ความปลอดภัยทางไซเบอร์ ซึ่ง Opus 4.8 ยังคงมีความสามารถที่แข็งแกร่งกว่าตามการออกแบบของ Anthropic สำหรับงานอื่นๆ ทั้งหมด Sonnet 5 มีประสิทธิภาพด้านต้นทุนที่ดีกว่า.
Sonnet 5 ใช้ได้ฟรีหรือไม่?
Claude Sonnet 5 เป็นโมเดลมาตรฐานในแพ็กเกจ Free และ Pro ของ Claude.ai โดยมีข้อจำกัดในการใช้งาน ผู้ใช้แพ็กเกจ Free มีจำนวนข้อความต่อวันที่จำกัด ส่วนแพ็กเกจ Pro ($20/เดือน) ให้ข้อจำกัดที่สูงขึ้นอย่างมีนัยสำคัญ ผ่าน API Sonnet 5 ไม่ฟรี แต่มีราคาถูกกว่า Opus 4.8 อย่างมีนัยสำคัญ — $2/$10 ต่อหนึ่งล้านโทเคน ตามราคาโปรโมชั่น แพลตฟอร์มแบบหลายโมเดล เช่น โกลบอลจีพีที รวมการเข้าถึง API ของ Sonnet 5 กับโมเดลอื่นๆ กว่า 100 แบบ เริ่มต้นที่ $5.8 ต่อเดือน.
สรุป: คุณควรเลือกอันไหน?
เลือก Claude Sonnet 5 หาก: ไม่ว่าคุณกำลังพัฒนาแอปพลิเคชันสำหรับการผลิต, ดำเนินการเอเจนต์ในขนาดใหญ่, ทำงานเขียนโค้ดในปริมาณมาก หรือปรับให้เหมาะสมกับค่าใช้จ่าย Sonnet 5 ให้ประสิทธิภาพเทียบเท่า 90%+ ของ Opus 4.8 ด้วยค่าใช้จ่ายที่ต่ำกว่า 5–7 เท่า สำหรับงานส่วนใหญ่.
เลือก Claude Opus 4.8 หาก: หากงานของคุณมีข้อกำหนดด้านความแม่นยำที่สูงมาก ต้องใช้การตัดสินใจที่ซับซ้อน หรือต้องแก้ไขปัญหาที่ไม่เคยเกิดขึ้นมาก่อน หรือหากการเพิ่มขึ้น 6 เปอร์เซ็นต์ในผลการทดสอบมาตรฐานสามารถสร้างมูลค่าทางธุรกิจที่แท้จริง ซึ่งทำให้ราคาที่สูงขึ้นนั้นคุ้มค่า งานด้านกฎหมาย การแพทย์ การเงินที่มีความเสี่ยงสูง และงานวิจัย ยังคงใช้ Opus 4.8 ต่อไป.
เลือกทั้งสองตัวเลือกหาก: คุณจริงจังกับ AI สำหรับการผลิต ใช้ Sonnet 5 เป็นค่าเริ่มต้น และเปลี่ยนไปใช้ Opus 4.8 สำหรับงานที่ต้องการประสิทธิภาพสูงยิ่งขึ้น แพลตฟอร์มแบบหลายโมเดล เช่น โกลบอลจีพีที ให้คุณเข้าถึง Sonnet 5, Opus 4.8, GPT-5.5, Gemini 3.1 Pro และโมเดล AI อีกกว่า 100 แบบ ภายใต้การสมัครสมาชิกเดียว เริ่มต้นที่ $5.8 ต่อเดือน — ซึ่งมักมีราคาถูกกว่างบประมาณ API ของ Anthropic สำหรับปริมาณการใช้งานเท่ากัน และไม่ต้องเสียเวลาในการจัดการกุญแจ API หลายชุด.
โมเดล AI ที่เหมาะสมที่สุดสำหรับคุณคือโมเดลที่สอดคล้องกับความสมดุลระหว่างความแม่นยำ ค่าใช้จ่าย และความเร็วในกระบวนการทำงานของคุณ ให้เข้าใจถึงจุดที่ต้องแลกเปลี่ยนกัน แล้วจึงเลือกให้เหมาะสม.
แหล่งข้อมูลสำหรับบทความนี้
- ประกาศอย่างเป็นทางการจาก Anthropic เกี่ยวกับ Claude Sonnet 5 (30 มิถุนายน 2026): anthropic.com/news/claude-sonnet-5
- บัตรระบบ Claude Sonnet 5 (ศูนย์ความโปร่งใสทางมานุษยวิทยา)
- เอกสารของ Claude Platform: มีอะไรใหม่ใน Claude Sonnet 5
- ข่าวจาก TechCrunch: “Anthropic เปิดตัว Claude Sonnet 5 เพื่อเป็นทางเลือกที่ประหยัดกว่าในการใช้งานเอเจนต์” (30 มิถุนายน 2026)
- Search Engine Journal: “Claude Sonnet 5 ของ Anthropic คือระบบปัญญาประดิษฐ์ระดับใกล้กับระดับโอปุส สำหรับทุกแผนงาน”
- การเปรียบเทียบประสิทธิภาพแบบอิสระจากกระบวนการบูรณาการการเปิดตัว Sonnet 5 ของ Cursor และการประเมินการเขียนโค้ดของ BigGo Finance
- ผลการทดสอบของเราเองระหว่าง Sonnet 5 และ Opus 4.8 บนตัวอย่างคำสั่งที่สะท้อนงานเขียนโค้ดและงานด้านความรู้อย่างเหมาะสม ระหว่างวันที่ 1–3 กรกฎาคม 2026
ประวัติการแก้ไข
3 กรกฎาคม 2569 — บทความฉบับแรกที่เขียนขึ้นโดยอ้างอิงจากงานเปิดตัวของ Anthropic เมื่อวันที่ 30 มิถุนายน และการทดสอบใช้งานจริงเป็นเวลาสองวัน.
เกี่ยวกับการเปรียบเทียบนี้
เขียนโดยทีม GlobalGPT Sonnet 5 ได้เปิดให้บริการบนแพลตฟอร์มของเราตั้งแต่วันที่ 30 มิถุนายนเป็นต้นมา ในช่วงสองวันที่ผ่านมา เราได้ทำการเปรียบเทียบประสิทธิภาพของมันกับ Opus 4.8 โดยตรง ผ่านงานจริง — ซึ่งเป็นประเภทงานที่ผู้ใช้ของเราดำเนินการทุกวัน.
ข้อมูลเปรียบเทียบเป็นของ Anthropic ส่วนการสังเกตและคำนวณค่าใช้จ่ายเป็นของเรา.
ตรวจสอบครั้งสุดท้าย: 3 กรกฎาคม 2026 เราจะอัปเดตบทความนี้เมื่อได้ทดสอบ Sonnet 5 ในกรณีการใช้งานเพิ่มเติมในช่วงสัปดาห์ต่อๆ ไป.