Should You Upgrade to Claude Opus 4.7 for Coding, Research, or Long-Context Work?

The Ultimate Claude Opus 4.7 Survival Guide
Claude Opus 4.7 is a real upgrade, but it is not an automatic upgrade for every user. Anthropic released it on April 16, 2026, calls it its most capable generally available model, and kept the headline API price at $5 per million input tokens and $25 per million output tokens. It also brought a 1M-token context window, 128k max output, adaptive thinking support, and much stronger high-resolution vision. At the same time, Anthropic’s own docs warn that Opus 4.7 uses a new tokenizer that can raise token counts by up to roughly 35 percent on the same text, and API users need to account for migration changes rather than treating 4.7 as a drop-in swap. (Anthropic)
The practical answer is this: upgrade if your hardest work looks like multi-step coding, long-running agents, screenshot-heavy or document-heavy analysis, or research tasks where the model has to synthesize and self-check rather than merely summarize. Do not upgrade just because you saw “1M context” in a launch post, or because you assume “better model” automatically means “better research workflow.” In Claude’s ecosystem, the model, the plan, and the workflow features are three different decisions. Research is a plan feature. Projects and RAG expansion are workflow features. Opus 4.7 is the model. Those distinctions matter more than most launch-day comparisons admit. (Anthropic)
For many people, the more important question is not “Is Opus 4.7 better than Opus 4.6?” It is “What exactly am I trying to improve?” If the answer is “I need deeper coding help,” the upgrade case is strong. If the answer is “I need cited web research,” a paid Claude plan with Research may matter more than the Opus label. If the answer is “I work with giant files,” Opus 4.7 is not the only Claude model with a 1M window, so context size alone may not justify the jump. (Claude Platform)
The table below turns that into a simple decision framework. It reflects Anthropic’s pricing, model docs, Research docs, Projects docs, and migration guidance, plus GitHub’s current Copilot rollout. (Claude Platform)
Your main need | Is Opus 4.7 worth upgrading to | Why |
|---|---|---|
Heavy coding in real repositories | Usually yes | Anthropic positions 4.7 as a step-change improvement in agentic coding over 4.6, with new effort controls and stronger long-horizon execution |
Fast everyday coding and chat | Usually no | Sonnet 4.6 is faster, cheaper, and already has a 1M context window |
Research with citations and web grounding | Sometimes | Research is a paid-plan feature; the model helps, but the feature matters first |
Very large document sets | Sometimes | 4.7 helps, but Projects with RAG and compaction often matter as much as the model |
Casual writing and normal editing | Often no | The quality uplift is real, but the price and migration cost are harder to justify |
Pro user hitting limits constantly | Maybe upgrade plan, not just model | Max is about more capacity, higher output limits, and priority access more than a different category of work |
What actually changed in Claude Opus 4.7
Anthropic’s official release makes three points clear. First, Opus 4.7 is now the flagship generally available Claude model. Second, the company is positioning it around advanced software engineering, long-running tasks, professional knowledge work, and vision-heavy workflows rather than casual chat. Third, the launch is not just about intelligence. It also changes how the model behaves, how it counts tokens, and how developers have to configure requests. (Anthropic)
On paper, the headline improvements are easy to summarize. Opus 4.7 supports a 1M-token context window, up to 128k output tokens, adaptive thinking, and the same tool and platform surface as Opus 4.6. Anthropic also says it is stronger at long-horizon agentic work, knowledge work, vision tasks, and file-system-based memory. In the launch materials and model docs, Anthropic repeatedly frames 4.7 as more autonomous, more precise on instructions, and more reliable on multi-step work than 4.6. (Claude Platform)
The vision upgrade is more important than it sounds. Opus 4.7 is Anthropic’s first Claude model with high-resolution image support, increasing the maximum image resolution to 2576 pixels on the long edge, or about 3.75 megapixels, up from 1568 pixels and about 1.15 megapixels on prior models. Anthropic explicitly ties that change to screenshot understanding, dense documents, charts, diagrams, computer-use workflows, and coordinate-accurate image interaction. If you evaluate dashboards, inspect product screenshots, read scanned forms, or extract details from figures, this is not a cosmetic feature. It is one of the strongest real-world reasons to use 4.7 instead of older Opus variants. (Claude Platform)
The instruction-following change is equally significant. Anthropic’s API docs say Opus 4.7 is more literal, especially at lower effort levels. The official tutorial for Claude.ai makes the same point in more practical terms: one clear instruction is now enough, and old prompts that relied on the model loosely generalizing or “doing the obvious extra thing” may behave differently. For content creators and researchers, that usually means better compliance when you specify structure, evidence standards, and exclusions. For developers, it means old harnesses and prompt stacks may need retuning. (Claude Platform)
There is also a less glamorous but very important cost story. Anthropic kept the published API rate the same as Opus 4.6, but the tokenizer changed. The docs say Opus 4.7 may use roughly 1x to 1.35x as many tokens for the same text, depending on content type and workload shape. So the sticker price is unchanged, but the effective cost per task may go up. If your team measures model spend by completed work rather than by headline token price, you should treat Opus 4.7 as “same list price, potentially different bill.” That nuance matters a lot for long prompts, long contexts, and agentic loops. (Claude Platform)
Behavior changed too. Anthropic says Opus 4.7 makes fewer tool calls by default, leans more on reasoning, gives more direct and opinionated responses, and provides more regular progress updates during long agent traces. The official Claude.ai tutorial adds a practical implication: if you need the answer to come from the web, Slack, Drive, or another connector, you should say so directly. Left on its own, Opus 4.7 is less eager than 4.6 to reach for tools automatically. That is good for speed in some workflows, but it is a bad assumption if you need explicit grounding. (Claude Platform)
The most important distinction, model upgrade is not workflow upgrade
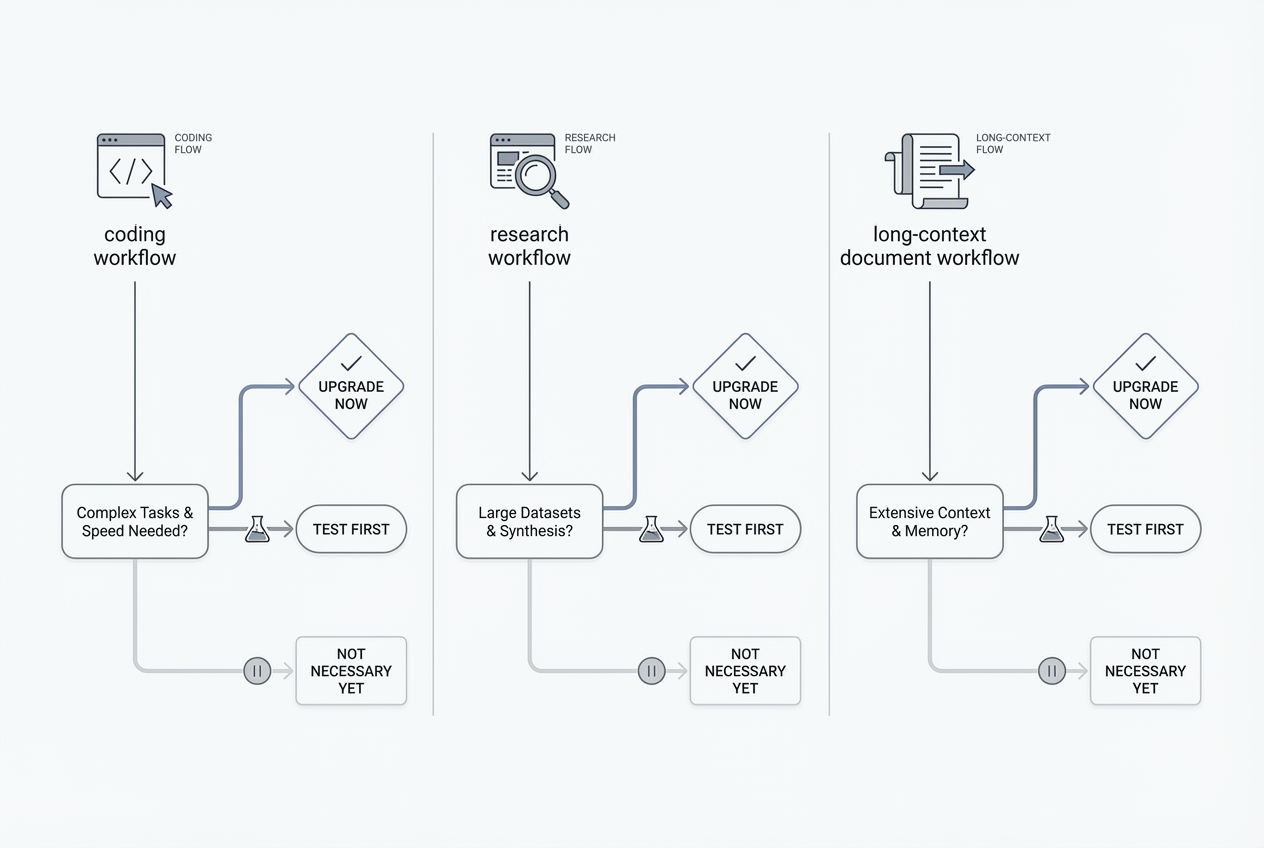
A lot of the confusion around Opus 4.7 comes from mixing up model quality with product features. Claude Research is not the same thing as Claude Opus 4.7. Anthropic’s help center describes Research as an agentic feature that performs multiple searches, explores different angles, and returns answers with citations. It is available to users on paid Claude plans, specifically Pro, Max, Team, and Enterprise, and it requires web search to be turned on. That means a user asking “Should I upgrade to Opus 4.7 for research?” may actually be asking a plan question, not a model question. (Claude Help Center)
The same is true for long document workflows. Projects are available across Claude, but Anthropic says enhanced project knowledge with RAG is available only on paid plans, and when your project knowledge approaches context limits, Claude can expand capacity by up to 10x through RAG while maintaining response quality. That is a very different mechanism from simply throwing everything into a single giant prompt. In practice, for researchers, teachers, analysts, and writers who live in collections of documents rather than one huge message, Projects plus RAG can matter as much as the Opus 4.7 upgrade itself. (Claude Help Center)
This is why blanket advice about “upgrading to the best model” is usually weak advice. Better research outcomes often come from a tighter workflow: explicit source instructions, Projects, Research, and the right file setup. Better long-context outcomes often come from compaction, RAG, and good task decomposition. Better coding outcomes often come from agent configuration and verification loops. Opus 4.7 improves all of those situations, but it does not replace them. (Claude API Docs)
Should you upgrade for coding
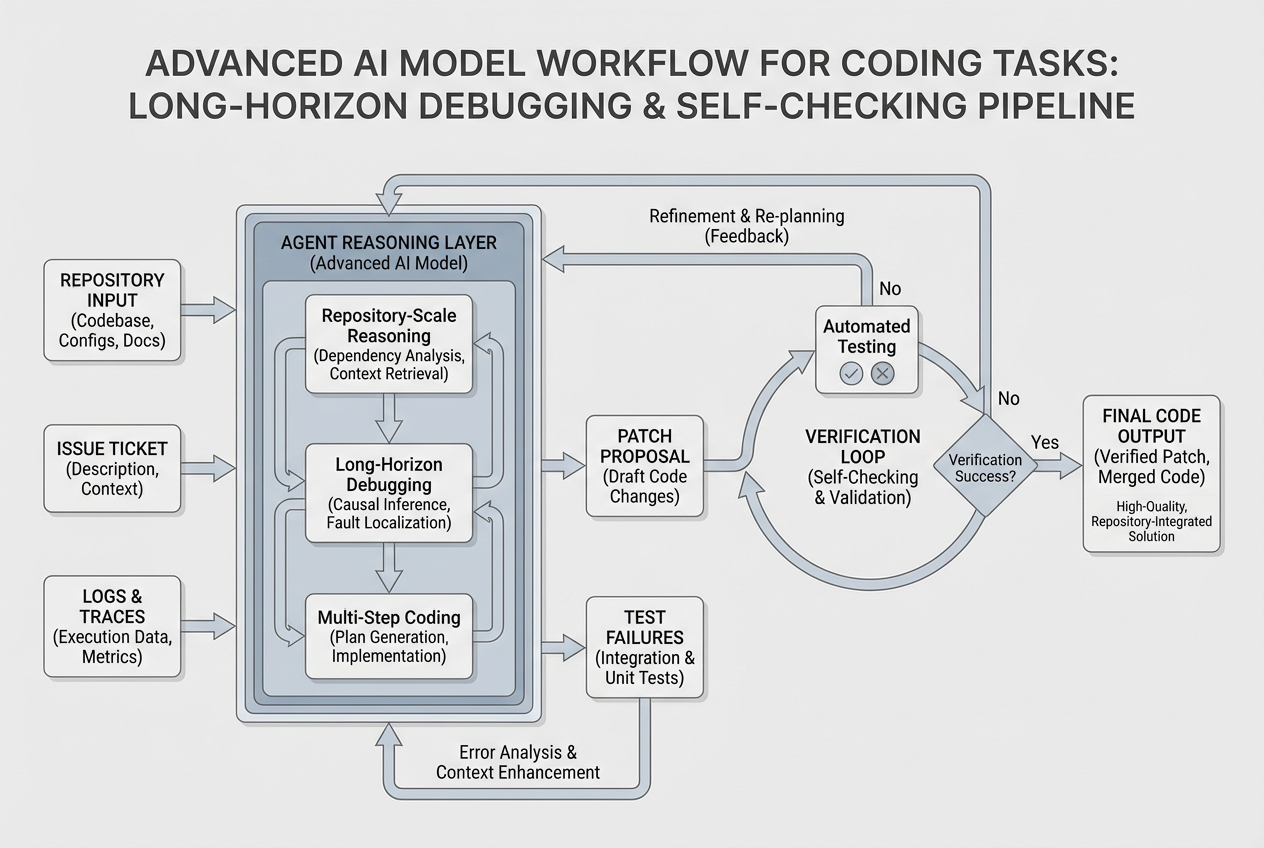
If coding is your main workload, the case for Opus 4.7 is strongest. Anthropic’s model overview says 4.7 is its most capable generally available model for complex reasoning and agentic coding, and explicitly calls it a step-change improvement over Opus 4.6 in agentic coding. The launch post goes further and frames 4.7 as notably better on advanced software engineering and difficult long-running tasks. Anthropic’s migration guide also recommends starting with the new xhigh effort level for coding and agentic use cases. (Claude Platform)
That does not mean every developer should rush to upgrade. The rational coding buyer splits into three groups. The first group lives in large codebases, async tasks, long debugging traces, agent loops, and tasks that need the model to plan, execute, self-check, recover, and keep going. Those users are exactly who Opus 4.7 is for. The second group mostly wants fast code generation, quick refactors, autocomplete-style help, or lightweight architecture suggestions. Those users may not get enough incremental value from 4.7 to justify the extra cost or latency, especially because Sonnet 4.6 already has a 1M context window, lower price, and faster latency. The third group is already paying for another coding surface, especially GitHub Copilot Business or Enterprise. For them, the smartest first move is usually to test 4.7 where they already work before adding another subscription layer. (Claude Platform)
The next table is a practical coding verdict. It combines Anthropic’s positioning and current access paths with a workload-based recommendation. The judgments in the right-most column are reasoned inferences based on those official sources. (Claude Platform)
Coding scenario | Stay put | Why | |
|---|---|---|---|
Small scripts, everyday debugging, quick edits | Often yes | Only if quality misses are expensive | Sonnet-class models are often enough and cheaper |
Large repository analysis | Rarely | Usually yes | Long-horizon reasoning and stronger agentic coding matter |
CI failures, logs, trace analysis, bug hunts | Sometimes | Usually yes | 4.7 is designed for deeper self-checking and multi-step diagnosis |
PR review and code quality work | Maybe | Usually yes | Better instruction following and more thorough review patterns help |
IDE chat only, team already on Copilot Business or Enterprise | Often | Test first inside Copilot | You may already have access once admins enable the policy |
One-off vibe coding for prototypes | Often | Sometimes | The gain is real, but not always worth premium cost or capacity |
Anthropic has also made access easier for coding users than many people realize. Claude Code is included in Pro, Max, and Team plans, and the Claude Code product page says Pro and Team users get access to both Sonnet 4.6 and Opus 4.7. That is a big deal because it means the step from “I want to test Opus 4.7 for coding” to “I need a $100 Max plan” is often unnecessary. Max is mostly about more capacity, higher output limits, early feature access, and priority at busy times, not about unlocking an entirely separate category of coding capability for every user. (Anthropic)
GitHub Copilot creates another path. GitHub’s April 16, 2026 changelog says Claude Opus 4.7 is rolling out to Copilot Pro+, Business, and Enterprise users. GitHub also says rollout is gradual and that Business and Enterprise admins must enable the Opus 4.7 policy. For teams that already standardized on Copilot, that makes Opus 4.7 more of an evaluation toggle than a separate procurement process. The catch is consumption: GitHub’s docs say Opus 4.7 currently carries a promotional 7.5x premium request multiplier through April 30, 2026, so heavy use can burn through premium requests quickly. (The GitHub Blog)
For developers using the API, the upgrade story is stronger on capability but rougher in implementation. Anthropic’s migration guide says manual extended thinking with thinking: {type: "enabled", budget_tokens: N} is no longer supported on Opus 4.7 and later models, and will return a 400 error. The current path is adaptive thinking with an effort level. Anthropic also says that on Opus 4.7, setting temperature, top_p, or top_k to non-default values returns a 400 error, and that thinking content is omitted by default unless you opt back in with summarized display. This is not the kind of change you discover after deploying on Friday afternoon. It is the kind you test carefully in staging. (Claude API Docs)
That API migration point is important enough to make concrete. Here is the old mental model and the new one:
# Older Opus-style pattern
thinking = {"type": "enabled", "budget_tokens": 32000}
temperature = 0.2
# Opus 4.7 pattern
thinking = {"type": "adaptive", "display": "summarized"}
effort = "xhigh"
# Omit temperature, top_p, and top_k if you do not want a 400 error
Anthropic also warns that Opus 4.7 may need more max_tokens headroom because of compaction triggers, adaptive thinking, and changed token counting. If your current integration barely fits under your output cap, 4.7 can break the workflow without any change to your prompt text. (Claude Platform)
For a real coding evaluation, a better prompt is not “Build me an app.” It is a bounded task that forces planning, verification, and error recovery. Something like this is far more revealing:
You are working inside a real codebase.
Task:
1. Read the failing test output and logs I attached.
2. Identify the most likely root cause.
3. Propose a minimal patch before editing anything.
4. List edge cases the patch could break.
5. Apply the patch.
6. Re-run the relevant checks mentally and explain what you would verify next.
7. If confidence is below 85 percent, say what extra evidence you need.
Constraints:
- Do not refactor unrelated files.
- Do not invent APIs or package behavior.
- Be explicit when a claim depends on an assumption.
- Prefer the smallest fix that resolves the actual bug.
That prompt takes advantage of what Opus 4.7 is supposed to do better: self-checking, literal instruction following, and long-horizon task discipline. It is also the kind of prompt where weaker “looks smart at first glance” models tend to fall apart. The upgrade is worth it when your daily work repeatedly looks like that. (Anthropic)
Should you upgrade for research
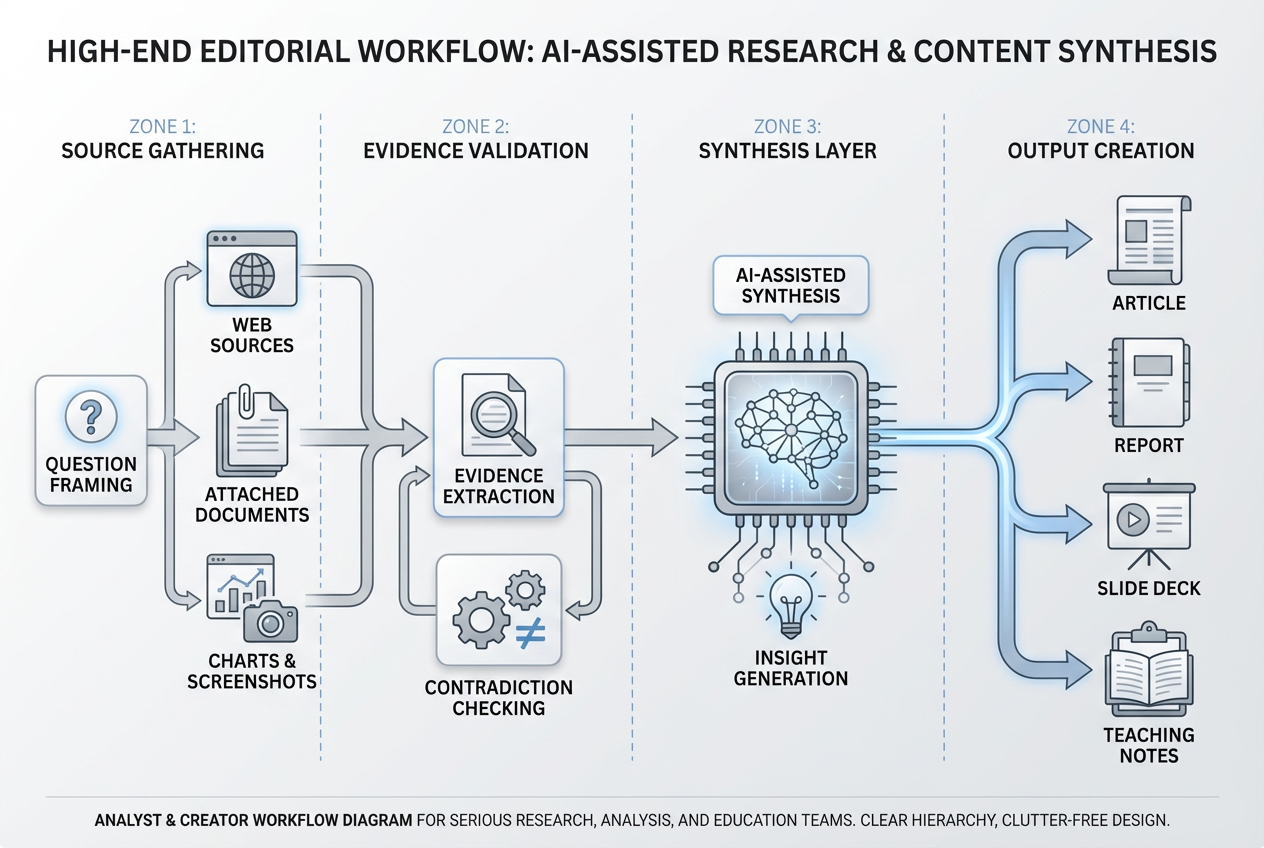
For research work, the answer is more nuanced. Anthropic’s Research feature is available to paid Claude plans and is designed to run agentic, multi-step searches that build on one another and return answers with citations. That makes Research a product-level capability, not simply a property of Opus 4.7. If your current problem is “I need up-to-date information with sources,” you do not solve that by only changing models. You solve it by making sure you are on a plan that has Research and by turning on web search. (Claude Help Center)
Where Opus 4.7 does matter is in the quality of the synthesis. Anthropic says 4.7 shows meaningful gains on knowledge-worker tasks, especially when the model needs to visually verify its own outputs. The docs specifically call out .docx redlining, .pptx editing, chart and figure analysis, and pixel-level transcription via image-processing libraries. In plain English, this means the upgrade is more valuable for “research that becomes deliverables” than for “research that ends as a chat answer.” If you write briefs, reports, investor memos, class materials, presentation decks, or evidence-backed articles, 4.7’s gains are more likely to show up in first-pass usefulness. (Claude Platform)
That is especially relevant to content creators and marketers. Many people say they need “better research” when they really need a system that can gather sources, compare claims, extract supporting details from screenshots and charts, and then turn that material into something publishable. Opus 4.7’s stronger vision, stricter instruction following, and better office-file quality fit that workflow better than a simpler “search then summarize” model. Anthropic’s own tutorial also says Opus 4.7 is more selective about using the web and connectors on its own, so source requests should be explicit. That means the best way to use it for research-heavy content is to define both the source behavior and the output behavior in the same prompt. (Claude Platform)
A practical research prompt for Opus 4.7 looks more like an assignment brief than a casual question:
Research this topic using web sources and any attached documents.
Deliverables:
1. A short factual answer first
2. A source-backed explanation with citations
3. A disagreement section that identifies where reputable sources diverge
4. A practical takeaway for a non-expert reader
5. A final checklist of facts that still need verification
Rules:
- Use current sources when the topic is time-sensitive
- Name assumptions clearly
- Do not smooth over disagreement between sources
- If a chart, image, or PDF page changes the conclusion, say so explicitly
This kind of prompt maps to Opus 4.7’s strengths. It also reduces one of the common research failure modes: the model giving a polished answer without showing where the uncertainty really lives. Anthropic’s own help and tutorial material repeatedly emphasize source grounding, explicit tool use, and cited outputs for Research workflows. (Claude Help Center)
The research upgrade becomes weaker when your task is shallow, repetitive, or more about retrieval than interpretation. If you mostly need a fast fact-check, a simple cited answer, or a quick collection of sources, Research on a paid Claude plan may matter more than Opus 4.7 specifically. Likewise, if your work depends on a structured knowledge base rather than the open web, Projects and connectors may contribute more to quality than moving from 4.6 to 4.7. That is why many buyers overpay for “the best model” while underinvesting in the features that actually shape research workflows. (Claude Help Center)
There is also a strong creator-side case for not making Opus 4.7 your only research answer. If your work spans drafting, comparison, image generation, presentation building, and publishing, a multi-model environment can sometimes be more rational than stacking separate single-vendor subscriptions. GlobalGPT’s current pricing page lists Claude Opus 4.7 among its available models, and its own comparison content is built around switching among models for different kinds of work rather than forcing one model to do everything. That is useful when your real job is not “use Claude better,” but “move from research to content to assets without opening five separate tools.” The tradeoff is that Anthropic-native features such as Research, Projects with RAG, and Claude Code plan entitlements still live inside Anthropic’s own stack. (glbgpt.com)
For teachers, students, and small teams, another underrated Opus 4.7 advantage is deliverable quality. Anthropic says file creation and code execution are available across Claude plans, and Opus 4.7 is specifically better at returning more complete office files on the first pass. That matters when your research result is supposed to become a PowerPoint deck, a spreadsheet, or a handout instead of one more chat transcript. The capability to create files is not unique to Opus 4.7, but the quality of the output can justify the model upgrade if office-file work is a repeated part of your workflow. (Claude Help Center)
Should you upgrade for long-context work
The long-context question is where most launch-day takes get simplistic. Yes, Opus 4.7 has a 1M-token context window. But so do Opus 4.6 and Sonnet 4.6. Anthropic’s model overview lists 1M tokens for Opus 4.7 and Sonnet 4.6, with Haiku 4.5 at 200k. The context-window docs also say Opus 4.7, Opus 4.6, and Sonnet 4.6 all have 1M-token windows. So if your entire reason for upgrading is “I need more than 200k,” the key question is not “Do I need Opus 4.7?” It is “Am I already on a 1M-token Claude model?” (Claude Platform)
That changes the economics of the decision. If you are coming from Sonnet 4.5, Opus 4.5, or another 200k-class model, moving to 4.7 may feel dramatic because the working memory ceiling is materially larger. But if you are already on Opus 4.6 or Sonnet 4.6, the long-context case for 4.7 is about quality, stability, and task discipline across the window, not about a larger number in the model card. Anthropic’s launch material and tutorial both emphasize that kind of gain: better long-running execution, stronger consistency, and better use of memory across multi-session work. (Anthropic)
Anthropic’s own context docs are also refreshingly honest about limits. A larger context window helps with long documents, codebases, and multi-turn tasks, but more context is not automatically better. The docs explicitly warn about context rot, where accuracy and recall degrade as token count grows. They also recommend server-side compaction for conversations that regularly approach context limits. In other words, 1M tokens is a real capability, but it is not magic. If you are asking a model to hold a messy, poorly structured corpus in memory forever, the better model will still struggle. (Claude Platform)
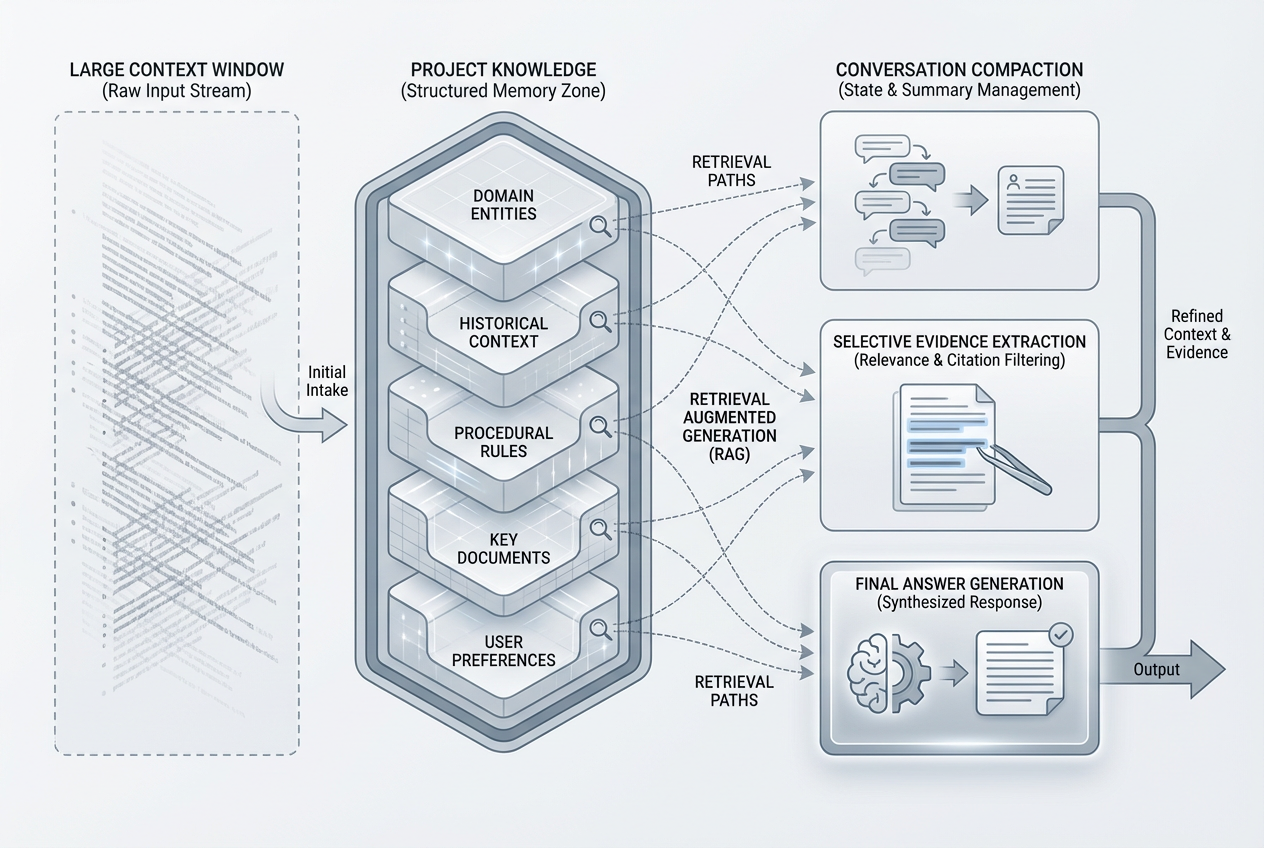
This is where workflow design starts to matter more than model marketing. Anthropic says compaction is available in beta for Opus 4.7, Opus 4.6, and Sonnet 4.6. Projects on paid plans can also expand knowledge capacity by up to 10x through RAG as the knowledge base approaches context limits. That means the best long-context workflow often looks like this: keep stable source material in Projects, use RAG when the corpus gets large, use compaction for long-running conversations, and then choose Opus 4.7 when the reasoning difficulty is high enough to justify it. (Claude API Docs)
The next table captures the main long-context scenarios and the upgrade logic behind each one. It is based on Anthropic’s context-window, Projects, and model-comparison docs. (Claude API Docs)
Long-context job | Best first move | Why |
|---|---|---|
Reading one very large document | Upgrade to any 1M Claude model if you are still on 200k | The bigger window is the real shift |
Multi-document research corpus | Use Projects and paid-plan RAG first | Corpus management matters as much as model class |
Long coding or agent traces | Better long-horizon execution and memory are the actual gain | |
Long chats that keep running out of room | Use compaction | Better than brute-force prompt stuffing |
Huge PDF or image batches | Use a 1M model and structure the task | Anthropic allows up to 600 images or PDF pages in one request on 1M models |
Need a cheaper 1M option | Consider Sonnet 4.6 first | Same context size, lower cost, faster latency |
That “600 images or PDF pages” number is worth pausing on. Anthropic’s context docs say a single request can include up to 600 images or PDF pages on 1M-context models, compared with 100 on 200k models. For anyone working in document review, visual auditing, legal packets, investor decks, or multi-part educational materials, that is operationally meaningful. But again, it is a reason to move into the 1M tier, not automatically a reason to choose Opus 4.7 over Sonnet 4.6 unless the reasoning itself is hard. (Claude API Docs)
A good long-context prompt on Opus 4.7 should also respect the model’s stronger literalness and its improved self-checking. Instead of dumping a giant corpus and asking for “everything important,” you get better results by making the retrieval target explicit:
You are analyzing a large set of attached materials.
Task:
1. Build a source map of the attached files first
2. Identify which sources are most relevant to the exact question
3. Extract only the evidence needed to answer it
4. Separate confirmed facts from assumptions
5. Flag contradictions across sources
6. End with a short answer and a confidence rating
Do not summarize all material equally.
Do not treat repeated claims as stronger evidence unless they trace back to independent sources.
That prompt forces the model to behave like an analyst instead of a very patient summarizer. On long-context work, that difference often matters more than raw model IQ. (Claude Platform)
The API and workflow gotchas that can erase the upgrade value
Many “upgrade reviews” ignore the small changes that quietly blow up production value. Opus 4.7 has several of them. Anthropic’s migration guide says adaptive thinking is now the required path for Opus 4.7, while the older budget_tokens style returns a 400 error. Anthropic’s docs also say non-default sampling parameters such as temperature, top_p, and top_k now cause 400 errors on Opus 4.7. If you have wrapper libraries, retry logic, or prompt infrastructure built around those assumptions, your upgrade project is larger than it first appears. (Claude API Docs)
The same is true for thinking visibility. On Opus 4.7, thinking content is omitted by default in the response unless you explicitly request summarized display. Anthropic says this improves latency slightly, but if your application depends on visible reasoning progress, or if your users interpret the pause before output as “the model is frozen,” this silent default change can look like a product regression unless you handle it proactively. (Claude Platform)
Another hidden cost is output. Anthropic says Opus 4.7 can think more at higher effort levels, especially in agentic settings, and that you may need more max_tokens headroom. That can improve reliability, but it also means more output tokens, more latency, and potentially higher bills. In practice, this is why you should not judge 4.7 by one clever answer. You should judge it by end-to-end task cost: total tokens, number of retries, editing time, and whether the model actually reduced human supervision. (Anthropic)
For non-developers, the equivalent gotcha is assuming the model will automatically do more source work just because it is better. Anthropic’s own Claude.ai tutorial says Opus 4.7 is more selective about using the web and connectors than Opus 4.6. If the answer needs grounding, say where the grounding should come from. If the task needs a file, upload the file. If it should search the web, ask for it. The quality ceiling is higher, but so is the cost of vague instructions. (Claude)
Pricing, access, and the real cost of upgrading
Anthropic’s current pricing structure makes one thing clear: “upgrade to Opus 4.7” can mean very different things depending on how you use Claude. On the API side, Opus 4.7 is priced at $5 per million input tokens and $25 per million output tokens, the same list price as Opus 4.6. Sonnet 4.6 is priced lower at $3 input and $15 output. Haiku 4.5 is lower still. On paper, then, moving from Sonnet 4.6 to Opus 4.7 is not just a model swap. It is a premium model choice with a real cost delta. (Claude Platform)
On the consumer plan side, Anthropic currently lists Pro at $20 per month or $200 per year, and Max from $100 per month, with 5x or 20x more usage than Pro, higher output limits, and priority access. That framing is important. Max is primarily a capacity upgrade. It is not best understood as “the plan where serious work begins.” Pro already includes Research, more model access, and Claude Code. For many individuals, the most expensive mistake is buying Max before proving that Pro is the actual bottleneck. (Anthropic)
Team pricing adds another useful distinction. Anthropic’s pricing page says Team Standard seats are $20 per seat per month if billed annually, or $25 monthly, while Premium seats are $100 annually billed per seat or $125 monthly. Anthropic’s Team help article says Standard seats offer 1.25x more usage per session than Pro, while Premium seats offer 6.25x more usage per session. So for teams, the right upgrade is often not “give everyone the most expensive seat.” It is “reserve Premium seats for the users who genuinely need long-running Opus-class work.” (Anthropic)
Enterprise is different again. Anthropic’s Enterprise help article says the seat fee covers access only, and usage is billed separately at API rates. Anthropic also states plainly that Claude paid plans and the Claude Console are separate products, so a Pro, Max, Team, or Enterprise subscription does not include API usage. This catches a lot of buyers off guard. If you need both a polished chat experience and production API access, you are budgeting for two related but separate systems. (Claude Help Center)
GitHub Copilot complicates the picture in a useful way. GitHub’s plan docs list Copilot Pro+ at $39 per month, Business at $19 per granted seat per month, and Enterprise at $39 per granted seat per month. Those same docs say Claude Opus 4.7 is available in chat for Pro+, Business, and Enterprise. If your engineering team already lives inside Copilot, the incremental cost of evaluating Opus 4.7 may be much smaller than buying parallel Anthropic seats. But for individuals, the Anthropic Pro plan can still be the cleaner value if you also care about Research, Projects, and Claude-native workflows outside the IDE. (GitHub Docs)
For users who routinely bounce between Claude, GPT, Gemini, research tools, image tools, and video tools, the budget question often shifts again. GlobalGPT’s current model and pricing pages list Claude Opus 4.7 among its available models, while the platform’s own comparison content is organized around using different models for different jobs. That can make more sense than carrying several separate subscriptions if your workload is genuinely cross-model and cross-media. But if you need Anthropic-specific capabilities such as Research inside Claude, Projects with Claude’s RAG behavior, or Claude Code access rules, those remain official-product decisions first. (glbgpt.com)
How to test whether Opus 4.7 is worth it before you commit
The best way to decide is not to read one more benchmark roundup. It is to run three real tasks through your current setup and through Opus 4.7, then score the result on quality, time to acceptable output, number of follow-up fixes, and actual cost. Anthropic’s own materials encourage retuning and re-baselining prompts because 4.7 is more literal, more selective about tool use, and behaves differently in effort and token usage. That means old prompts can make the new model look worse than it is. (Claude Platform)
A good coding test is a real bug or repo task, not a toy benchmark. A good research test is a question with source disagreement and at least one visual element, such as a chart or PDF page. A good long-context test is a corpus where the correct answer requires selective retrieval rather than broad summarization. If Opus 4.7 saves you a prompt round, a debugging round, or a human correction round, that is value. If it only gives you a slightly prettier draft at noticeably higher cost, the upgrade case is weak. (Anthropic)
You should also separate model value from plan value. If your Pro account already handles your daily workload, the relevant experiment may be “Opus 4.7 within Pro or Team Standard” rather than “Should I pay for Max.” If your team already has Copilot Business or Enterprise, the relevant experiment may be “Opus 4.7 inside Copilot” rather than “Should we buy Anthropic seats.” And if your actual work crosses writing, analysis, and media production, the relevant experiment may be “single-vendor subscription versus multi-model workspace,” not “Opus 4.6 versus 4.7.” (Anthropic)
The simplest decision rule is this. Upgrade to Opus 4.7 when failure is expensive, supervision is costly, and the task has enough complexity that a more capable model can remove real friction. Stay on a cheaper model or lower plan when your workflow is short, shallow, or mostly retrieval-oriented. And upgrade your workflow before your model when the problem is poor source control, weak prompt structure, or missing project organization. (Claude Platform)
The bottom line
Claude Opus 4.7 is not hype-only. It is a meaningful upgrade for the people Anthropic is clearly targeting: heavy coding users, long-running agents, document and slide workers, and research-heavy professionals who need more than a fluent answer. The best evidence for upgrading is not that Anthropic says it is better. It is that the specific improvements line up with expensive failure modes in real work: brittle agent loops, weak screenshot understanding, sloppy office-file outputs, and incomplete multi-step reasoning. (Anthropic)
It is not the right move for everyone. If you want better web-grounded research, make sure you actually have Claude Research first. If you want more room for giant files, remember that Sonnet 4.6 already has a 1M context window. If you are thinking about Max, make sure the issue is capacity, not capability confusion. And if you use several top models every week, compare the cost of a single-vendor upgrade against the cost of a multi-model workflow instead of assuming the “best single model” is always the best buying decision. (Claude Help Center)
The cleanest summary is this: upgrade to Opus 4.7 for hard work, not for status. If your hardest tasks are truly the bottleneck, it is one of the best reasons to upgrade inside Claude right now. If they are not, your better move may be a cheaper Claude model, a better plan fit, or a better workflow design. (Claude Platform)
Further reading and reference material
Anthropic, Introducing Claude Opus 4.7. (Anthropic)
Anthropic Claude API Docs, What’s new in Claude Opus 4.7. (Claude Platform)
Anthropic Claude API Docs, Models overview and pricing. (Claude Platform)
Anthropic Claude API Docs, Migration guide and context windows. (Claude API Docs)
Claude Help Center, Using Research on Claude and What are Projects. (Claude Help Center)
Claude pricing, Claude Code, Team, and Enterprise references. (Anthropic)
GitHub Copilot, Claude Opus 4.7 availability and plan documentation. (The GitHub Blog)
GlobalGPT, Claude Opus 4.7 availability, model comparisons, and related workflows. (glbgpt.com)