Claude Opus 4.8: Smarter or Just Louder?

Every major AI release now comes with a familiar promise: smarter, faster, more capable, and somehow the new “most powerful model.” That is why Claude Opus 4.8 is interesting. It is not just another model launch to take at face value. It arrives at a time when users are harder to impress, especially developers who have already lived through plenty of AI hype cycles.
As someone who works on an AI platform like GlobalGPT and has actually used Claude 4.8 across writing, coding, and research tasks, I do not think a launch post tells the whole story. The official announcement shows what Anthropic wants to emphasize, but the real picture only becomes clear when people start using the model in everyday workflows: writing drafts, testing code, comparing costs, and deciding whether it is worth switching from the previous version.
That is the real question behind this release:
Is Claude Opus 4.8 actually smarter in the ways users care about, or is it just louder because every frontier model now arrives with big claims?
For most users, the answer will not come from a benchmark chart alone. It will come from practical questions:
Can it handle long coding tasks better?
Does it stay on track in large context windows?
Is it meaningfully better than Opus 4.7 and Opus 4,6 ?
Does it feel more reliable when tools, files, and multi-step work are involved?
Is the cost still reasonable once the workflow gets long?
My early impression is that claude opus 4.8 is stronger in long workflows, especially coding, research, and agent-style tasks. But it is also competing with users’ memory of Claude 4.6, which many still see as the most comfortable version. That is why side-by-side testing matters. On GlobalGPT, users can compare Claude 4.6 and newer models in the same workflow, which is often more useful than judging the release by launch claims alone.
What Is Claude Opus 4.8?
claude opus 4.8 is Anthropic’s newest Opus model, released on May 28, 2026. Anthropic describes it as its most capable generally available model for complex reasoning, long-horizon agentic coding, and high-autonomy work.
In plain English, claude opus 4.8 is built for heavier tasks, not just quick chat. It is aimed at users who need a model to work through longer sessions without losing the plot.
Typical use cases include:
Large codebase analysis
Long document review
Multi-step research
Coding agents and tool use
Complex business, legal, or technical workflows
Agent-style automation where the model needs to plan, act, and verify
The API model ID is claude-opus-4-8. Officially, Claude Opus 4.8 supports a 1M token context window by default on Claude API, Amazon Bedrock, and Google Vertex AI. On Microsoft Foundry, the context window is 200K tokens. It also supports 128K max output tokens in the synchronous Messages API.
That gives the model a clear direction: claude opus 4.8 is not just trying to answer better. It is trying to stay useful for longer.
To me, that is the real positioning. Anthropic is not only selling intelligence here. It sells reliability across long, tool-heavy workflows.
What’s New in the Claude 4.8 Opus Release?
The claude 4.8 opus release focuses on long-context performance, coding agents, tool use, reasoning control, and honesty.
Update | Why It Matters |
1M context window | Handles larger codebases, documents, and long tasks. |
200K context on Microsoft Foundry | Foundry users get a smaller but still large context window. |
128K max output | Supports longer code, reports, and plans. |
Adaptive thinking | Adjusts reasoning effort based on task difficulty. |
High effort by default | Aims for stronger results on complex tasks. |
Fast mode | Offers faster output in Claude API research preview. |
Mid-conversation system messages | Lets agents update instructions during a task. |
Lower prompt cache minimum | Makes caching useful for shorter repeated prompts. |
Better tool use | Reduces missed or skipped tool calls. |
Better compaction recovery | Helps Claude stay on track in long workflows. |
More honest behavior | Flags uncertainty more clearly. |
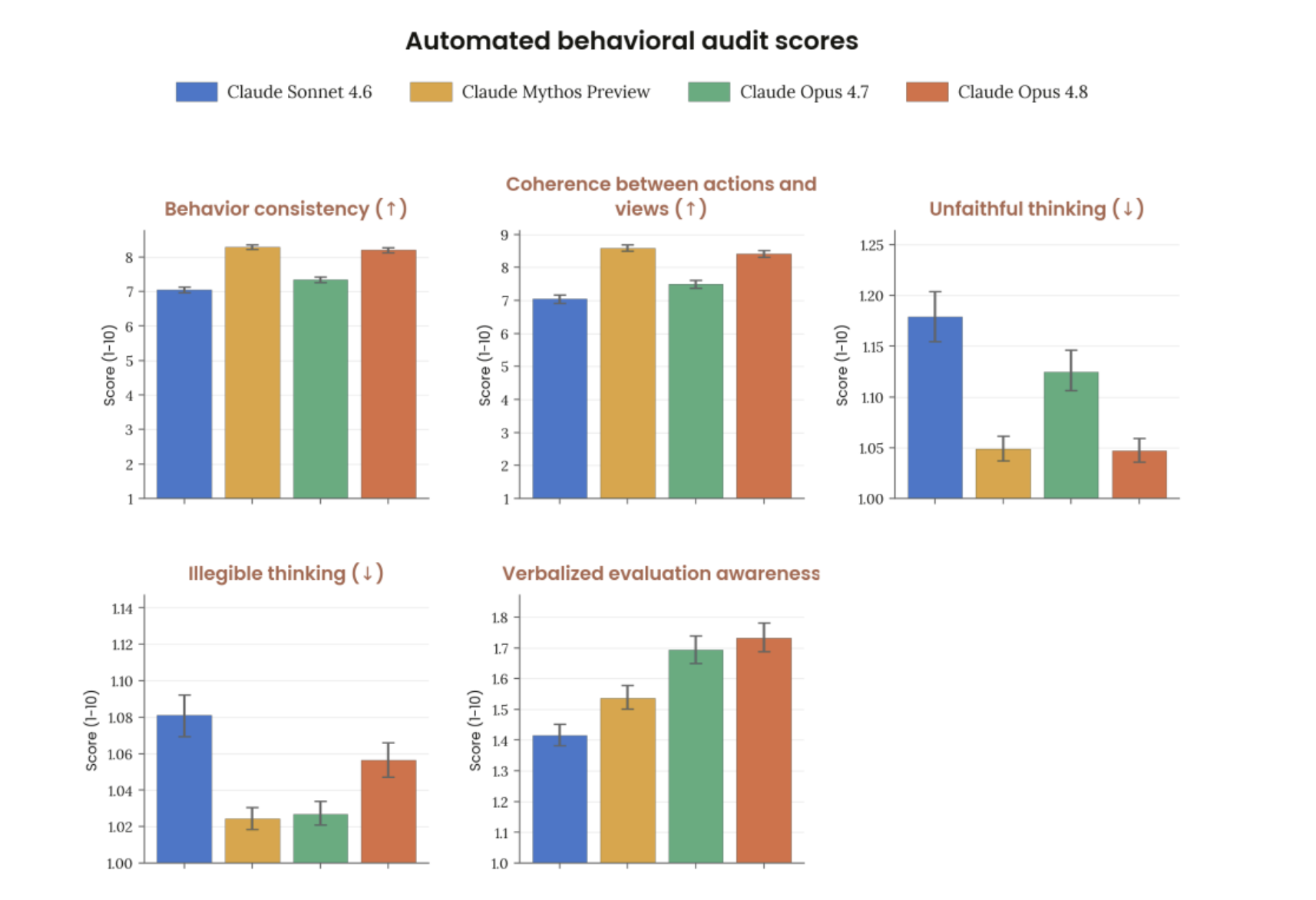
The most practical change may be the combination of long context, better tool triggering, and better compaction handling. These sound technical, but they are where long AI workflows often break. In actual testing, the problem is usually not one huge failure. It is smaller things: forgetting earlier context, skipping a tool call, or drifting after compression. That is why this update feels more useful than another benchmark claim.
Another important feature is mid-conversation system messages. This lets developers update Claude’s instructions during a long-running task without rewriting the whole system prompt. In real use, this matters because tasks change. A coding task changes after the model sees the repo. A research task changes after new sources appear. Claude Opus 4.8 is clearly being built for that kind of moving workflow.
Fast mode is also worth noting, but with a caveat. It is a research preview on the Claude API and can deliver up to 2.5x higher output tokens per second, but it comes at premium pricing. From a testing perspective, speed really does change how usable a model feels, especially when you are comparing drafts, revising code, or checking multiple options. But it is not simply “free faster Claude.”
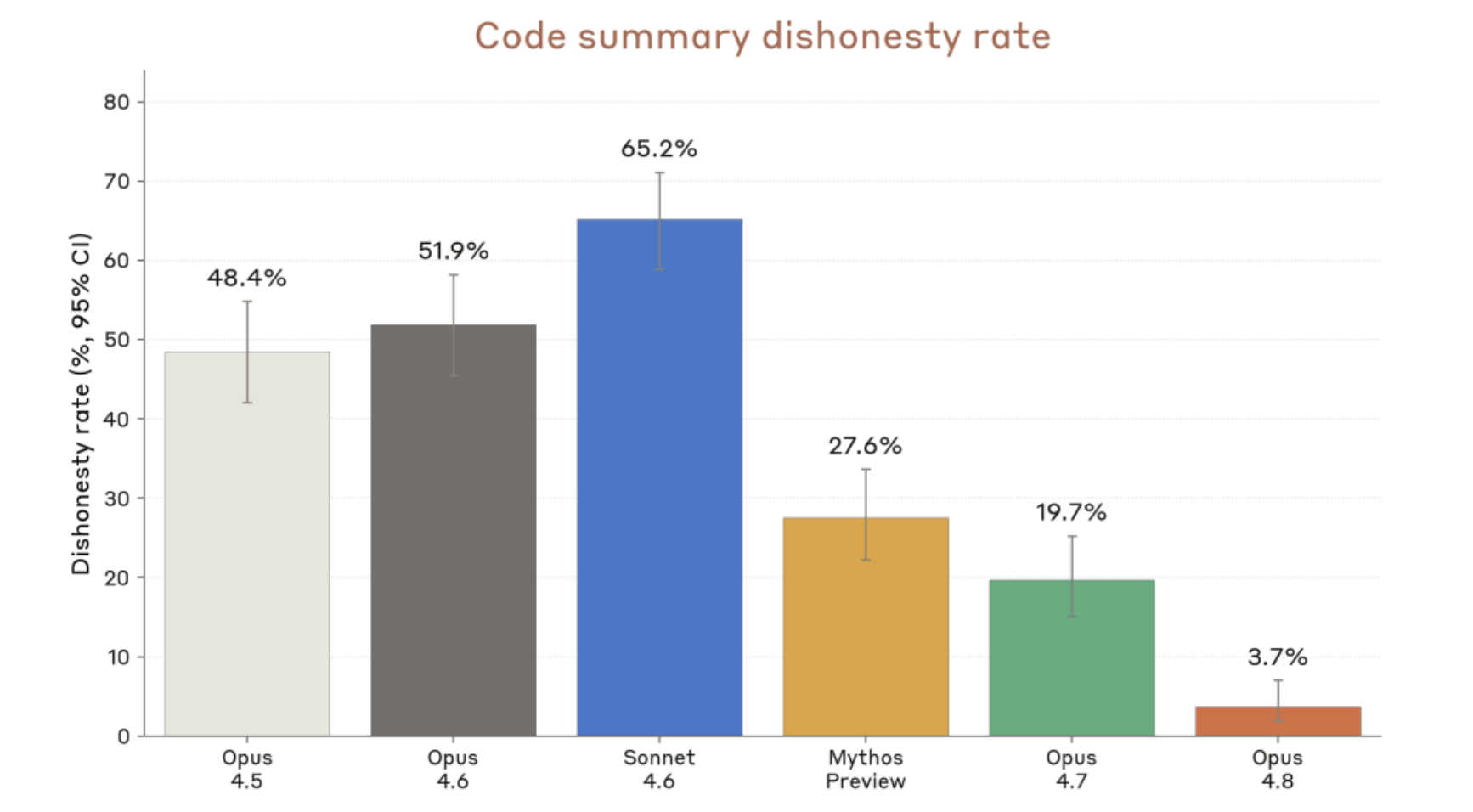
The most interesting update may be honesty. Anthropic says claude opus 4.8 is more likely to flag uncertainty and less likely to make unsupported claims about its progress. For me, this matters because the worst AI mistake is not always being wrong. It is being wrong with confidence, because that pushes the real checking work back onto the user.That matters. In real work, a model that admits uncertainty can be more useful than a model that sounds confident while quietly being wrong.
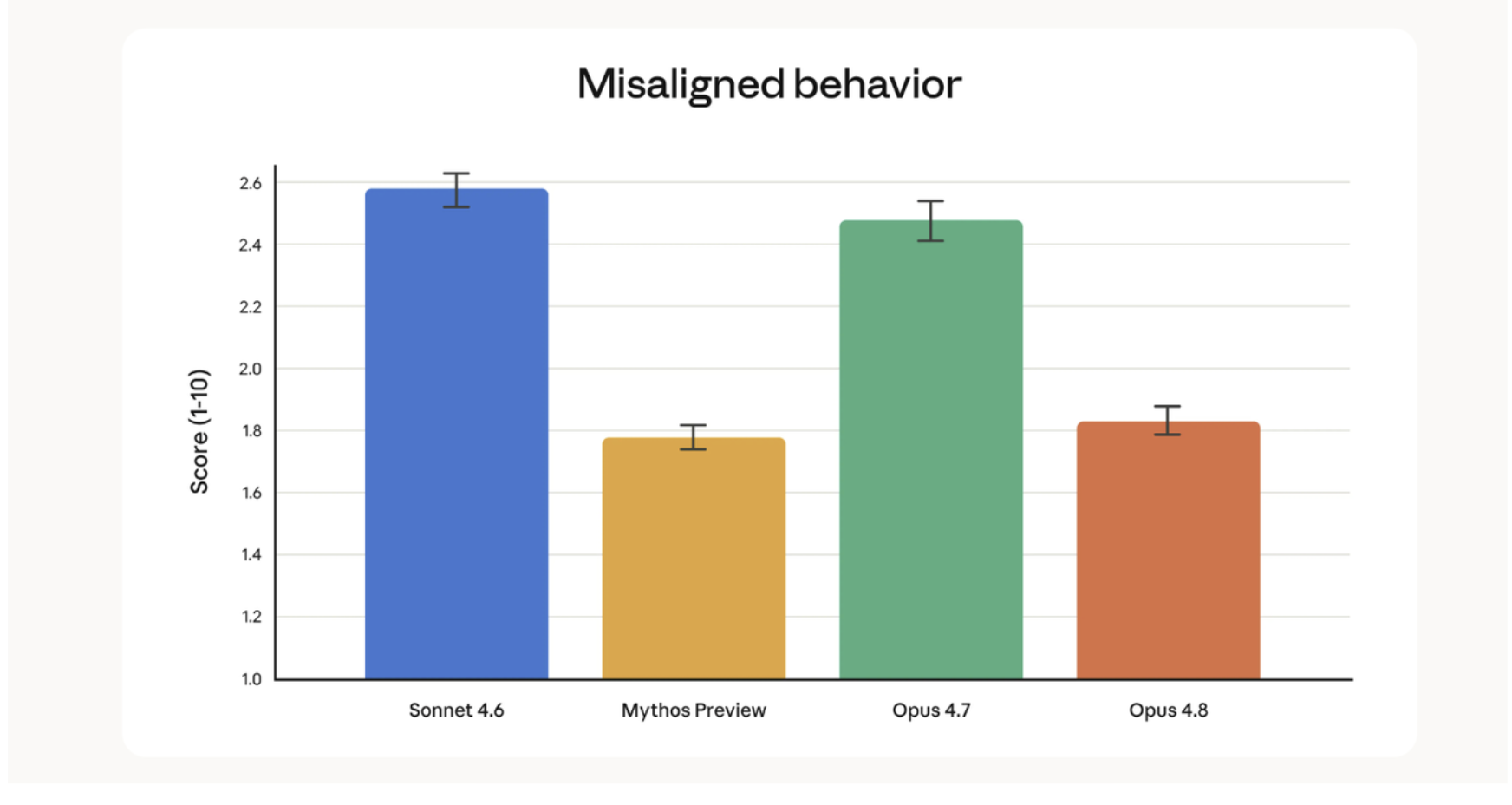
Claude Opus 4.8 in Claude Code
Claude Code may be the best place to judge claude opus 4.8.
In normal chat, a model can look strong with one polished answer. Claude Code is different. It forces the model to inspect files, understand a repo, plan changes, call tools, handle errors, and remember what it already did. After testing AI models in coding workflows, I usually trust this kind of environment more than a simple benchmark because weak models expose themselves quickly here.
This is why opus 4.8 claude code is such an important topic. The real test is not whether the model can write a function. Most frontier models can do that. The test is whether it can keep working across a full development session without losing context, skipping checks, or confidently saying a task is done when it is not.
The biggest Claude Code update is dynamic workflows. Anthropic says this feature allows Claude Code to plan larger tasks, run hundreds of parallel subagents in one session, and verify outputs before reporting back to the user. With claude opus 4.8, those agents can also run for longer.
The use case Anthropic gives is codebase-scale migration across hundreds of thousands of lines of code, using the existing test suite as the quality bar. That is a serious claim. It also matches the pain point I see most often in coding agents: the first answer may look good, but the real value is whether the model can survive the messy middle of a task.
For developers, the useful questions are very practical:
Does claude opus 4.8 call the right tools?
Does it avoid skipping important checks?
Does it recover better after context compaction?
Does it catch its own mistakes before the user does?
Does it finish more real tasks, not just produce better-looking plans?
This is where early user feedback becomes useful. Some users say Opus 4.8 feels more stable than Opus 4.7, especially in larger coding tasks. Others still report failures, stricter behavior, or mixed results in coding tests. I find that split believable. Coding agents are rarely simply “good” or “bad.” They can be excellent for one repo, then strangely fragile on another.
My view is that Claude Code is where claude opus 4.8 makes the strongest case for itself. If you use it only for casual chat, the upgrade may not feel dramatic. If you use it for longer development work, the improvements in context handling, tool use, honesty, and workflow stability are much easier to notice.
Claude Opus 4.8 Pricing: Same Price, Different Cost?
The official pricing for claude opus 4.8 is unchanged from Opus 4.7 for regular API usage:
Input: $5 / million tokens
Output: $25 / million tokens
Fast mode uses premium pricing:
Input: $10 / million tokens
Output: $50 / million tokens
Prompt caching also has separate pricing:
5-minute cache writes: $6.25 / million tokens
1-hour cache writes: $10 / million tokens
Cache hits and refreshes: $0.50 / million tokens
For users who access Claude through the Claude app instead of the API, the subscription plans work differently:
Plan | Price | Best For |
Free | $0 | Basic testing and light use |
Pro | $20/month, or $17/month annually | Everyday productivity, more usage, Claude Code, and more Claude models |
Max 5x | $100/month | Frequent users who need more room for writing, research, and coding |
Max 20x | $200/month | Heavy daily users who use Claude across most tasks |
Team Standard | $25/seat/month, $20/seat/month annually | Teams that need shared billing, admin controls, and more usage than Pro |
Team Premium | $125/seat/month, $100/seat/month annually | Teams that need 5x more usage than standard Team seats |
Enterprise | Starts at $20/seat + usage at API rates | Large organizations with advanced security, controls, and custom usage needs |
On paper, the pricing looks simple. claude opus 4.8 keeps the same regular API price as Opus 4.7. But in real use, cost is not only about the listed price.
To meet that need, GlobalGPT takes an all-in-one model access approach. Instead of asking users to commit to one model ecosystem from the start, it offers different pricing plans for different usage levels. For users who want to test Claude, GPT, Gemini, DeepSeek, and other models without paying for several separate subscriptions, that kind of setup can make the cost decision feel more practical.
GlobalGPT Plan | Price | Credits | Model Access |
Basic | From $5.8/month, billed annually | 144,000 credits/year | Chat models such as Claude Opus 4.6, GPT-5 series, Gemini, and DeepSeek |
Pro | From $10.8/month, billed annually | 240,000 credits/year | All chat models, Perplexity Pro Search, full image model access, video models, audio models, and AI agents. |
Unlimited | From $25/month, billed annually | 624,000 credits/year + selected unlimited usage | Everything in Pro, plus unlimited access to selected models such as Perplexity, Gemini Flash, GPT-5 mini, and DeepSeek. |
There is also a small but important detail in Anthropic’s pricing docs: Opus 4.7 and later use a new tokenizer, and the same text may use up to 35% more tokens than previous models. That does not mean every task suddenly costs 35% more, but it does mean the real cost can feel different from the headline price.
Effort settings matter too. Claude Opus 4.8 uses high effort by default, and Anthropic says this gives the best balance of quality and user experience. For harder coding tasks, that may be worth it. But if users turn on higher effort levels like extra, xhigh, or max, token users can climb quickly.
So I would not judge claude opus 4.8 pricing only by asking, “How much does it cost per million tokens?”
The better question is:
Does it complete enough useful work before the cost starts to feel heavy?
If Claude Opus 4.8 solves a difficult coding or research task with fewer retries, the price makes sense. If it spends too much time planning, correcting itself, or producing long answers that still need heavy checking, users will feel the cost very quickly.
Opus 4.7 vs 4.8: What Actually Changed?
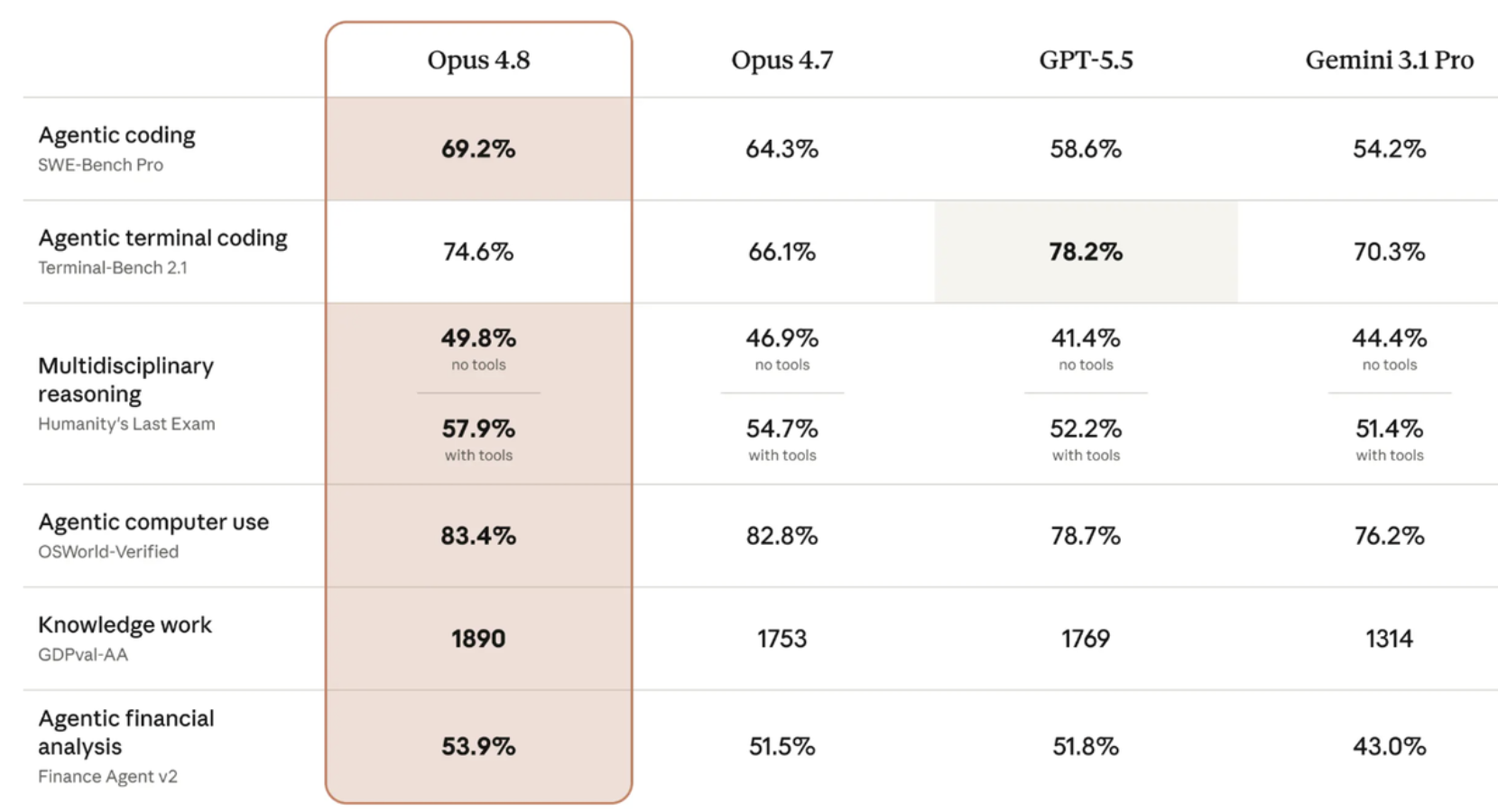
The opus 4.7 vs 4.8 comparison is one of the biggest reasons people care about this release. Opus 4.7 disappointed a lot of Claude users, especially those who had been using Opus 4.6 heavily for coding, writing, legal work, and long research tasks.
From the official side, Claude Opus 4.8 is clearly designed to fix some of those problems. It has better long-context behavior, better tool triggering, stronger agent support, and more honest self-checking. On paper, that makes it a cleaner and more capable upgrade over Opus 4.7.
But user feedback is more complicated.
Some users say Claude Opus 4.8 feels much better than 4.7, especially in Claude Code and larger coding tasks. They describe it as more stable, more focused, and less likely to get stuck in useless loops.
Others still prefer Claude Opus 4.6. This is the part that makes the release interesting. For many users, the real comparison is not only opus 4.7 vs 4.8. It is Claude Opus 4.8 vs the older Claude they remember trusting.
A simple way to read feedback is this:
Version | How Users Often Describe It |
Claude Opus 4.6 | Comfortable, reliable, natural, still preferred by many long-time users |
Claude Opus 4.7 | More controversial, often seen as a step back by heavy Claude users |
Claude Opus 4.8 | Better than 4.7 for many workflows, but still not a universal replacement for 4.6 |
This is why side-by-side testing matters. On GlobalGPT, users can still compare models like Claude Opus 4.6 and newer Opus versions in similar workflows. That is useful because memory can be misleading, but launch claims can be misleading too. The best test is still the same task, same user, different model.
My read is simple: claude opus 4.8 is a meaningful recovery from 4.7, but not everyone will feel it as a clean return to 4.6.
What Users Are Saying: Praise, Doubt, and Drama
Early user reactions to Claude Opus 4.8 are not one-sided. That is actually a good sign for a model review, because it means people are testing it in real work instead of only reacting to the announcement.
Positive Feedback | What It Means |
Better performance in long coding tasks | Users see more value when the task has multiple steps, files, or decisions. |
More stable Claude Code sessions | The model appears better suited for longer development workflows. |
Stronger tool use | Fewer skipped steps or missed tool calls can make agent tasks more reliable. |
More honest uncertainty | Users value when the model admits uncertainty instead of sounding falsely confident. |
Better long-context handling | Claude Opus 4.8 seems more useful when conversations or documents get large. |
Negative Feedback | What It Means |
Higher token usage or faster limit burn | Some users worry the upgrade may feel more expensive in practice. |
Slower responses in some effort modes | Better reasoning can feel less useful if the workflow becomes too slow. |
Stricter or more cautious behavior | Some users feel the model is less flexible or more restricted. |
Mixed coding test results | Claude Opus 4.8 does not win every coding task for every user. |
Opus 4.6 still feels better to some users | Older Claude versions still shape user expectations. |
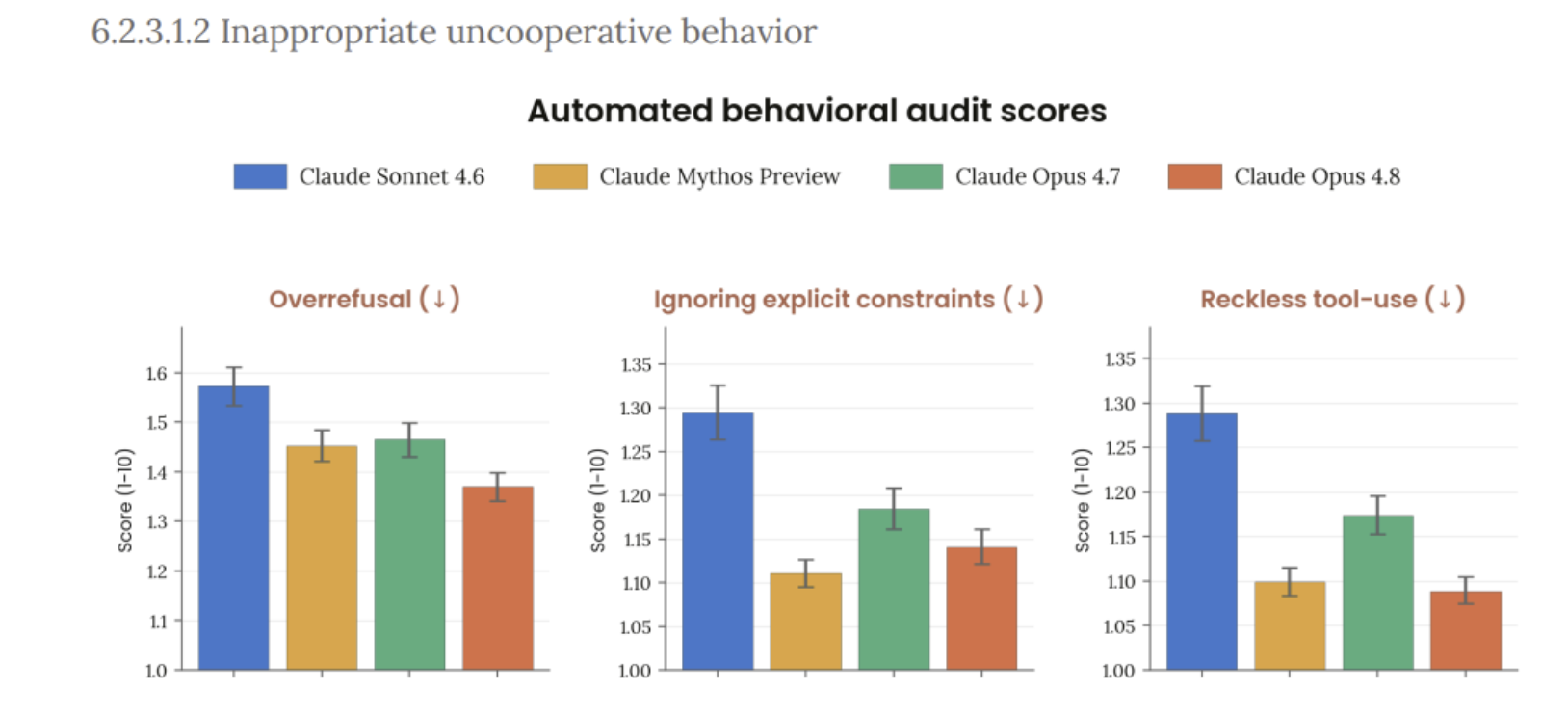
The strongest praise tends to come from users who care about agent workflows. For them, opus 4.8 Claude Code is the real story. If the model can stay focused across a repo, use tools correctly, and catch more of its own mistakes, that is a real upgrade.
The strongest criticism tends to come from users who loved Claude Opus 4.6. For them, Claude Opus 4.8 is not being judged against a benchmark. It is being judged against a past experience: a version of Claude that felt easier to trust.
That split is important. It shows that users now judge AI models by more than intelligence.
What Users Judge | Why It Matters |
Cost | A stronger model still needs to feel worth the usage or subscription cost. |
Speed | Slow output can make even a smart model feel harder to use. |
Style | Users care whether the model feels natural, helpful, or too corporate. |
Reliability | The model needs to stay useful across long tasks, not just one answer. |
Honesty | Admitting uncertainty can be better than giving confident wrong answers. |
Extra checking work | If users must verify everything manually, the model saves less time. |
So when users disagree about Claude Opus 4.8, they may not actually disagree about the same thing. A developer running Claude Code, a writer drafting long articles, and a legal user reviewing documents are all testing different parts of the model.
Final Verdict: Smarter or Just Louder?
So, is Claude Opus 4.8 smarter or just louder?
My answer is: smarter for serious workflows, but louder than its everyday impact for some users.
I do think Claude Opus 4.8 improves in areas that matter: long context, coding agents, tool use, workflow recovery, and honesty. Those are not small things. In real work, a model that stays on track is often more valuable than a model that gives one impressive answer.
But I would not call it a universal upgrade. If someone mainly uses Claude for casual chat, quick writing, or short answers, Claude opus 4.8 may not feel dramatic. Some users may even prefer the tone and rhythm of older Claude versions.
The best way to understand this release is not as a simple “new model beats old model” story. It is more like a trust reset.
Anthropic seems to be saying: Claude should not only be powerful. It should be dependable when the task gets long.
That is the part I find most important. The question is no longer whether an AI model can answer a prompt. The question is whether it can stay useful when the work gets long, expensive, and messy.
For Claude Opus 4.8, the answer is mostly yes in coding and agentic workflows. But the mixed feedback shows that Anthropic still has work to do if it wants every Opus user to feel that same confidence.
Final Thoughts
Claude Opus 4.8 is a meaningful release, but not because it ends the AI model race. It does not. Another company will announce another “most powerful model” soon enough.
What makes Claude Opus 4.8 worth watching is the direction it points to. Anthropic is clearly pushing Claude toward long-context work, coding agents, dynamic workflows, and more honest progress reporting.
That matters because users are becoming more practical. They do not only want a model that sounds smart. They want a model that saves time, handles complexity, and does not create extra cleanup work.
So no, Claude Opus 4.8 is not just noise. But it is also not a magic fix for every user. It is strongest when the task is long, technical, and workflow-heavy.
In the end, Claude Opus 4.8 may or may not be the smartest model in the room. But it shows where the room is moving: toward AI that is judged not just by what it says, but by how well it works.