What Is New in Claude Opus 4.7? Features, Changes, and More


Claude Opus 4.7 (released April 16, 2026) marks a shift from chat-centric AI to an execution-driven system optimized for long-context agentic coding and 3.75MP high-resolution vision. While its new xhigh effort level and task budgets solve complex reasoning gaps, professional users are struggling with a 1.35x cost increase due to the new tokenizer and API breaking changes that make upgrading from 4.6 a technical headache.
These hidden costs and the recent service instability in mid-April hinder enterprise reliability. GlobalGPT bridges this gap by offering immediate, stable access to Claude Opus 4.7, Claude Sonnet 4.6, Gemini 3.1 and GPT-5.4. You can bypass the complex $20/month subscription and region blocks for just $5.8 on our Basic Plan, ensuring your agentic workflows remain cost-effective and uninterrupted.
Beyond engineering logic, GlobalGPT powers your full-cycle workflow by integrating the world's elite creative models. Once Claude Opus 4.7 finalizes your project architecture, you can trigger Sora 2 or Veo 3.1 for video production and Nano Banana 2 or Flux for high-fidelity visuals. Complete your entire professional roadmap—from Self-Verifying AI research to final media output—inside one unified dashboard.
Introduction: The Evolution of Claude Opus 4.7 into an Execution Engine
Defining the 2026 Frontier Standard
Released on April 16, 2026, Claude Opus 4.7 (API ID: claude-opus-4-7) represents Anthropic’s most significant leap toward autonomous intelligence. While previous versions were primarily seen as conversational partners, Opus 4.7 is engineered as an execution-driven system. It is designed to inhabit complex software environments, manage long-running agentic loops, and perform high-stakes professional work with a level of reliability that minimizes the need for constant human oversight.
This model occupies the top tier of the Claude 4 family, sitting just below the limited-access Mythos Preview. For the general market, Opus 4.7 is the reigning champion of agentic coding and logical consistency, effectively solving the "reasoning fatigue" often seen in older models during multi-hour sessions.
Overview of Breakthrough Capabilities in 4.7
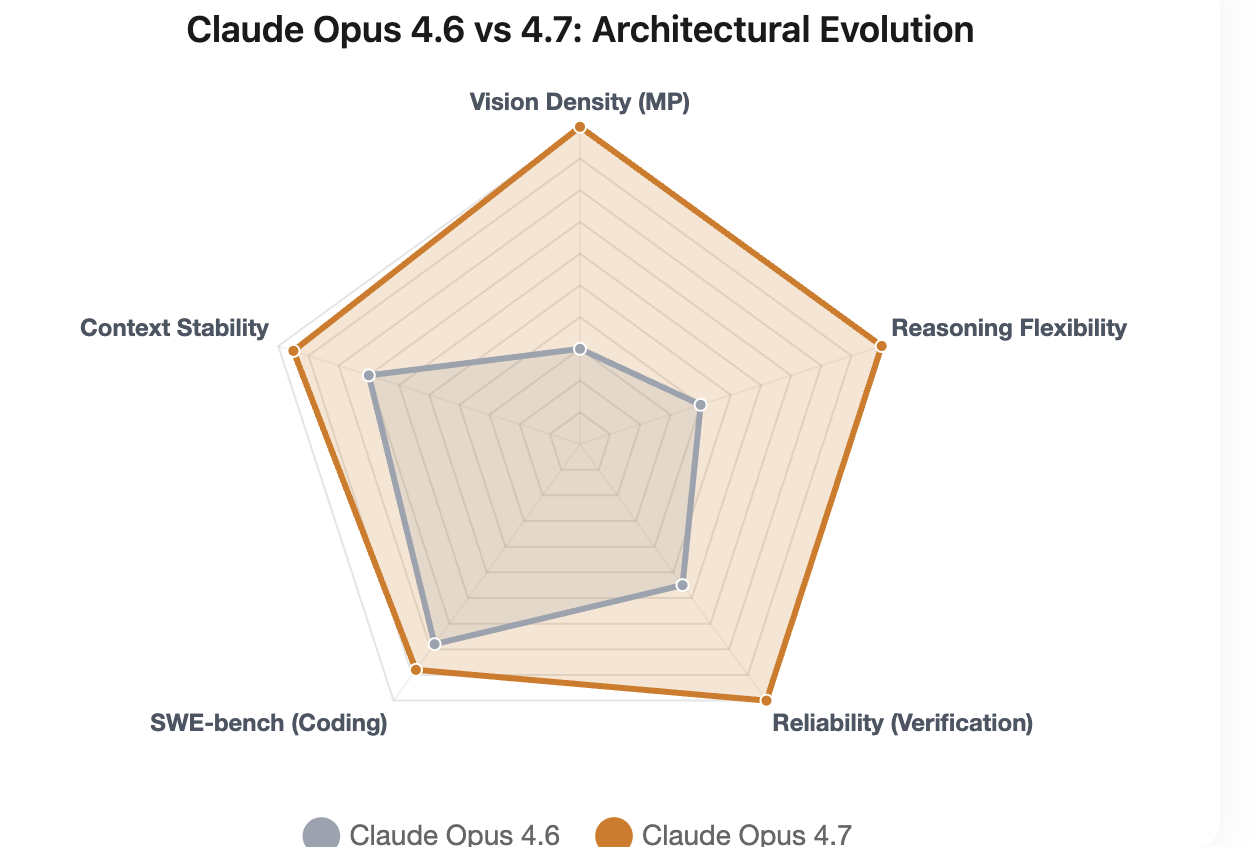
Claude Opus 4.7 isn't just an incremental update; it introduces several architectural shifts that redefine how AI handles data:
Self-Verifying Logic: The model now performs internal audits, running hidden test cases before delivering a final answer, which drastically reduces technical hallucinations.
High-Density Multi-Modal Perception: With a 3.3x increase in resolution (now supporting 3.75MP), Opus 4.7 can read fine-print blueprints and dense UI screenshots that were previously illegible.
Dynamic Compute Allocation: Through Adaptive Thinking, the model can decide when to spend extra "thinking tokens" on hard problems and when to respond instantly to simple ones.
Infrastructure Reliability: Despite a 1.35x tokenizer multiplier and the recent mid-April service fluctuations, the model’s SWE-bench Verified score of 87.6% makes it the default choice for 2026 engineering teams.
Adaptive Thinking: The Secret Behind Claude 4.7’s Reasoning Mastery
Defining Adaptive Thinking
Unlike previous versions that relied on fixed reasoning steps, Claude Opus 4.7 introduces Adaptive Thinking. This allows the model to dynamically allocate compute based on task complexity. Instead of wasting tokens on simple greetings, the model reserves its "thinking energy" for solving multi-file code regressions or identifying subtle legal contradictions.
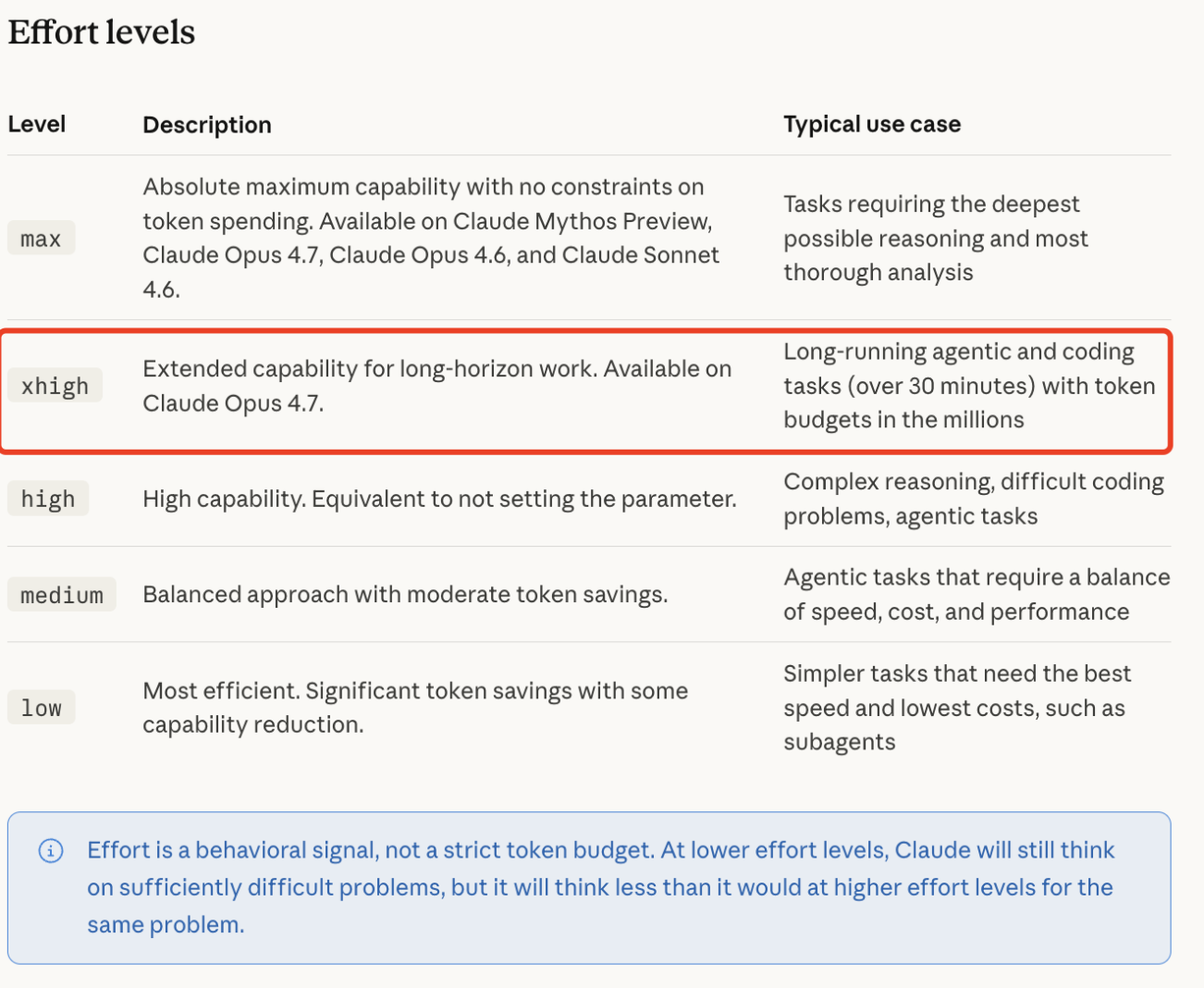
The 'Effort' Parameter: Low to XHigh
Developers now have granular control through the effort parameter. The most significant addition is the xhigh effort level, positioned between high and max. This setting is designed specifically for agentic coding where the model must self-audit its logic across thousands of lines of code before providing a pull request.
Self-Verification Mechanism
Opus 4.7 doesn't just guess; it verifies. During a reasoning trace, the model proactively writes internal test cases and logic checks. This Self-Verification reduces hallucination rates in technical documentation by up to 40% compared to Opus 4.6, making it the most reliable model for high-stakes engineering.
Latency vs. Quality: The Thinking Budget
The trade-off for this depth is latency. High-effort tasks can take longer to stream, but with the new Task Budgets (beta), users can set a token ceiling. This ensures the model finishes its "thought process" without overspending on an infinite loop, providing a predictable cost-to-quality ratio for enterprise users.
2026 Benchmarks: Quantifying the Superiority of Opus 4.7
SWE-bench Verified (87.6%)
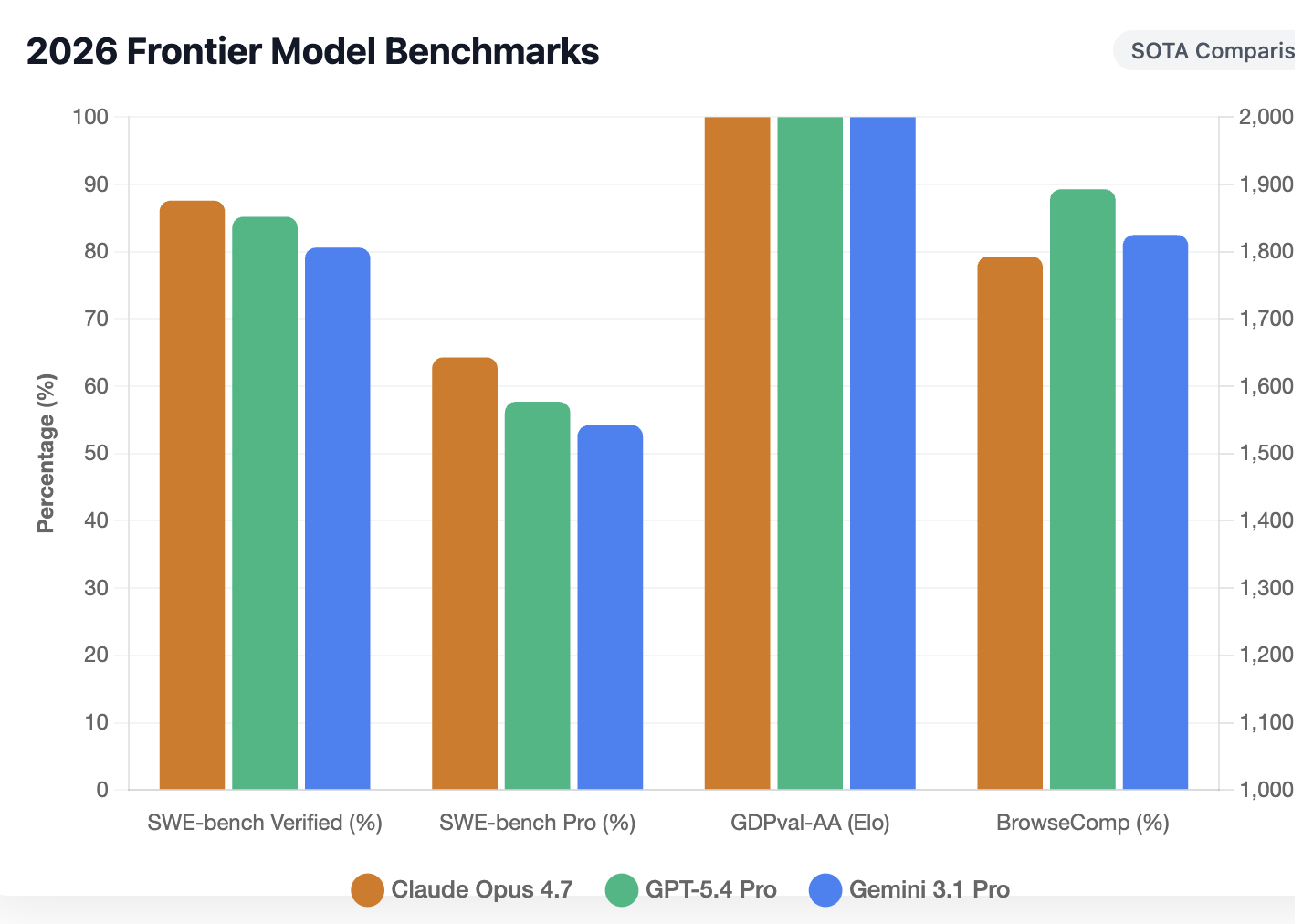
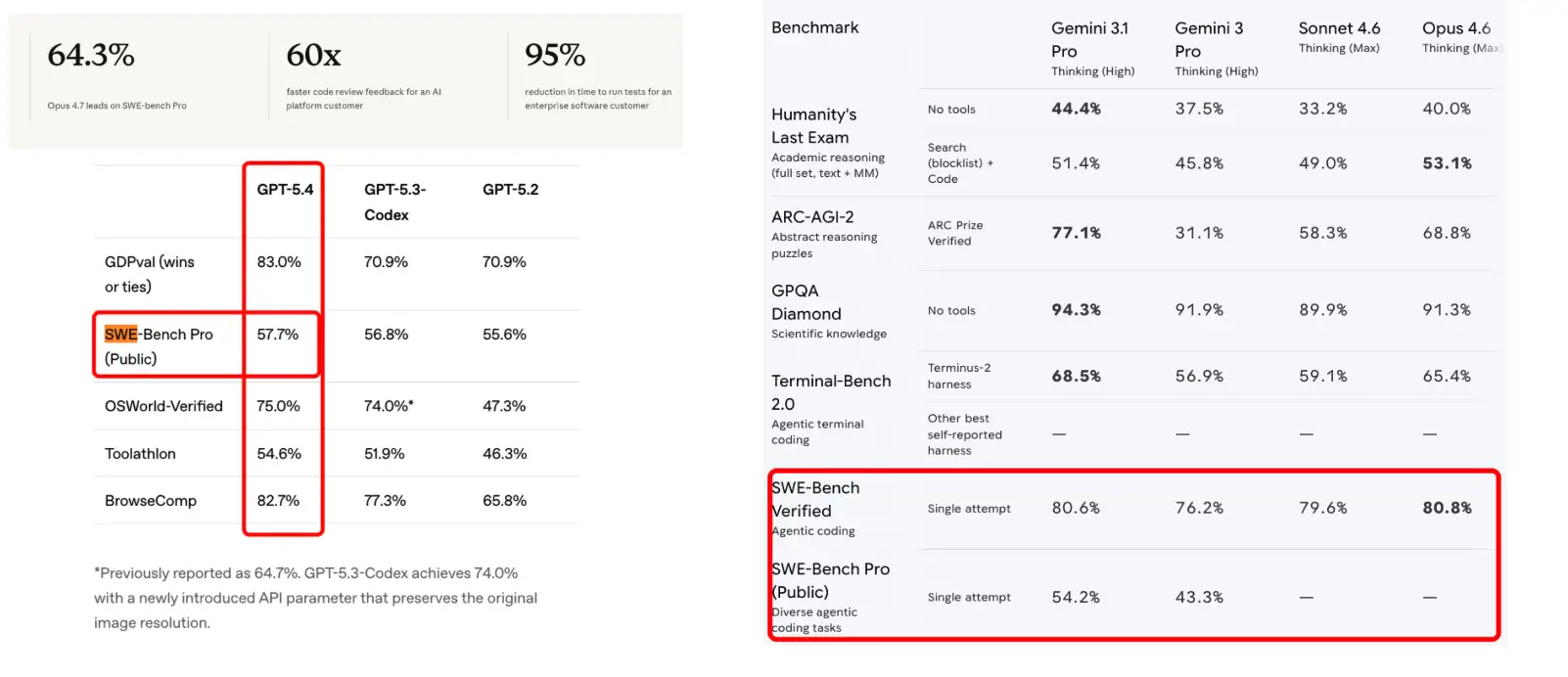
Claude Opus 4.7 has reclaimed the throne in autonomous software engineering. Scoring a record 87.6% on SWE-bench Verified, it officially surpasses GPT-5.4 Thinking. In the even more grueling SWE-bench Pro—which tests multi-step execution—it achieved 64.3%, a massive leap from the 53.4% seen in its predecessor.
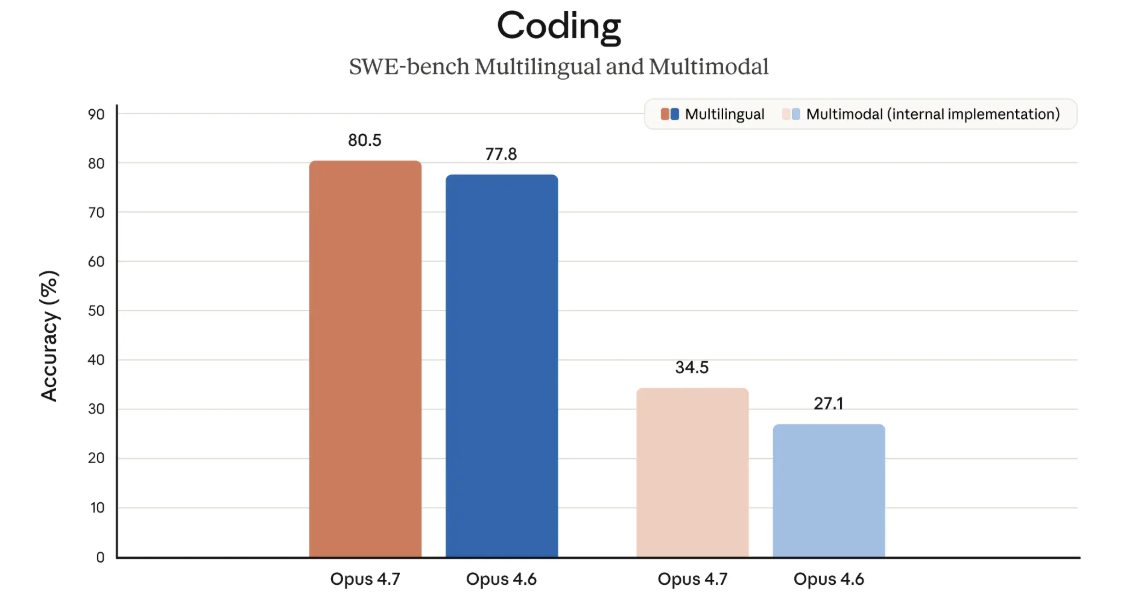
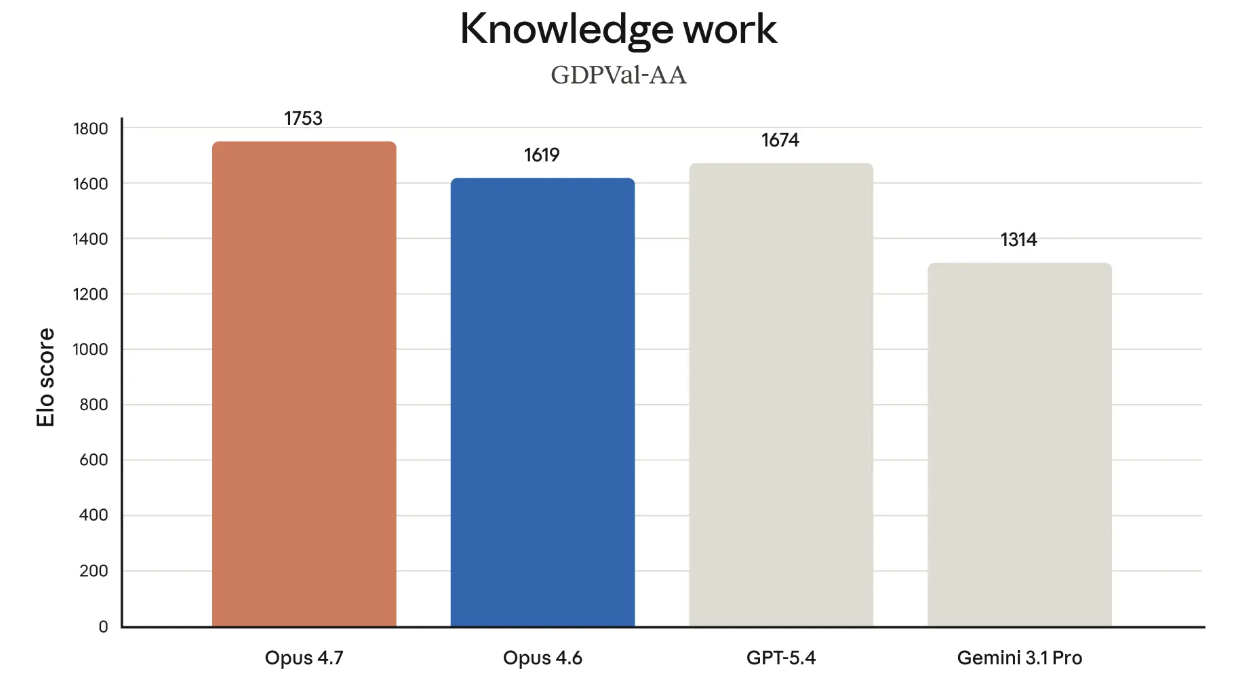
GDPval-AA: Dominating Knowledge Work
In professional domains like Law, Finance, and Consulting, Opus 4.7 sits at 1753 Elo points on the GDPval-AA benchmark. This leads the industry, proving that the model can handle economically valuable tasks that require high-fidelity document comprehension.
OSWorld-Verified and Agentic Autonomy
For users building agents that control computers, the OSWorld-Verified score of 78.0% highlights Opus 4.7’s ability to navigate UIs, click buttons, and execute terminal commands with human-like precision. It is effectively the first model that can be trusted with a "background agent" status for multi-hour tasks.
High-Resolution Vision Upgrade: Seeing the World in 3.75MP
The most "visual" upgrade in Claude Opus 4.7 is the expansion of its pixel-processing limits. The model has shattered the old 1568px barrier, now supporting images up to 2576px on the long edge (~3.75 Megapixels). This is a 3.3x increase in total pixel density.
This upgrade is crucial for:
Architectural Blueprints: Reading fine text and measurements in CAD exports.
Medical Imaging: Analyzing high-density X-rays or histology slides.
UI/UX Audits: Mapping coordinates 1:1 to actual pixels for pixel-perfect frontend development.
By integrating Claude Opus 4.7 into your workflow, you no longer need to downsample complex charts, ensuring that no detail is lost during the extraction of structured data from visual sources.
The Hidden Economics: Tokenizer 2.0 and Prompt Caching
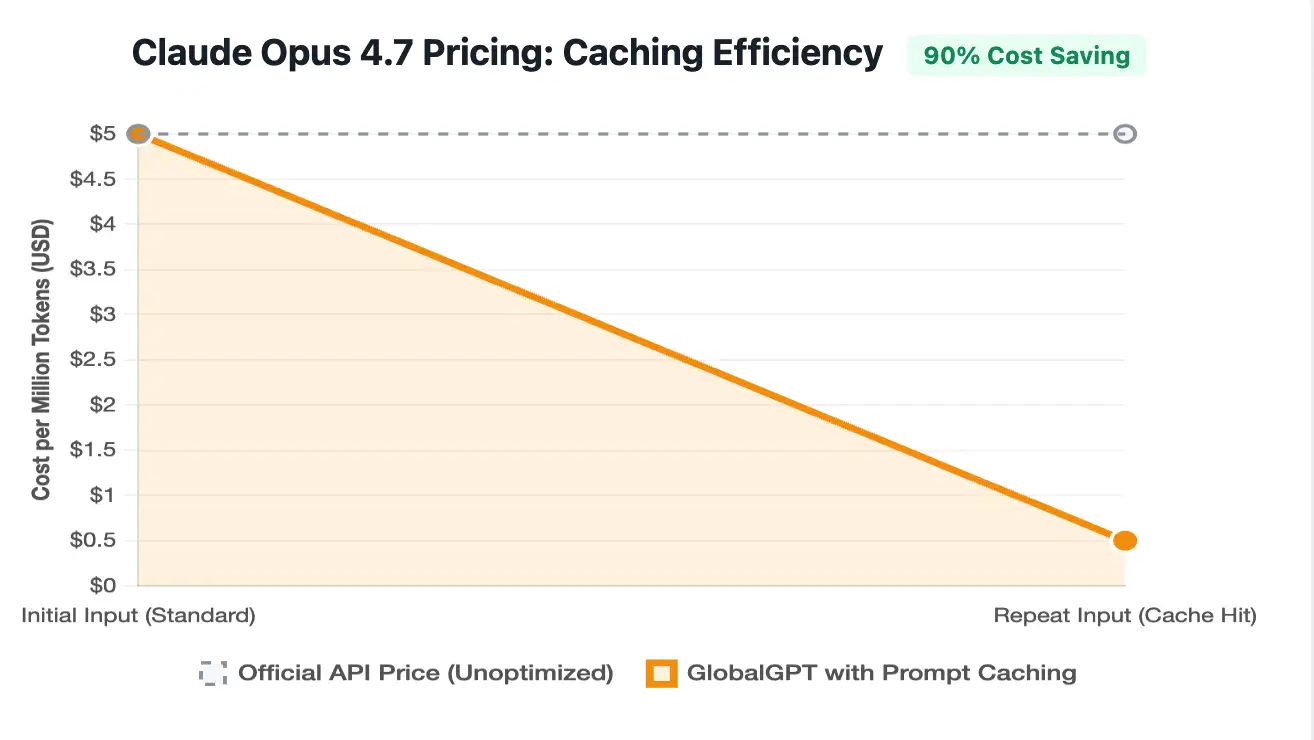
While official pricing remains at $5/MTok (Input) and $25/MTok (Output), the actual cost of using Opus 4.7 has shifted. The model uses a new, more granular Tokenizer, which results in a 1.35x token multiplier for the same paragraph of English text.
GlobalGPT acknowledges these rising costs, which is why we emphasize the use of Prompt Caching. By caching frequent instructions or large codebases, users can hit these "cached tokens" for just $0.50 per million tokens—a 90% discount over standard input rates.
For heavy users, this makes the $5.8 GlobalGPT Basic Plan the most economical way to run long-context tasks without fearing the 35% "tokenizer tax" imposed by official API consumption patterns.
Direct Comparison: Claude Opus 4.7 vs. GPT-5.4 vs. Gemini 3.1
Choosing the right SOTA (State-of-the-Art) model in 2026 depends on your specific workflow. While Opus 4.7 dominates in engineering consistency, competitors like Gemini 3.1 Pro offer unique strengths in other areas.
Feature | Claude Opus 4.7 | GPT-5.4 Thinking | Gemini 3.1 Pro |
Primary Strength | Agentic Coding | Real-time Web Search | Context Window (2M+) |
Thinking Mode | Adaptive (XHigh) | Plan-Ahead Thinking | Fast Thinking |
Vision Resolution | 3.75 MP | 2.0 MP | 1.8 MP |
Stability | High (Self-Verifying) | Medium | High |
Access Plan | $5.8 Basic | $5.8 Basic | $5.8 Basic |
GlobalGPT allows you to test all three models side-by-side using the same API balance, removing the need for three separate $20 subscriptions.
How to Access Claude Opus 4.7 Without Regional Restrictions
For many professional creators, the biggest barrier isn't intelligence—it's access. Official subscriptions require non-restricted regions and specific credit cards, often leading to account bans or payment failures.
GlobalGPT provides a "Zero-Barrier" gateway to the entire 2026 AI lineup:
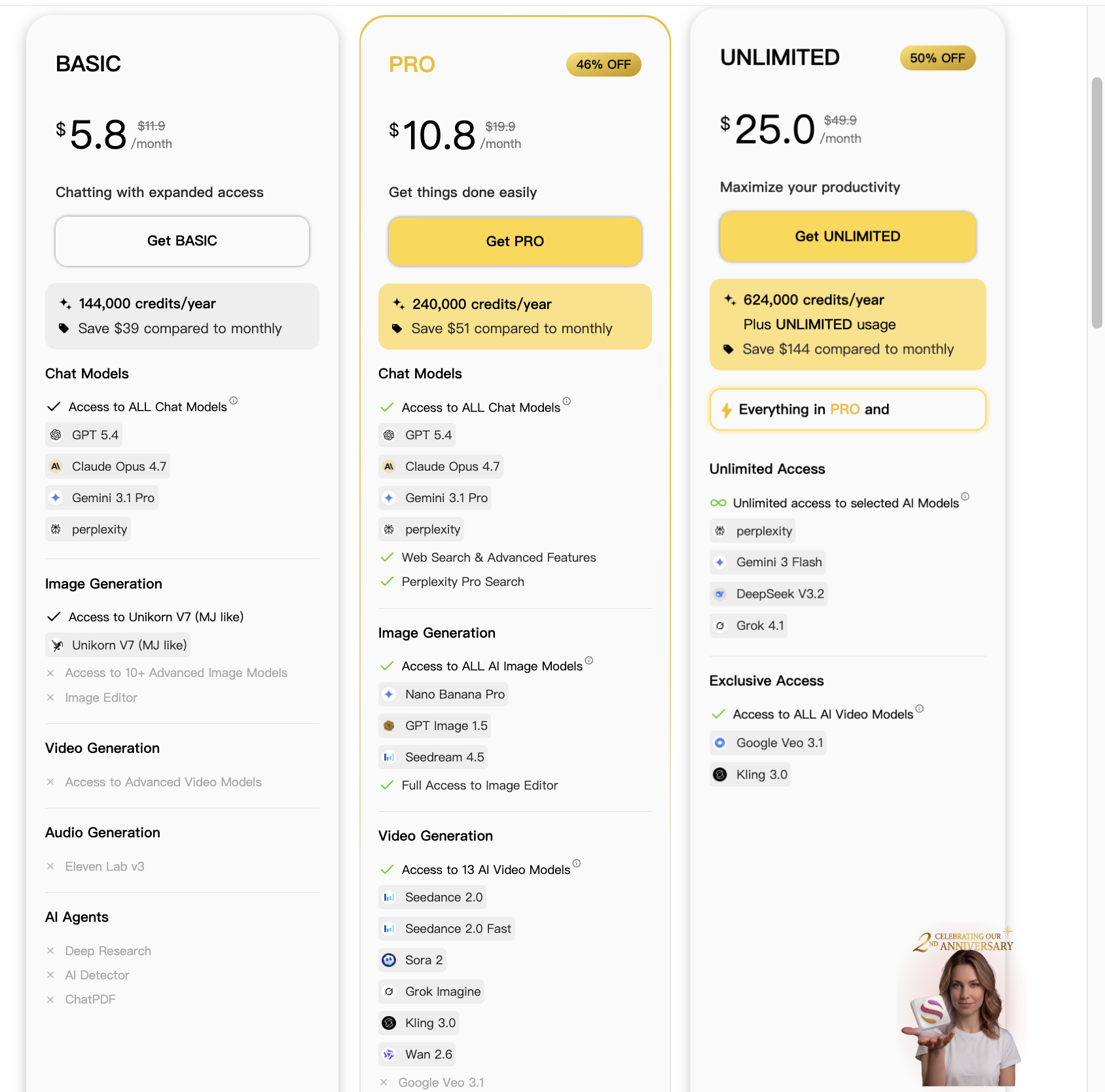
$5.8 Basic Plan: Best for software engineers and researchers using Claude Opus 4.7, Sonnet 4.6, and GPT-5.4 Thinking.
$10.8 Pro Plan: Mandatory for high-end creative workflows, including Sora 2, Seedance 2.0, Grok Imagine, Veo 3.1, and Flux Pro.
Full-Cycle Workflow: Combining Opus 4.7 with Video & Image AI
The true potential of Claude Opus 4.7 is unlocked when combined with other models in a Full-Cycle Workflow. Professional users on GlobalGPT are already moving beyond simple chat:
Ideation & Code: Use Claude Opus 4.7's
xhigheffort level to build a project's architecture.Visual Branding: Pass the design requirements to Midjourney or Nano Banana 2 for 4K visuals.
Video Promotion: Use Sora 2 or Wan to create cinematic trailers based on the Claude-generated script.
By using GlobalGPT, you complete your entire production pipeline—from high-stakes reasoning to video rendering—within one unified dashboard, saving hours of context switching and hundreds of dollars in subscription fees.
Conclusion: Why Claude Opus 4.7 is the Professional Standard for 2026
Claude Opus 4.7 isn't just an incremental update; it is an Agentic Engine. With its 87.6% SWE-bench score, 3.75MP vision, and Adaptive Thinking, it is the definitive choice for professionals who value reliability over conversational fluff. While the new tokenizer increases costs, the intelligence gain is undeniable.
GlobalGPT puts this power in your hands with a single, affordable account, ensuring that you stay at the frontier of AI without the friction of official barriers.
Frequently Asked Questions (FAQ) About Claude Opus 4.7
Is Claude Opus 4.7 available for free users?
Currently, Claude Opus 4.7 is primarily reserved for Claude Pro, Team, and Enterprise subscribers. Free users on Claude.ai typically default to Claude Sonnet 4.6. However, you can access Claude Opus 4.7 with no monthly commitment for as low as $5.8 through the GlobalGPT Basic Plan, which provides a pay-as-you-go style access to the API model.
What is the 'xhigh' effort level in Claude 4.7?
The
xhigheffort parameter is a new reasoning setting that allows Claude Opus 4.7 to dedicate maximum compute to a single task. It is specifically optimized for agentic coding and complex legal analysis where the model must self-verify its logic. While it increases latency, it significantly reduces the likelihood of "logic loops" or hallucinations in high-stakes projects.Why does Claude 4.7 seem more expensive than version 4.6?
While the official price remains $5 per million input tokens, Claude Opus 4.7 uses a more granular Tokenizer 2.0. This results in a 1.0x to 1.35x increase in token count for the same block of text. To offset this, GlobalGPT users are encouraged to use Prompt Caching, which reduces the cost of repetitive inputs to just $0.50/MTok.
Can Claude Opus 4.7 process high-resolution blueprints?
Yes. One of the biggest upgrades in the April 2026 release is the support for 3.75MP (2576px) resolution. This is a 3.3x density improvement over previous models, making Opus 4.7 capable of reading fine print on architectural blueprints, medical X-rays, and dense financial charts without loss of detail.
How does Claude 4.7 compare to GPT-5.4 Thinking?
Claude Opus 4.7 currently holds the SOTA (State-of-the-Art) title for Software Engineering with an 87.6% SWE-bench Verified score, beating GPT-5.4. However, GPT-5.4 remains superior in real-time web search and agentic browsing. For most execution-heavy professional workflows, Claude 4.7 is the preferred choice in 2026.
How can I bypass Claude region restrictions?
Many users face "service not available in your country" errors or credit card declines. GlobalGPT removes these barriers by providing a unified dashboard that supports all major models (Claude 4.7, GPT-5.4, Sora 2) with no region blocks and flexible payment options.Users can switch between the logic of Claude 4.7 and the visual power of Midjourney in a single tab, bypassing all usage limits and regional blocks.