

Ik bleef op voor de I/O keynote en toen Google Gemini 3.5 Flash introduceerde, moest ik het terugspoelen.
De Flash-ranglijst is altijd de “goed genoeg, goedkoop, snel” optie in de line-up. Deze keer beweerde Google dat het de vorige Pro-tier versloeg - niet op een uitverkoren criterium, maar op de meeste coderings- en agentbenchmarks.
Zulke aankondigingen gaan meestal in twee richtingen. Of de leverancier heeft de grafiek gekozen die hem goed uitkomt, of er is echt iets veranderd. Dus toen we Gemini 3.5 Flash hadden toegevoegd aan GlobalGPT, heb ik ongeveer twee weken lang echt werk gedaan - onderzoek, diavoorstellingen, taken met meerdere stappen in agentstijl, het soort werk dat ik normaal gesproken zou verdelen over drie verschillende abonnementen. Dit is wat ik vond en hoe het zich verhoudt tot GPT-5.5 en Claude Opus 4.7.
TL;DR
Korte versie, voor de mensen die de tekst doornemen:
- Als je werk agentgestuurde - onderzoek in meerdere stappen, uit meerdere bronnen putten, grafieken en PDF's lezen... overschakelen naar 3.5 Flash. Het is op dit moment de beste in zijn klasse.
- Als je het schrijven van lange teksten of het analyseren van echte codebases, vasthouden aan Claude Opus 4.7.
- Als u grensverleggend redeneren (ARC-AGI-achtige puzzels, nieuwe onderzoeksproblemen), wachten op Gemini 3.5 Pro volgende maand.
- Als u een snel alledaags model, kiezen Gemini 3.5 Flash nu. Het levert ruwweg 4× de uitvoersnelheid van GPT-5.5 en Claude Opus 4.7.
Wil je het proberen? Gemini 3.5 Flash is live op GlobalGPT. Nieuwe accounts krijgen 3 gratis runs - geen creditcard nodig. Wat het platform nuttig maakt voor een vergelijking als deze is dat GPT-5.5, Claude Opus 4.7 en ~100 andere modellen in hetzelfde chatvenster staan. Eén abonnement, één interface, geen gegoochel.

Wat is Gemini 3.5 Flash?
Gemini 3.5 Flash is het eerste model in de nieuwe Gemini 3.5-familie, gelanceerd tijdens Google I/O op 19 mei 2026.. Gemini 3.5 Pro staat op de planning voor volgende maand, hoewel Google vaag was over de exacte datum.

Historisch gezien betekende “Flash” in Tweelingenland: sneller, goedkoper, minder slim. Deze release doorbreekt dat patroon. Het frame van Google is “Intelligentie op professioneel niveau met Flash-snelheid”.” wat een gewaagde bewering is van een leverancier. De gegevens bevestigen dit meestal.
Maak kennis met de Gemini 3.5-serie
De Gemini 3.5-familie vertegenwoordigt Google's volgende grote sprong voorwaarts op het gebied van kunstmatige intelligentie, door modellen te ontwikkelen die grensverleggende intelligentie combineren met bliksemsnelle uitvoering. De Gemini 3.5-familie is speciaal ontworpen om complexe, meerstaps agentgebaseerde workflows en geavanceerde software-engineering aan te sturen en is bedoeld om te handelen in plaats van alleen maar te reageren.

Belangrijkste modellen en functies
- Gemini 3.5 Flash: Het vlaggenschip op het gebied van snelheid en efficiëntie. Het levert state-of-the-art prestaties in codegeneratie, redeneren en verwerking van lange contexten (met ondersteuning voor een Contextvenster van 1 miljoen token), terwijl hij tot 4 keer sneller werkt dan vergelijkbare grensverleggende modellen. Hij blinkt uit in zware taken over langere perioden zonder gebruikers te dwingen om te kiezen tussen kwaliteit en snelheid.
- Gemini 3.5 Pro: Google's aankomende heavy-duty model (dat in eerste instantie intern wordt ingezet en nu breed wordt uitgerold), dat is afgestemd op maximale redeneerdiepte, massaal multimodaal begrip en de verwerking van zeer geavanceerde zakelijke workflows.
De focus op “agentgerichte” AI: In tegenstelling tot oudere statische LLM's is het Gemini 3.5 ecosysteem van nature geoptimaliseerd voor autonome agenten. Het gedijt op projecten met meerdere stappen, vibe codering, gegevensextractie en toolintegratie via de nieuwste ontwikkelaarsplatformen van Google.
Het specificatieblad van Gemini 3.5 Flash
| Gemini 3.5 Flash-functie | Specificatie |
|---|---|
| Verschijningsdatum | 19 mei 2026 (Google I/O) |
| Model familie | Gemini 3.5 (Flash-niveau) |
| Contextvenster | 1.048.576 tokens (~1M) |
| Max. uitvoer | 65.536 tokens |
| Invoermodaliteiten | Tekst, afbeelding, audio, video, PDF |
| Kennis cutoff | Januari 2026 |
| Uitvoersnelheid | ~4× sneller dan concurrerende vlaggenschepen |
| Het beste bij | Agent-workflows, multimodaal, codering, financieel redeneren |
Dat 1M contextvenster is belangrijker dan het hoofdnummer suggereert. De meeste topmodellen kunnen pas rond 128K ophalen. Flash kan aanzienlijk meer aan, wat enorm is voor een workflow met lange PDF's of gestoken onderzoek.
Benchmarks van Gemini 3.5 Flash: waar wint het, waar niet
Laten we beginnen met de overwinningen. In de door Google gepubliceerde benchmarktabel verslaat 3.5 Flash Gemini 3.1 Pro, Claude Opus 4.7 EN GPT-5.5 in vijf benchmarks tegelijk. Een kleiner model dat drie vlaggenschipconcurrenten tegelijk verslaat, is de afgelopen jaren niet voorgekomen.
Waar Gemini 3.5 Flash iedereen leidt
| Benchmark | Gemini 3.5 Flash | 3.1 Pro | Wat het test |
|---|---|---|---|
| MCP Atlas | 83.6% | 78.2% | Betrouwbaar gereedschap op schaal |
| Gereedschappenatlon | 56.5% | - | Multi-tool orkestratie |
| Financieel Agent v2 | 57.9% | 43.0% | Financiële redeneerders |
| CharXiv Redeneren | 84.2% | - | Grafieken en figuren begrijpen |
| MMMU-Pro | 83.6% | - | Multimodaal begrip |
| GDPval-AA (Elo) | 1656 | 1314 | Agent taken in de echte wereld |
| Terminal-Bench 2.1 | 76.2% | 70.3% | Terminal/CLI codering |
Cijfers zijn abstract, dus hier is iets concreets. Vorige week gaf ik het een opdracht: haal de laatste 10-Q's op van drie publieke SaaS-bedrijven, extraheer de brutomarge en S&M-uitgaven, maak een vergelijkingstabel, markeer de grootste YoY-veranderingen. 3.5 Flash heeft de stappen zelf gepland - de dossiers doorzoeken, de nummers parseren, de tabel genereren. Eén poging, ongeveer 90 seconden. Ik gaf dezelfde prompt aan Claude Opus 4.7 in het volgende tabblad en het haperde bij het tweede bedrijf, ik moest het aansporen met betere zoektermen voordat het vond wat het nodig had.
Die kloof - Flash op 83,6% op MCP Atlas tegenover de meeste concurrenten die rond de 70 hangen - wordt zo snel zichtbaar in het echte werk.
Waar Gemini 3.5 Flash nog steeds achterblijft bij 3.1 Pro
- Het laatste examen van de mensheid (grensredenering)
- ARC-AGI-2 (abstract redeneren)
- 128K MRCR v2 (ophalen van zeer lange contexten)
Dit zijn de moeilijkste zuivere intelligentie-benchmarks en 3.5 Flash verliest bij alle drie.
Het is briljant in het orkestreren van tools en het samenbrengen van informatie, maar het is niet het model voor nieuwe abstracte redeneringen. Dat verklaart ook waarom sommige ontwikkelaars nog steeds geven om Gemini 3.1 Pro codering prestaties: 3.1 Pro voelt misschien niet zo snel of agent-native als Flash, maar het blijft relevant in taken waar diepere redenering en lange-context betrouwbaarheid er meer toe doen dan snelheid. Google geeft het punt min of meer toe - 3.5 Pro komt volgende maand, en dat is waarschijnlijk waar ze de redeneerkloof dichten.
Twee weken bezig: wat de benchmarks niet vastleggen
Benchmarks vertellen je één verhaal. Dagelijks gebruik vertelt een ander verhaal. Dit is wat naast de cijfers opviel.
Wat het goed doet
- Tool calling is de kop. Ik voer regelmatig een onderzoeksworkflow uit waarbij het model moet zoeken, een paar URL's moet ophalen, de inhoud moet parsen, wat wiskunde moet doen en een gestructureerde uitvoer moet retourneren. Op GPT-5.5 slaagde die workflow misschien 80% van de tijd - mislukkingen waren meestal het model dat een stap oversloeg of het antwoord verzon als een zoekopdracht niet opleverde wat het wilde. Op Gemini 3.5 Flash is het succes bij de eerste poging meer dan 95%. Ik heb de hele workflow overgezet.
- Langlopende taken worden voltooid. Google beschrijft dit als “lange-horizontaken”, wat klinkt als een marketingtekst, maar het is niet verkeerd. Een taak van 6-8 stappen die 3.1 Pro soms halverwege zou laten vallen, wordt door Gemini 3.5 Flash van begin tot eind voltooid. Voor iedereen die productieworkflows beheert, is dat geen benchmark - het is het verschil tussen iets dat werkt en iets dat constant babysitting nodig heeft.
- De snelheid is echt. Bij interactief gebruik is het verschil tussen Flash en de langzamere vlaggenschepen duidelijk. Voor alles wat chatgebaseerd of iteratief is - opstellen, brainstormen, opties vergelijken - verandert het hoe bruikbaar het model aanvoelt.
Wat het niet goed doet
- Het schrijven in lange vorm is merkbaar zwakker dan bij Claude. Ik vroeg het om een marktanalyse van 5000 woorden. De structuur was prima; het proza was vlak. Claude Opus 4.7 schrijft met ritme - zinnen met verschillende lengtes, natuurlijk gevarieerde overgangen, het soort schrijven dat je niet opmerkt. Flash schrijft alsof iemand aan de opdrachtcriteria voldoet. Als je veel geschreven inhoud produceert voor publicatie, dan is Claude nog steeds het juiste gereedschap.
- Het aanpassen van echte codebases is waar het tekortschiet. Ik gaf het een open-source project en vroeg het een probleem te sluiten. Het zou de bug oplossen maar ergens anders een regressie introduceren. Opus 4.7 maakt die fout niet - dat is wat de SWE-bench Verified gap weergeeft. Blijf voor serieus ingenieurswerk voorlopig bij Claude.
- Niet-Engelse uitvoering: Ik heb voornamelijk in het Engels getest. De Chinese uitvoer is aanzienlijk beter dan de Gemini 3 generatie, maar nog steeds droger dan Claude Sonnet 4.6 op proza. Ik zou een grotere steekproef willen zien voordat ik er meer over zeg - ik wil het markeren voor iedereen die meertalige inhoud gebruikt.
Snelheid, prijzen en waarom dit er voor de meeste mensen toe doet
Google's snelheidsclaim is het deel dat me het meest verraste bij dagelijks gebruik. Gemini 3.5 Flash is ruwweg 4× sneller op output tokens dan concurrerende vlaggenschepen. In benchmarks is dat een getal. In het echte gebruik is het het verschil tussen “springt direct terug” en “blijft een tel hangen” - en die tel wordt groter als je 20-30 prompts doet in een middag.

In Kunstmatige analyse’ officiële benchmark voor uitvoersnelheid, Gemini 3.5 Flash rangen derde, achter GPT-OSS-120B en GPT-OSS-20B. Dit betekent dat GPT-OSS sneller is in ruwe output tokens per seconde, maar het betekent niet dat de snelheidsclaims van Gemini misleidend zijn.
- “Snel” heeft niet alleen te maken met de uitvoersnelheid; het hangt ook af van algehele latentie, multimodale verwerking, afhandeling van lange contexten, redeneerkwaliteit, stabiliteit en productiebetrouwbaarheid.
- GPT-OSS is uitstekend voor supersnelle tekstgeneratie met hoge doorvoer, terwijl Gemini 3.5 Flash balanceert hoge snelheid met bredere mogelijkheden zoals multimodale invoer, begrip van lange contexten en meer geavanceerde taakprestaties voor algemeen gebruik.

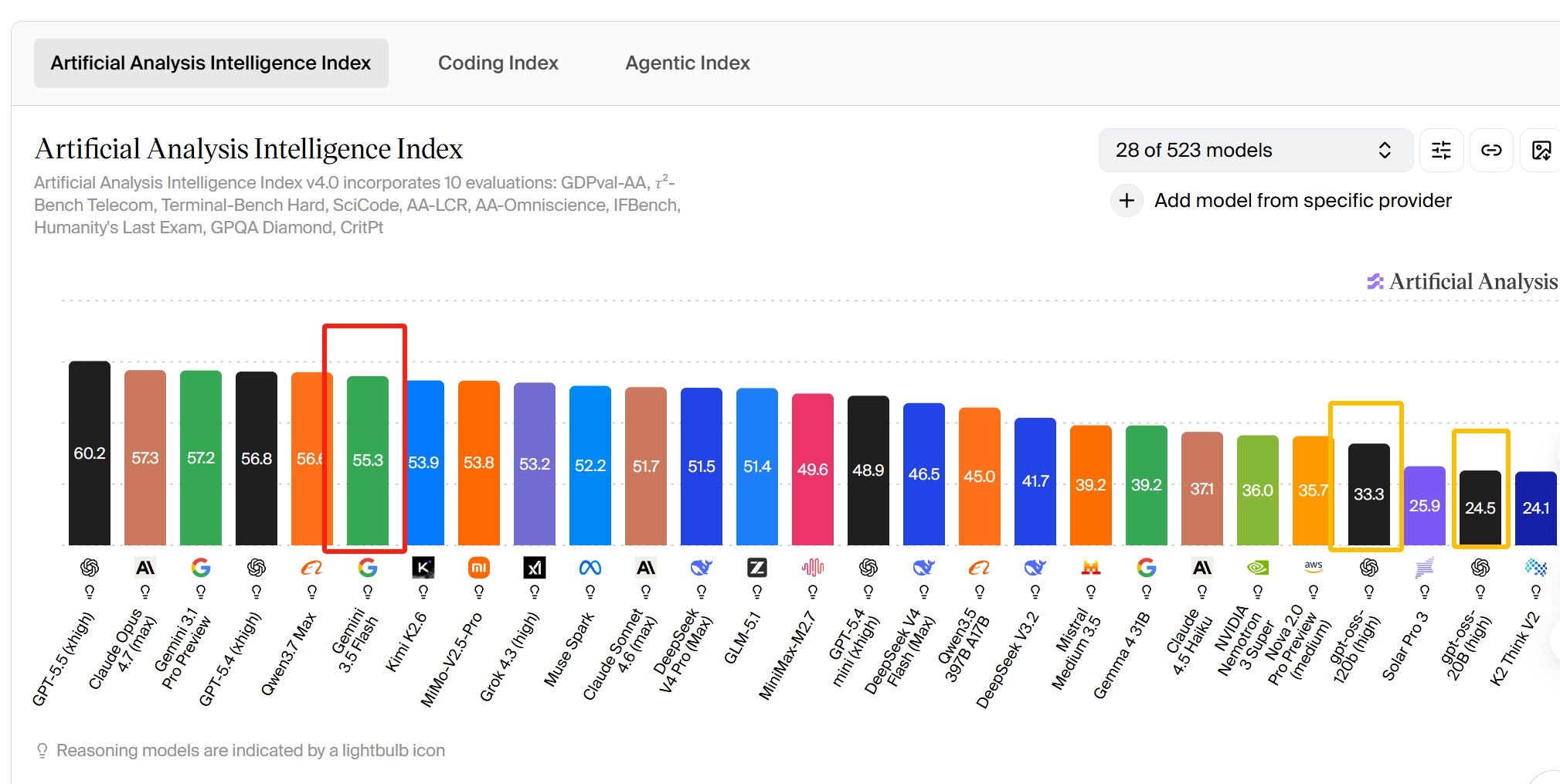
Voor de context zie je hier hoe de openbare API-prijzen zich verhouden tot de andere paradepaardjes van 2026 (dit is wat Google, Anthropic en OpenAI rechtstreeks via hun API's in rekening brengen):
| Model | Ingang ($/1M) | Uitgang ($/1M) | Opmerkingen |
|---|---|---|---|
| Gemini 3.5 Flash | $1.50 | $9.00 | Het onderwerp van dit artikel |
| Claude Opus 4.7 | $5.00 | $25.00 | Antropisch vlaggenschip |
| GPT-5,5 | $5.00 | $30.00 | OpenAI vlaggenschip |
| Claude Sonnet 4.6 | ~$3 | ~$15 | Antropische middenklasse |
| DeepSeek V4 Pro | Lager | Lager | Goedkoopste optie voor open gewichten |
Waarom dit van belang is, zelfs als u niet direct API-credits koopt: dit zijn de onderliggende economische factoren die bepalen tot welke modellen u daadwerkelijk toegang kunt krijgen en op welk niveau. ChatGPT Plus voor $20/maand dekt de GPT-familie. Claude Pro voor $20/maand dekt Claude. Gemini Advanced voor $20/maand dekt Gemini. Als je alle drie wilt plus Perplexity en een goed afbeeldingsmodel, zit je op $80+/maand voor vier abonnementen - en je schakelt tussen vier verschillende UI's elke keer dat je antwoorden wilt vergelijken.
Dat is het deel dat GlobalGPT oplost. Eén abonnement, allemaal in dezelfde chat. Je zult zien waarom ik daar steeds op terugkom in het gedeelte hieronder.
Gemini 3.5 Flash vs GPT-5.5 vs Claude Opus 4.7: wanneer gebruik je wat?
Dit is de vraag die ik het meest krijg. Hier is het spiekbriefje, gebaseerd op wat ik in twee weken van zij-aan-zij testen heb gezien:
| Type taak | Gebruik | Waarom |
|---|---|---|
| Onderzoek in meerdere stappen | Gemini 3.5 Flash | 83,6% MCP Atlas - beste freesgereedschap op de markt |
| Grafieken, figuren, video, PDF's | Gemini 3.5 Flash | CharXiv 84.2%, MMMU-Pro 83.6% - multimodaal is native en sterk |
| Schrijven in lange vorm (essays, verslagen) | Claude Opus 4.7 | Beter proza ritme en structuur |
| Software engineering op echte codebases | Claude Opus 4.7 | 87,6% SWE-bench Geverifieerd - nog steeds de standaard |
| Snelle codeertaken, scripts, CLI | Gemini 3.5 Flash | 76.2% Terminal-Bench, en snel genoeg om interactief te voelen |
| Ophalen van lange contexten (>128K) | Gemini 3.1 Pro | 3.1 Pro wint nog steeds op MRCR v2 voorbij 128K |
| Redeneren op grensniveau | Wacht op 3.5 Pro of gebruik 3.1 Pro | Flash verliest over het laatste examen van de mensheid en ARC-AGI-2 |
| Alles waar snelheid belangrijk is | Gemini 3.5 Flash | ~4× snellere uitvoer dan de andere vlaggenschepen |
Hier is een uitspraak die ik graag in de notulen wil opnemen: voor de meeste echte productieworkloads zou Gemini 3.5 Flash nu je standaard moeten zijn, met Opus 4.7 of GPT-5.5 als de uitzondering die je pakt als Flash niet genoeg is. Zes maanden geleden zou ik dat hebben omgedraaid - Pro-lagen waren de standaard, Flash was de budgetoptie. Gemini 3.5 Flash heeft de relatie omgekeerd.
Dat betekent niet dat Claude Opus 4.7 dood is. Het is nog steeds het model voor software engineering op echte codebases, en het schrijft beter proza. Maar als je werk voornamelijk bestaat uit zoeken, gestructureerde gegevens verzamelen, bronnen vergelijken en beslissingsklare output produceren... Flash is nu de betere tool.
Hoe kun je Gemini 3.5 Flash uitproberen?
Een paar paden, afhankelijk van wat je probeert te doen:
- Gemini-app of Zoekmodus AI. Gratis, vereist een Google-account. Prima voor casual prompts, maar geen manier om te vergelijken met andere modellen
- Gemini Advanced ($20/maand). Het consumentenabonnement van Google. Hiermee krijg je Gemini 3.5 Flash en Pro, maar je bent alleen gebonden aan de modellen van Google.
Er zijn echter aanzienlijke problemen met de twee methoden om Gemini 3.5 Flash te gebruiken, omdat Gemini heeft strikte regionale toegangsbeperkingen, waardoor het voor veel gebruikers moeilijk is om in te loggen of de service direct te gebruiken.

Daarom raad ik je een derde methode aan.
- GlobalGPT. Allemaal onder één abonnement, allemaal in hetzelfde chatvenster. Nieuwe aanmeldingen krijgen 3 gratis Gemini 3.5 Flash runs. Geen creditcard nodig om te beginnen.
- Gebruikers hebben toegang tot Gemini zonder een VPN op te zetten, terwijl ze ook een breed scala aan geavanceerde AI-modellen op één platform kunnen verkennen.
- Gemini 3.5 Flash staat naast GPT-5.5, Claude Opus 4.7, Claude Sonnet 4.6, GPT Image 2, Seedance 2.0 en ~100 andere modellen.
Die derde optie is eerlijk gezegd hoe ik de vergelijking voor dit artikel heb gedaan. Om dezelfde prompt in Gemini 3.5 Flash, GPT-5.5 en Claude Opus 4.7 op een andere manier uit te voeren, moet je je apart abonneren op Gemini Advanced ($20), ChatGPT Plus ($20) en Claude Pro ($20). $60/maand, drie aparte accounts, drie verschillende chatinterfaces en een copy-paste lus elke keer dat je antwoorden wilt vergelijken. In GlobalGPT is het een dropdown.
Dat is de waarde van alles-in-één platformen in het algemeen: ze vervangen de onderliggende modellen niet, ze besparen je alleen de wrijving om er toegang toe te krijgen. Als je maar één model gebruikt, is een abonnement bij één leverancier prima. Als je modellen met elkaar vergelijkt - of je wilt toegang tot het beste model voor elke taak - dan is een all-in-one abonnement prima. een aggregator betaalt zichzelf snel terug.
Probeer Gemini 3.5 Flash op GlobalGPT - 3 gratis generaties bij inschrijving. Plus GPT-5.5, Claude Opus 4.7 en 100+ modellen in dezelfde chat.

Conclusie: Moet je overstappen?
- Als je primaire werk bestaat uit onderzoek in meerdere stappen, multimodale analyse of een taak in agentstijl waarbij hulpmiddelen worden gebruikt - ja. Het is sneller, de benchmarks bevestigen het en twee weken echt testen hebben het bevestigd. Er is geen goede reden om op GPT-5.5 of Opus 4.7 te blijven voor dat soort werk.
- Als je primaire werk bestaat uit het schrijven van publicaties of codebase engineering, blijf dan bij Claude Opus 4.7.
- Als je primaire werk bestaat uit redeneren op onderzoeksniveau, wacht dan op Gemini 3.5 Pro volgende maand.
De snelste manier om dit te beslissen is door een handvol van de actuele prompts van de afgelopen week door alle drie de modellen te halen. Benchmarks zijn geaggregeerd. Uw workflow is de uwe.
De makkelijkste manier om die vergelijking te maken is op GlobalGPT - één abonnement, alle drie de modellen in dezelfde chat, plus 100 andere. Nieuwe accounts krijgen 3 gratis Gemini 3.5 Flash-generaties om mee te beginnen. Geen creditcard.
FAQ: Meer informatie over Gemini 3.5 Flash
Is Gemini 3.5 Flash beter dan Gemini 3.1 Pro?
Voor agentworkflows, coderingstaken, multimodale analyse en het gebruik van tools presteert Gemini 3.5 Flash beter dan Gemini 3.1 Pro in de meeste van de hierboven besproken benchmarks. Het is ook veel sneller in het dagelijks gebruik. Gemini 3.1 Pro heeft echter nog steeds een voorsprong bij een aantal moeilijkere redeneertaken en het ophalen van zeer lange contexten.
Wanneer is Gemini 3.5 Pro beschikbaar?
Gemini 3.5 Pro wordt naar verwachting volgende maand gelanceerd, maar Google heeft nog geen exacte releasedatum gegeven. Gebaseerd op de huidige positionering zal Gemini 3.5 Pro zich waarschijnlijk meer richten op grensverleggend redeneren, abstracte probleemoplossing en de moeilijkste onderzoeksachtige taken, terwijl Gemini 3.5 Flash al beschikbaar is voor snelle agentworkflows en multimodaal gebruik.
Wat is het verschil tussen Gemini Flash en Gemini Pro?
De Flash-serie is ontworpen voor snelheid, lagere kosten en hoogvolume praktische workflows. Deze serie is het meest geschikt voor onderzoek, gebruik van hulpmiddelen, multimodale analyse, snelle codeertaken en alledaags werk in agentstijl. De Pro serie wordt meestal gepositioneerd als de sterkere redeneerlaag, beter geschikt voor moeilijkere abstracte problemen, grensverleggend redeneren en complexere taken waarbij maximale intelligentie belangrijker is dan snelheid.

